 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing the Forest through the Trees: Data Leakage from Partial Transformer Gradients
Paper and Code
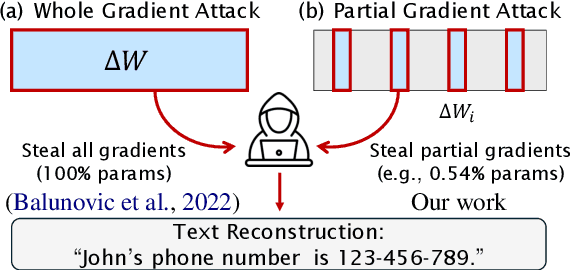
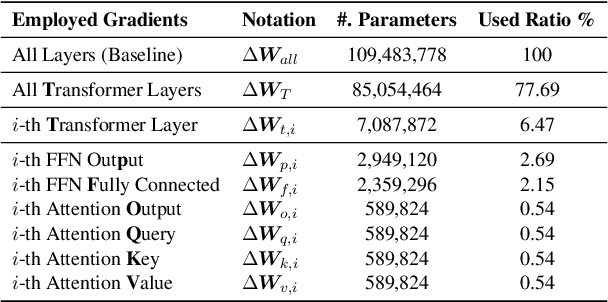
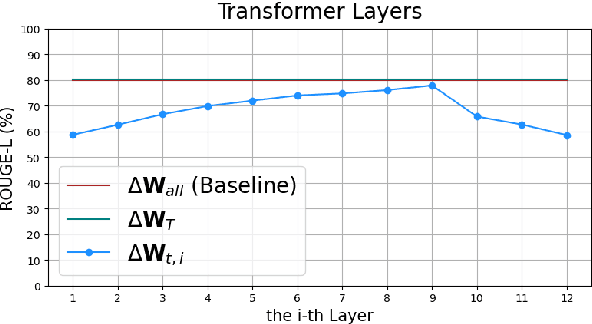
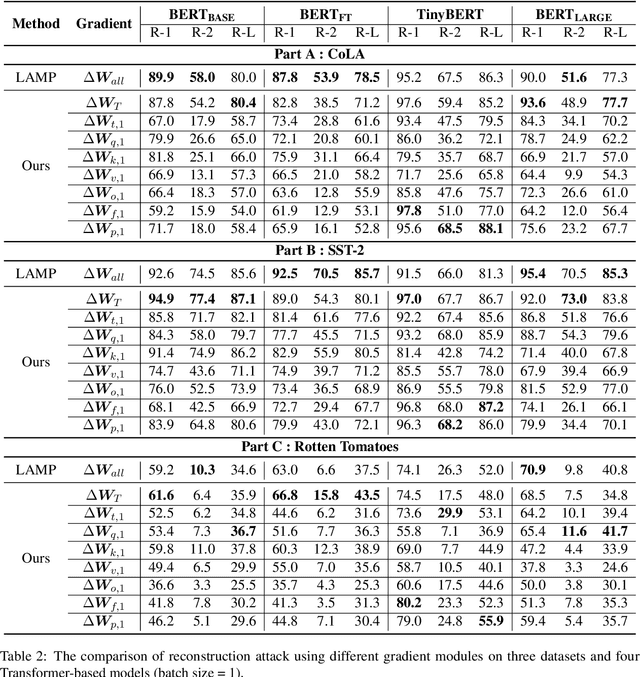
Recent studies have shown that distributed machine learning is vulnerable to gradient inversion attacks, where private training data can be reconstructed by analyzing the gradients of the models shared in training. Previous attacks established that such reconstructions are possible using gradients from all parameters in the entire models. However, we hypothesize that most of the involved modules, or even their sub-modules, are at risk of training data leakage, and we validate such vulnerabilities in various intermediate layers of language models. Our extensive experiments reveal that gradients from a single Transformer layer, or even a single linear component with 0.54% parameters, are susceptible to training data leakage. Additionally, we show that applying differential privacy on gradients during training offers limited protection against the novel vulnerability of data disclosure.