 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCE-SLAM: Scale-Consistent Monocular SLAM via Scene Coordinate Embeddings
Jan 14, 2026Monocular visual SLAM enables 3D reconstruction from internet video and autonomous navigation on resource-constrained platforms, yet suffers from scale drift, i.e., the gradual divergence of estimated scale over long sequences. Existing frame-to-frame methods achieve real-time performance through local optimization but accumulate scale drift due to the lack of global constraints among independent windows. To address this, we propose SCE-SLAM, an end-to-end SLAM system that maintains scale consistency through scene coordinate embeddings, which are learned patch-level representations encoding 3D geometric relationships under a canonical scale reference. The framework consists of two key modules: geometry-guided aggregation that leverages 3D spatial proximity to propagate scale information from historical observations through geometry-modulated attention, and scene coordinate bundle adjustment that anchors current estimates to the reference scale through explicit 3D coordinate constraints decoded from the scene coordinate embeddings. Experiments on KITTI, Waymo, and vKITTI demonstrate substantial improvements: our method reduces absolute trajectory error by 8.36m on KITTI compared to the best prior approach, while maintaining 36 FPS and achieving scale consistency across large-scale scenes.
QE-Catalytic: A Graph-Language Multimodal Base Model for Relaxed-Energy Prediction in Catalytic Adsorption
Dec 23, 2025Adsorption energy is a key descriptor of catalytic reactivity. It is fundamentally defined as the difference between the relaxed total energy of the adsorbate-surface system and that of an appropriate reference state; therefore, the accuracy of relaxed-energy prediction directly determines the reliability of machine-learning-driven catalyst screening. E(3)-equivariant graph neural networks (GNNs) can natively operate on three-dimensional atomic coordinates under periodic boundary conditions and have demonstrated strong performance on such tasks. In contrast, language-model-based approaches, while enabling human-readable textual descriptions and reducing reliance on explicit graph -- thereby broadening applicability -- remain insufficient in both adsorption-configuration energy prediction accuracy and in distinguishing ``the same system with different configurations,'' even with graph-assisted pretraining in the style of GAP-CATBERTa. To this end, we propose QE-Catalytic, a multimodal framework that deeply couples a large language model (\textbf{Q}wen) with an E(3)-equivariant graph Transformer (\textbf{E}quiformer-V2), enabling unified support for adsorption-configuration property prediction and inverse design on complex catalytic surfaces. During prediction, QE-Catalytic jointly leverages three-dimensional structures and structured configuration text, and injects ``3D geometric information'' into the language channel via graph-text alignment, allowing it to function as a high-performance text-based predictor when precise coordinates are unavailable, while also autoregressively generating CIF files for target-energy-driven structure design and information completion. On OC20, QE-Catalytic reduces the MAE of relaxed adsorption energy from 0.713~eV to 0.486~eV, and consistently outperforms baseline models such as CatBERTa and GAP-CATBERTa across multiple evaluation protocols.
Large-scale Regional Traffic Signal Control Based on Single-Agent Reinforcement Learning
Mar 12, 2025


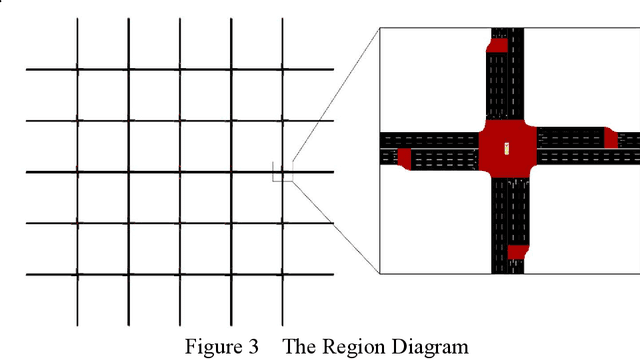
In the context of global urbanization and motorization, traffic congestion has become a significant issue, severely affecting the quality of life, environment, and economy. This paper puts forward a single-agent reinforcement learning (RL)-based regional traffic signal control (TSC) model. Different from multi - agent systems, this model can coordinate traffic signals across a large area, with the goals of alleviating regional traffic congestion and minimizing the total travel time. The TSC environment is precisely defined through specific state space, action space, and reward functions. The state space consists of the current congestion state, which is represented by the queue lengths of each link, and the current signal phase scheme of intersections. The action space is designed to select an intersection first and then adjust its phase split. Two reward functions are meticulously crafted. One focuses on alleviating congestion and the other aims to minimize the total travel time while considering the congestion level. The experiments are carried out with the SUMO traffic simulation software. The performance of the TSC model is evaluated by comparing it with a base case where no signal-timing adjustments are made. The results show that the model can effectively control congestion. For example, the queuing length is significantly reduced in the scenarios tested. Moreover, when the reward is set to both alleviate congestion and minimize the total travel time, the average travel time is remarkably decreased, which indicates that the model can effectively improve traffic conditions. This research provides a new approach for large-scale regional traffic signal control and offers valuable insights for future urban traffic management.
DreamerV3 for Traffic Signal Control: Hyperparameter Tuning and Performance
Mar 04, 2025



Reinforcement learning (RL) has evolved into a widely investigated technology for the development of smart TSC strategies. However, current RL algorithms necessitate excessive interaction with the environment to learn effective policies, making them impractical for large-scale tasks. The DreamerV3 algorithm presents compelling properties for policy learning. It summarizes general dynamics knowledge about the environment and enables the prediction of future outcomes of potential actions from past experience, reducing the interaction with the environment through imagination training. In this paper, a corridor TSC model is trained using the DreamerV3 algorithm to explore the benefits of world models for TSC strategy learning. In RL environment design, to manage congestion levels effectively, both the state and reward functions are defined based on queue length, and the action is designed to manage queue length efficiently. Using the SUMO simulation platform, the two hyperparameters (training ratio and model size) of the DreamerV3 algorithm were tuned and analyzed across different OD matrix scenarios. We discovered that choosing a smaller model size and initially attempting several medium training ratios can significantly reduce the time spent on hyperparameter tuning. Additionally, we found that the approach is generally applicable as it can solve two TSC task scenarios with the same hyperparameters. Regarding the claimed data-efficiency of the DreamerV3 algorithm, due to the significant fluctuation of the episode reward curve in the early stages of training, it can only be confirmed that larger model sizes exhibit modest data-efficiency, and no evidence was found that increasing the training ratio accelerates convergence.
Operator Feature Neural Network for Symbolic Regression
Aug 14, 2024Symbolic regression is a task aimed at identifying patterns in data and representing them through mathematical expressions, generally involving skeleton prediction and constant optimization. Many methods have achieved some success, however they treat variables and symbols merely as characters of natural language without considering their mathematical essence. This paper introduces the operator feature neural network (OF-Net) which employs operator representation for expressions and proposes an implicit feature encoding method for the intrinsic mathematical operational logic of operators. By substituting operator features for numeric loss, we can predict the combination of operators of target expressions. We evaluate the model on public datasets, and the results demonstrate that the model achieves superior recovery rates and high $R^2$ scores. With the discussion of the results, we analyze the merit and demerit of OF-Net and propose optimizing schemes.
DN-CL: Deep Symbolic Regression against Noise via Contrastive Learning
Jun 21, 2024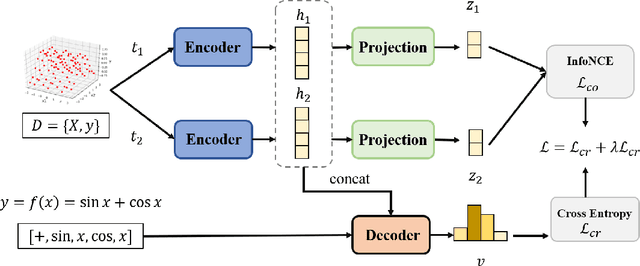

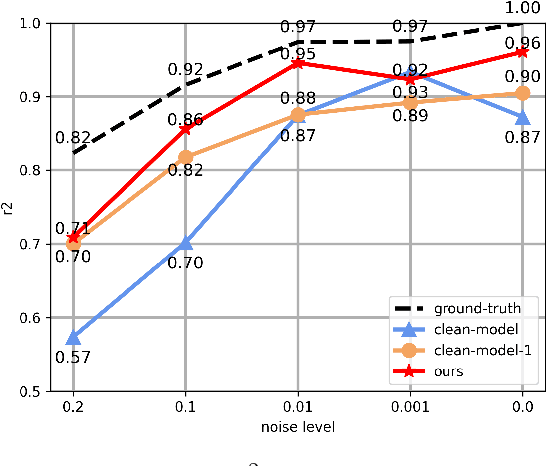
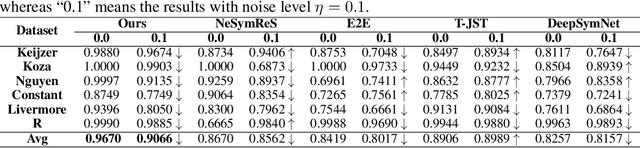
Noise ubiquitously exists in signals due to numerous factors including physical, electronic, and environmental effects. Traditional methods of symbolic regression, such as genetic programming or deep learning models, aim to find the most fitting expressions for these signals. However, these methods often overlook the noise present in real-world data, leading to reduced fitting accuracy. To tackle this issue, we propose \textit{\textbf{D}eep Symbolic Regression against \textbf{N}oise via \textbf{C}ontrastive \textbf{L}earning (DN-CL)}. DN-CL employs two parameter-sharing encoders to embed data points from various data transformations into feature shields against noise. This model treats noisy data and clean data as different views of the ground-truth mathematical expressions. Distances between these features are minimized, utilizing contrastive learning to distinguish between 'positive' noise-corrected pairs and 'negative' contrasting pairs. Our experiments indicate that DN-CL demonstrates superior performance in handling both noisy and clean data, presenting a promising method of symbolic regression.
MLLM-SR: Conversational Symbolic Regression base Multi-Modal Large Language Models
Jun 08, 2024



Formulas are the language of communication between humans and nature. It is an important research topic of artificial intelligence to find expressions from observed data to reflect the relationship between each variable in the data, which is called a symbolic regression problem. The existing symbolic regression methods directly generate expressions according to the given observation data, and we cannot require the algorithm to generate expressions that meet specific requirements according to the known prior knowledge. For example, the expression needs to contain $\sin$ or be symmetric, and so on. Even if it can, it often requires very complex operations, which is very inconvenient. In this paper, based on multi-modal large language models, we propose MLLM-SR, a conversational symbolic regression method that can generate expressions that meet the requirements simply by describing the requirements with natural language instructions. By experimenting on the Nguyen dataset, we can demonstrate that MLLM-SR leads the state-of-the-art baselines in fitting performance. More notably, we experimentally demonstrate that MLLM-SR can well understand the prior knowledge we add to the natural language instructions. Moreover, the addition of prior knowledge can effectively guide MLLM-SR to generate correct expressions.
Closed-form Symbolic Solutions: A New Perspective on Solving Partial Differential Equations
May 23, 2024Solving partial differential equations (PDEs) in Euclidean space with closed-form symbolic solutions has long been a dream for mathematicians. Inspired by deep learning, Physics-Informed Neural Networks (PINNs) have shown great promise in numerically solving PDEs. However, since PINNs essentially approximate solutions within the continuous function space, their numerical solutions fall short in both precision and interpretability compared to symbolic solutions. This paper proposes a novel framework: a closed-form \textbf{Sym}bolic framework for \textbf{PDE}s (SymPDE), exploring the use of deep reinforcement learning to directly obtain symbolic solutions for PDEs. SymPDE alleviates the challenges PINNs face in fitting high-frequency and steeply changing functions. To our knowledge, no prior work has implemented this approach. Experiments on solving the Poisson's equation and heat equation in time-independent and spatiotemporal dynamical systems respectively demonstrate that SymPDE can provide accurate closed-form symbolic solutions for various types of PDEs.
Generative Pre-Trained Transformer for Symbolic Regression Base In-Context Reinforcement Learning
Apr 09, 2024



The mathematical formula is the human language to describe nature and is the essence of scientific research. Finding mathematical formulas from observational data is a major demand of scientific research and a major challenge of artificial intelligence. This area is called symbolic regression. Originally symbolic regression was often formulated as a combinatorial optimization problem and solved using GP or reinforcement learning algorithms. These two kinds of algorithms have strong noise robustness ability and good Versatility. However, inference time usually takes a long time, so the search efficiency is relatively low. Later, based on large-scale pre-training data proposed, such methods use a large number of synthetic data points and expression pairs to train a Generative Pre-Trained Transformer(GPT). Then this GPT can only need to perform one forward propagation to obtain the results, the advantage is that the inference speed is very fast. However, its performance is very dependent on the training data and performs poorly on data outside the training set, which leads to poor noise robustness and Versatility of such methods. So, can we combine the advantages of the above two categories of SR algorithms? In this paper, we propose \textbf{FormulaGPT}, which trains a GPT using massive sparse reward learning histories of reinforcement learning-based SR algorithms as training data. After training, the SR algorithm based on reinforcement learning is distilled into a Transformer. When new test data comes, FormulaGPT can directly generate a "reinforcement learning process" and automatically update the learning policy in context. Tested on more than ten datasets including SRBench, formulaGPT achieves the state-of-the-art performance in fitting ability compared with four baselines. In addition, it achieves satisfactory results in noise robustness, versatility, and inference efficiency.
MMSR: Symbolic Regression is a Multimodal Task
Mar 14, 2024Mathematical formulas are the crystallization of human wisdom in exploring the laws of nature for thousands of years. Describing the complex laws of nature with a concise mathematical formula is a constant pursuit of scientists and a great challenge for artificial intelligence. This field is called symbolic regression. Symbolic regression was originally formulated as a combinatorial optimization problem, and GP and reinforcement learning algorithms were used to solve it. However, GP is sensitive to hyperparameters, and these two types of algorithms are inefficient. To solve this problem, researchers treat the mapping from data to expressions as a translation problem. And the corresponding large-scale pre-trained model is introduced. However, the data and expression skeletons do not have very clear word correspondences as the two languages do. Instead, they are more like two modalities (e.g., image and text). Therefore, in this paper, we proposed MMSR. The SR problem is solved as a pure multimodal problem, and contrastive learning is also introduced in the training process for modal alignment to facilitate later modal feature fusion. It is worth noting that in order to better promote the modal feature fusion, we adopt the strategy of training contrastive learning loss and other losses at the same time, which only needs one-step training, instead of training contrastive learning loss first and then training other losses. Because our experiments prove training together can make the feature extraction module and feature fusion module running-in better. Experimental results show that compared with multiple large-scale pre-training baselines, MMSR achieves the most advanced results on multiple mainstream datasets including SRBench.