 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysReflect-VLA: Physical Feasibility and Self-Reflective Regulation for Reliable Vision-Language-Action Policies
Jun 25, 2026Long-horizon robotic manipulation is highly sensitive to physically infeasible transitions, contact-induced disturbances, and the lack of effective self-correction during execution. Although Vision-Language-Action (VLA) models provide strong task grounding through multimodal learning, they typically generate actions in a feed-forward manner without explicitly checking physical feasibility or diagnosing execution errors online. We present PhysReflect-VLA, a plug-and-play execution-time reliability framework that augments VLA policies with physical feasibility evaluation and structured self-reflection in a closed-loop control pipeline. A Feasibility Operator evaluates whether candidate actions induce dynamically consistent state transitions; an Action Explanation Operator verifies transition coherence; and an LLM-based Reflection Module analyzes state discrepancies to generate corrective guidance for subsequent actions. A two-stage training procedure stabilizes feasibility modeling and integrates reflection into the control loop. Experiments on multi-stage, contact-rich real-world manipulation tasks show consistent improvements in stage-wise stability and overall task success compared with representative VLA baselines with an average gain of 5.4\%. Ablation results further indicate that feasibility checking and reflection-based correction both contribute to improved execution robustness. These results highlight the importance of embedding physical consistency checks and online self-reflection for reliable long-horizon robotic manipulation.
GESR: A Genetic Programming-Based Symbolic Regression Method with Gene Editing
May 11, 2026Mathematical formulas serve as a language through which humans communicate with nature. Discovering mathematical laws from scientific data to describe natural phenomena has been a long-standing pursuit of humanity for centuries. In the field of artificial intelligence, this challenge is known as the symbolic regression problem. Among existing symbolic regression approaches, Genetic Programming (GP) based on evolutionary algorithms remains one of the most classical and widely adopted methods. GP simulates the evolutionary process across generations through genetic mutation and crossover. However, mutations and crossovers in GP are entirely random. While this randomness effectively mimics natural evolution, it inevitably produces both beneficial and detrimental variations. If there existed a metaphorical `God` capable of foreseeing which genetic mutations or crossovers would yield superior outcomes and performing targeted gene editing accordingly, the efficiency of evolution could be substantially improved. Motivated by this idea, we propose in this paper a symbolic regression approach based on gene editing, termed GESR. In GESR, we trained two "hands of God" (two BERT models). Among them, the first leverages the BERT's masked language modeling capability to guide the mutation of genes (expression symbols). The other BERT model guides the crossover of individual genes by predicting the crossover point. Experimental results demonstrate that GESR significantly improves computational efficiency compared with traditional GP algorithms and achieves strong overall performance across multiple symbolic regression tasks.
Beyond Theoretical Bounds: Empirical Privacy Loss Calibration for Text Rewriting Under Local Differential Privacy
Mar 24, 2026The growing use of large language models has increased interest in sharing textual data in a privacy-preserving manner. One prominent line of work addresses this challenge through text rewriting under Local Differential Privacy (LDP), where input texts are locally obfuscated before release with formal privacy guarantees. These guarantees are typically expressed by a parameter $\varepsilon$ that upper bounds the worst-case privacy loss. However, nominal $\varepsilon$ values are often difficult to interpret and compare across mechanisms. In this work, we investigate how to empirically calibrate across text rewriting mechanisms under LDP. We propose TeDA, which formulates calibration via a hypothesis-testing framework that instantiates text distinguishability audits in both surface and embedding spaces, enabling empirical assessment of indistinguishability from privatized texts. Applying this calibration to several representative mechanisms, we demonstrate that similar nominal $\varepsilon$ bounds can imply very different levels of distinguishability. Empirical calibration thus provides a more comparable footing for evaluating privacy-utility trade-offs, as well as a practical tool for mechanism comparison and analysis in real-world LDP text rewriting deployments.
QE-Catalytic: A Graph-Language Multimodal Base Model for Relaxed-Energy Prediction in Catalytic Adsorption
Dec 23, 2025Adsorption energy is a key descriptor of catalytic reactivity. It is fundamentally defined as the difference between the relaxed total energy of the adsorbate-surface system and that of an appropriate reference state; therefore, the accuracy of relaxed-energy prediction directly determines the reliability of machine-learning-driven catalyst screening. E(3)-equivariant graph neural networks (GNNs) can natively operate on three-dimensional atomic coordinates under periodic boundary conditions and have demonstrated strong performance on such tasks. In contrast, language-model-based approaches, while enabling human-readable textual descriptions and reducing reliance on explicit graph -- thereby broadening applicability -- remain insufficient in both adsorption-configuration energy prediction accuracy and in distinguishing ``the same system with different configurations,'' even with graph-assisted pretraining in the style of GAP-CATBERTa. To this end, we propose QE-Catalytic, a multimodal framework that deeply couples a large language model (\textbf{Q}wen) with an E(3)-equivariant graph Transformer (\textbf{E}quiformer-V2), enabling unified support for adsorption-configuration property prediction and inverse design on complex catalytic surfaces. During prediction, QE-Catalytic jointly leverages three-dimensional structures and structured configuration text, and injects ``3D geometric information'' into the language channel via graph-text alignment, allowing it to function as a high-performance text-based predictor when precise coordinates are unavailable, while also autoregressively generating CIF files for target-energy-driven structure design and information completion. On OC20, QE-Catalytic reduces the MAE of relaxed adsorption energy from 0.713~eV to 0.486~eV, and consistently outperforms baseline models such as CatBERTa and GAP-CATBERTa across multiple evaluation protocols.
Defending Deep Neural Networks against Backdoor Attacks via Module Switching
Apr 08, 2025The exponential increase in the parameters of Deep Neural Networks (DNNs) has significantly raised the cost of independent training, particularly for resource-constrained entities. As a result, there is a growing reliance on open-source models. However, the opacity of training processes exacerbates security risks, making these models more vulnerable to malicious threats, such as backdoor attacks, while simultaneously complicating defense mechanisms. Merging homogeneous models has gained attention as a cost-effective post-training defense. However, we notice that existing strategies, such as weight averaging, only partially mitigate the influence of poisoned parameters and remain ineffective in disrupting the pervasive spurious correlations embedded across model parameters. We propose a novel module-switching strategy to break such spurious correlations within the model's propagation path. By leveraging evolutionary algorithms to optimize fusion strategies, we validate our approach against backdoor attacks targeting text and vision domains. Our method achieves effective backdoor mitigation even when incorporating a couple of compromised models, e.g., reducing the average attack success rate (ASR) to 22% compared to 31.9% with the best-performing baseline on SST-2.
Cut the Deadwood Out: Post-Training Model Purification with Selective Module Substitution
Dec 29, 2024The success of DNNs often depends on training with large-scale datasets, but building such datasets is both expensive and challenging. Consequently, public datasets from open-source platforms like HuggingFace have become popular, posing significant risks of data poisoning attacks. Existing backdoor defenses in NLP primarily focus on identifying and removing poisoned samples; however, purifying a backdoored model with these sample-cleaning approaches typically requires expensive retraining. Therefore, we propose Greedy Module Substitution (GMS), which identifies and substitutes ''deadwood'' modules (i.e., components critical to backdoor pathways) in a backdoored model to purify it. Our method relaxes the common dependency of prior model purification methods on clean datasets or clean auxiliary models. When applied to RoBERTa-large under backdoor attacks, GMS demonstrates strong effectiveness across various settings, particularly against widely recognized challenging attacks like LWS, achieving a post-purification attack success rate (ASR) of 9.7% on SST-2 compared to 58.8% for the best baseline approach.
Segmentation-aware Prior Assisted Joint Global Information Aggregated 3D Building Reconstruction
Oct 24, 2024Multi-View Stereo plays a pivotal role in civil engineering by facilitating 3D modeling, precise engineering surveying, quantitative analysis, as well as monitoring and maintenance. It serves as a valuable tool, offering high-precision and real-time spatial information crucial for various engineering projects. However, Multi-View Stereo algorithms encounter challenges in reconstructing weakly-textured regions within large-scale building scenes. In these areas, the stereo matching of pixels often fails, leading to inaccurate depth estimations. Based on the Segment Anything Model and RANSAC algorithm, we propose an algorithm that accurately segments weakly-textured regions and constructs their plane priors. These plane priors, combined with triangulation priors, form a reliable prior candidate set. Additionally, we introduce a novel global information aggregation cost function. This function selects optimal plane prior information based on global information in the prior candidate set, constrained by geometric consistency during the depth estimation update process. Experimental results on both the ETH3D benchmark dataset, aerial dataset, building dataset and real scenarios substantiate the superior performance of our method in producing 3D building models compared to other state-of-the-art methods. In summary, our work aims to enhance the completeness and density of 3D building reconstruction, carrying implications for broader applications in urban planning and virtual reality.
Operator Feature Neural Network for Symbolic Regression
Aug 14, 2024Symbolic regression is a task aimed at identifying patterns in data and representing them through mathematical expressions, generally involving skeleton prediction and constant optimization. Many methods have achieved some success, however they treat variables and symbols merely as characters of natural language without considering their mathematical essence. This paper introduces the operator feature neural network (OF-Net) which employs operator representation for expressions and proposes an implicit feature encoding method for the intrinsic mathematical operational logic of operators. By substituting operator features for numeric loss, we can predict the combination of operators of target expressions. We evaluate the model on public datasets, and the results demonstrate that the model achieves superior recovery rates and high $R^2$ scores. With the discussion of the results, we analyze the merit and demerit of OF-Net and propose optimizing schemes.
GPSFormer: A Global Perception and Local Structure Fitting-based Transformer for Point Cloud Understanding
Jul 18, 2024



Despite the significant advancements in pre-training methods for point cloud understanding, directly capturing intricate shape information from irregular point clouds without reliance on external data remains a formidable challenge. To address this problem, we propose GPSFormer, an innovative Global Perception and Local Structure Fitting-based Transformer, which learns detailed shape information from point clouds with remarkable precision. The core of GPSFormer is the Global Perception Module (GPM) and the Local Structure Fitting Convolution (LSFConv). Specifically, GPM utilizes Adaptive Deformable Graph Convolution (ADGConv) to identify short-range dependencies among similar features in the feature space and employs Multi-Head Attention (MHA) to learn long-range dependencies across all positions within the feature space, ultimately enabling flexible learning of contextual representations. Inspired by Taylor series, we design LSFConv, which learns both low-order fundamental and high-order refinement information from explicitly encoded local geometric structures. Integrating the GPM and LSFConv as fundamental components, we construct GPSFormer, a cutting-edge Transformer that effectively captures global and local structures of point clouds. Extensive experiments validate GPSFormer's effectiveness in three point cloud tasks: shape classification, part segmentation, and few-shot learning. The code of GPSFormer is available at \url{https://github.com/changshuowang/GPSFormer}.
DN-CL: Deep Symbolic Regression against Noise via Contrastive Learning
Jun 21, 2024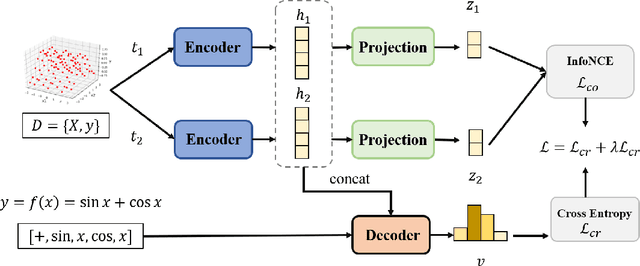

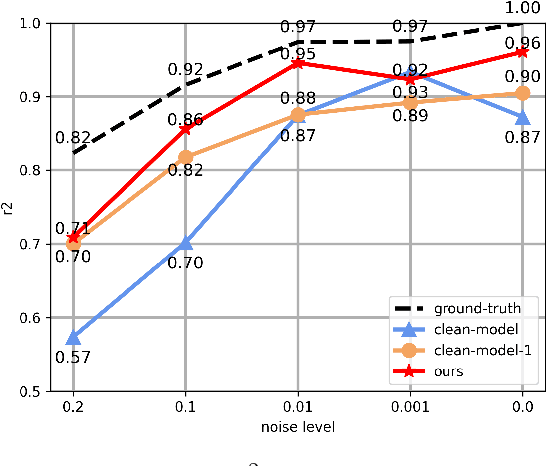
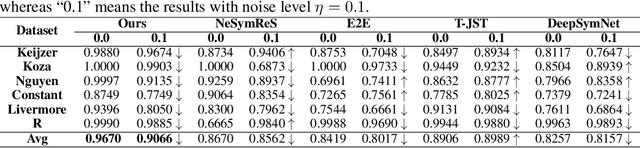
Noise ubiquitously exists in signals due to numerous factors including physical, electronic, and environmental effects. Traditional methods of symbolic regression, such as genetic programming or deep learning models, aim to find the most fitting expressions for these signals. However, these methods often overlook the noise present in real-world data, leading to reduced fitting accuracy. To tackle this issue, we propose \textit{\textbf{D}eep Symbolic Regression against \textbf{N}oise via \textbf{C}ontrastive \textbf{L}earning (DN-CL)}. DN-CL employs two parameter-sharing encoders to embed data points from various data transformations into feature shields against noise. This model treats noisy data and clean data as different views of the ground-truth mathematical expressions. Distances between these features are minimized, utilizing contrastive learning to distinguish between 'positive' noise-corrected pairs and 'negative' contrasting pairs. Our experiments indicate that DN-CL demonstrates superior performance in handling both noisy and clean data, presenting a promising method of symbolic regression.