 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDN-CL: Deep Symbolic Regression against Noise via Contrastive Learning
Jun 21, 2024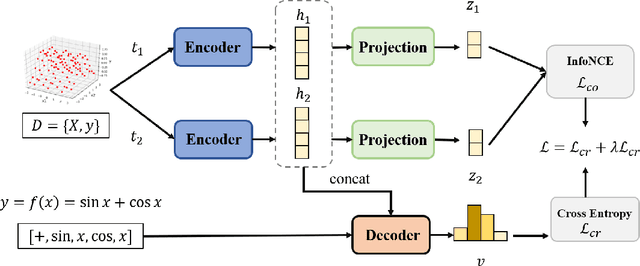

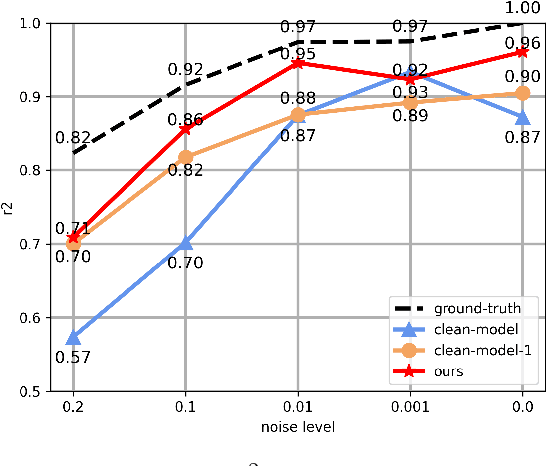
Noise ubiquitously exists in signals due to numerous factors including physical, electronic, and environmental effects. Traditional methods of symbolic regression, such as genetic programming or deep learning models, aim to find the most fitting expressions for these signals. However, these methods often overlook the noise present in real-world data, leading to reduced fitting accuracy. To tackle this issue, we propose \textit{\textbf{D}eep Symbolic Regression against \textbf{N}oise via \textbf{C}ontrastive \textbf{L}earning (DN-CL)}. DN-CL employs two parameter-sharing encoders to embed data points from various data transformations into feature shields against noise. This model treats noisy data and clean data as different views of the ground-truth mathematical expressions. Distances between these features are minimized, utilizing contrastive learning to distinguish between 'positive' noise-corrected pairs and 'negative' contrasting pairs. Our experiments indicate that DN-CL demonstrates superior performance in handling both noisy and clean data, presenting a promising method of symbolic regression.
Closed-form Symbolic Solutions: A New Perspective on Solving Partial Differential Equations
May 23, 2024Solving partial differential equations (PDEs) in Euclidean space with closed-form symbolic solutions has long been a dream for mathematicians. Inspired by deep learning, Physics-Informed Neural Networks (PINNs) have shown great promise in numerically solving PDEs. However, since PINNs essentially approximate solutions within the continuous function space, their numerical solutions fall short in both precision and interpretability compared to symbolic solutions. This paper proposes a novel framework: a closed-form \textbf{Sym}bolic framework for \textbf{PDE}s (SymPDE), exploring the use of deep reinforcement learning to directly obtain symbolic solutions for PDEs. SymPDE alleviates the challenges PINNs face in fitting high-frequency and steeply changing functions. To our knowledge, no prior work has implemented this approach. Experiments on solving the Poisson's equation and heat equation in time-independent and spatiotemporal dynamical systems respectively demonstrate that SymPDE can provide accurate closed-form symbolic solutions for various types of PDEs.
Generative Pre-Trained Transformer for Symbolic Regression Base In-Context Reinforcement Learning
Apr 09, 2024



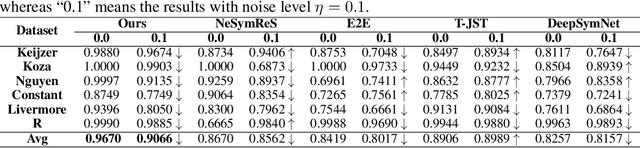
The mathematical formula is the human language to describe nature and is the essence of scientific research. Finding mathematical formulas from observational data is a major demand of scientific research and a major challenge of artificial intelligence. This area is called symbolic regression. Originally symbolic regression was often formulated as a combinatorial optimization problem and solved using GP or reinforcement learning algorithms. These two kinds of algorithms have strong noise robustness ability and good Versatility. However, inference time usually takes a long time, so the search efficiency is relatively low. Later, based on large-scale pre-training data proposed, such methods use a large number of synthetic data points and expression pairs to train a Generative Pre-Trained Transformer(GPT). Then this GPT can only need to perform one forward propagation to obtain the results, the advantage is that the inference speed is very fast. However, its performance is very dependent on the training data and performs poorly on data outside the training set, which leads to poor noise robustness and Versatility of such methods. So, can we combine the advantages of the above two categories of SR algorithms? In this paper, we propose \textbf{FormulaGPT}, which trains a GPT using massive sparse reward learning histories of reinforcement learning-based SR algorithms as training data. After training, the SR algorithm based on reinforcement learning is distilled into a Transformer. When new test data comes, FormulaGPT can directly generate a "reinforcement learning process" and automatically update the learning policy in context. Tested on more than ten datasets including SRBench, formulaGPT achieves the state-of-the-art performance in fitting ability compared with four baselines. In addition, it achieves satisfactory results in noise robustness, versatility, and inference efficiency.
MMSR: Symbolic Regression is a Multimodal Task
Mar 14, 2024Mathematical formulas are the crystallization of human wisdom in exploring the laws of nature for thousands of years. Describing the complex laws of nature with a concise mathematical formula is a constant pursuit of scientists and a great challenge for artificial intelligence. This field is called symbolic regression. Symbolic regression was originally formulated as a combinatorial optimization problem, and GP and reinforcement learning algorithms were used to solve it. However, GP is sensitive to hyperparameters, and these two types of algorithms are inefficient. To solve this problem, researchers treat the mapping from data to expressions as a translation problem. And the corresponding large-scale pre-trained model is introduced. However, the data and expression skeletons do not have very clear word correspondences as the two languages do. Instead, they are more like two modalities (e.g., image and text). Therefore, in this paper, we proposed MMSR. The SR problem is solved as a pure multimodal problem, and contrastive learning is also introduced in the training process for modal alignment to facilitate later modal feature fusion. It is worth noting that in order to better promote the modal feature fusion, we adopt the strategy of training contrastive learning loss and other losses at the same time, which only needs one-step training, instead of training contrastive learning loss first and then training other losses. Because our experiments prove training together can make the feature extraction module and feature fusion module running-in better. Experimental results show that compared with multiple large-scale pre-training baselines, MMSR achieves the most advanced results on multiple mainstream datasets including SRBench.
Discovering Mathematical Formulas from Data via GPT-guided Monte Carlo Tree Search
Jan 30, 2024Finding a concise and interpretable mathematical formula that accurately describes the relationship between each variable and the predicted value in the data is a crucial task in scientific research, as well as a significant challenge in artificial intelligence. This problem is referred to as symbolic regression, which is an NP-hard problem. In the previous year, a novel symbolic regression methodology utilizing Monte Carlo Tree Search (MCTS) was advanced, achieving state-of-the-art results on a diverse range of datasets. although this algorithm has shown considerable improvement in recovering target expressions compared to previous methods, the lack of guidance during the MCTS process severely hampers its search efficiency. Recently, some algorithms have added a pre-trained policy network to guide the search of MCTS, but the pre-trained policy network generalizes poorly. To optimize the trade-off between efficiency and versatility, we introduce SR-GPT, a novel algorithm for symbolic regression that integrates Monte Carlo Tree Search (MCTS) with a Generative Pre-Trained Transformer (GPT). By using GPT to guide the MCTS, the search efficiency of MCTS is significantly improved. Next, we utilize the MCTS results to further refine the GPT, enhancing its capabilities and providing more accurate guidance for the MCTS. MCTS and GPT are coupled together and optimize each other until the target expression is successfully determined. We conducted extensive evaluations of SR-GPT using 222 expressions sourced from over 10 different symbolic regression datasets. The experimental results demonstrate that SR-GPT outperforms existing state-of-the-art algorithms in accurately recovering symbolic expressions both with and without added noise.
PruneSymNet: A Symbolic Neural Network and Pruning Algorithm for Symbolic Regression
Jan 25, 2024Symbolic regression aims to derive interpretable symbolic expressions from data in order to better understand and interpret data. %which plays an important role in knowledge discovery and interpretable machine learning. In this study, a symbolic network called PruneSymNet is proposed for symbolic regression. This is a novel neural network whose activation function consists of common elementary functions and operators. The whole network is differentiable and can be trained by gradient descent method. Each subnetwork in the network corresponds to an expression, and our goal is to extract such subnetworks to get the desired symbolic expression. Therefore, a greedy pruning algorithm is proposed to prune the network into a subnetwork while ensuring the accuracy of data fitting. The proposed greedy pruning algorithm preserves the edge with the least loss in each pruning, but greedy algorithm often can not get the optimal solution. In order to alleviate this problem, we combine beam search during pruning to obtain multiple candidate expressions each time, and finally select the expression with the smallest loss as the final result. It was tested on the public data set and compared with the current popular algorithms. The results showed that the proposed algorithm had better accuracy.
A Novel Paradigm for Neural Computation: X-Net with Learnable Neurons and Adaptable Structure
Jan 03, 2024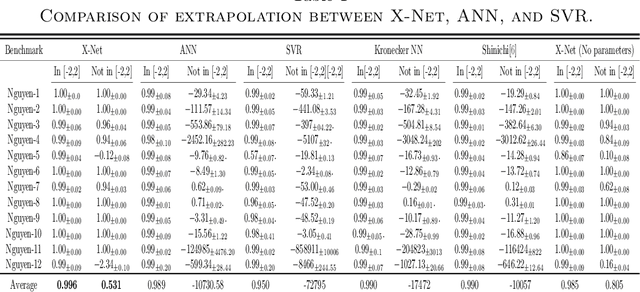
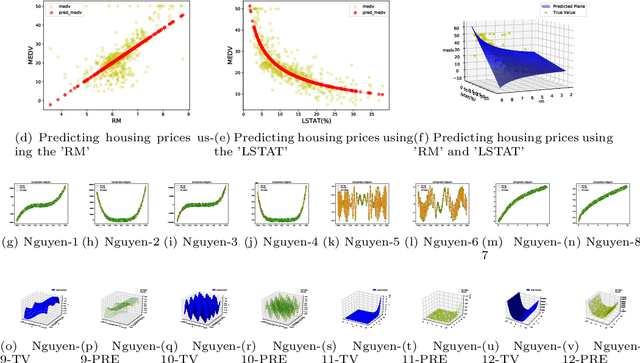
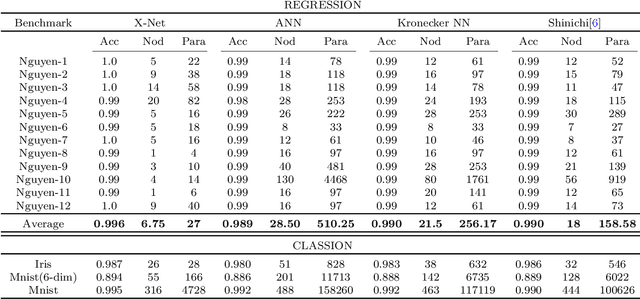
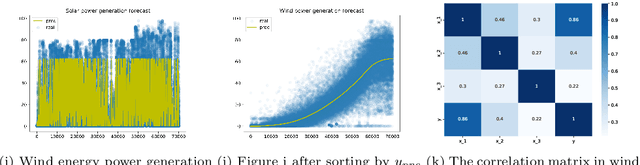
Artificial neural networks (ANNs) have permeated various disciplinary domains, ranging from bioinformatics to financial analytics, where their application has become an indispensable facet of contemporary scientific research endeavors. However, the inherent limitations of traditional neural networks arise due to their relatively fixed network structures and activation functions. 1, The type of activation function is single and relatively fixed, which leads to poor "unit representation ability" of the network, and it is often used to solve simple problems with very complex networks; 2, the network structure is not adaptive, it is easy to cause network structure redundant or insufficient. To address the aforementioned issues, this study proposes a novel neural network called X-Net. By utilizing our designed Alternating Backpropagation mechanism, X-Net dynamically selects appropriate activation functions based on derivative information during training to enhance the network's representation capability for specific tasks. Simultaneously, it accurately adjusts the network structure at the neuron level to accommodate tasks of varying complexities and reduce computational costs. Through a series of experiments, we demonstrate the dual advantages of X-Net in terms of reducing model size and improving representation power. Specifically, in terms of the number of parameters, X-Net is only 3$\%$ of baselines on average, and only 1.4$\%$ under some tasks. In terms of representation ability, X-Net can achieve an average $R^2$=0.985 on the fitting task by only optimizing the activation function without introducing any parameters. Finally, we also tested the ability of X-Net to help scientific discovery on data from multiple disciplines such as society, energy, environment, and aerospace, and achieved concise and good results.
MetaSymNet: A Dynamic Symbolic Regression Network Capable of Evolving into Arbitrary Formulations
Nov 13, 2023



Mathematical formulas serve as the means of communication between humans and nature, encapsulating the operational laws governing natural phenomena. The concise formulation of these laws is a crucial objective in scientific research and an important challenge for artificial intelligence (AI). While traditional artificial neural networks (MLP) excel at data fitting, they often yield uninterpretable black box results that hinder our understanding of the relationship between variables x and predicted values y. Moreover, the fixed network architecture in MLP often gives rise to redundancy in both network structure and parameters. To address these issues, we propose MetaSymNet, a novel neural network that dynamically adjusts its structure in real-time, allowing for both expansion and contraction. This adaptive network employs the PANGU meta function as its activation function, which is a unique type capable of evolving into various basic functions during training to compose mathematical formulas tailored to specific needs. We then evolve the neural network into a concise, interpretable mathematical expression. To evaluate MetaSymNet's performance, we compare it with four state-of-the-art symbolic regression algorithms across more than 10 public datasets comprising 222 formulas. Our experimental results demonstrate that our algorithm outperforms others consistently regardless of noise presence or absence. Furthermore, we assess MetaSymNet against MLP and SVM regarding their fitting ability and extrapolation capability, these are two essential aspects of machine learning algorithms. The findings reveal that our algorithm excels in both areas. Finally, we compared MetaSymNet with MLP using iterative pruning in network structure complexity. The results show that MetaSymNet's network structure complexity is obviously less than MLP under the same goodness of fit.