 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleashing Foundation Vision Models: Adaptive Transfer for Diverse Data-Limited Scientific Domains
Dec 27, 2025In the big data era, the computer vision field benefits from large-scale datasets such as LAION-2B, LAION-400M, and ImageNet-21K, Kinetics, on which popular models like the ViT and ConvNeXt series have been pre-trained, acquiring substantial knowledge. However, numerous downstream tasks in specialized and data-limited scientific domains continue to pose significant challenges. In this paper, we propose a novel Cluster Attention Adapter (CLAdapter), which refines and adapts the rich representations learned from large-scale data to various data-limited downstream tasks. Specifically, CLAdapter introduces attention mechanisms and cluster centers to personalize the enhancement of transformed features through distribution correlation and transformation matrices. This enables models fine-tuned with CLAdapter to learn distinct representations tailored to different feature sets, facilitating the models' adaptation from rich pre-trained features to various downstream scenarios effectively. In addition, CLAdapter's unified interface design allows for seamless integration with multiple model architectures, including CNNs and Transformers, in both 2D and 3D contexts. Through extensive experiments on 10 datasets spanning domains such as generic, multimedia, biological, medical, industrial, agricultural, environmental, geographical, materials science, out-of-distribution (OOD), and 3D analysis, CLAdapter achieves state-of-the-art performance across diverse data-limited scientific domains, demonstrating its effectiveness in unleashing the potential of foundation vision models via adaptive transfer. Code is available at https://github.com/qklee-lz/CLAdapter.
Flexible-weighted Chamfer Distance: Enhanced Objective Function for Point Cloud Completion
May 20, 2025Chamfer Distance (CD) comprises two components that can evaluate the global distribution and local performance of generated point clouds, making it widely utilized as a similarity measure between generated and target point clouds in point cloud completion tasks. Additionally, CD's computational efficiency has led to its frequent application as an objective function for guiding point cloud generation. However, using CD directly as an objective function with fixed equal weights for its two components can often result in seemingly high overall performance (i.e., low CD score), while failing to achieve a good global distribution. This is typically reflected in high Earth Mover's Distance (EMD) and Decomposed Chamfer Distance (DCD) scores, alongside poor human assessments. To address this issue, we propose a Flexible-Weighted Chamfer Distance (FCD) to guide point cloud generation. FCD assigns a higher weight to the global distribution component of CD and incorporates a flexible weighting strategy to adjust the balance between the two components, aiming to improve global distribution while maintaining robust overall performance. Experimental results on two state-of-the-art networks demonstrate that our method achieves superior results across multiple evaluation metrics, including CD, EMD, DCD, and F-Score, as well as in human evaluations.
Prompting Continual Person Search
Oct 25, 2024



The development of person search techniques has been greatly promoted in recent years for its superior practicality and challenging goals. Despite their significant progress, existing person search models still lack the ability to continually learn from increaseing real-world data and adaptively process input from different domains. To this end, this work introduces the continual person search task that sequentially learns on multiple domains and then performs person search on all seen domains. This requires balancing the stability and plasticity of the model to continually learn new knowledge without catastrophic forgetting. For this, we propose a Prompt-based Continual Person Search (PoPS) model in this paper. First, we design a compositional person search transformer to construct an effective pre-trained transformer without exhaustive pre-training from scratch on large-scale person search data. This serves as the fundamental for prompt-based continual learning. On top of that, we design a domain incremental prompt pool with a diverse attribute matching module. For each domain, we independently learn a set of prompts to encode the domain-oriented knowledge. Meanwhile, we jointly learn a group of diverse attribute projections and prototype embeddings to capture discriminative domain attributes. By matching an input image with the learned attributes across domains, the learned prompts can be properly selected for model inference. Extensive experiments are conducted to validate the proposed method for continual person search. The source code is available at https://github.com/PatrickZad/PoPS.
GPSFormer: A Global Perception and Local Structure Fitting-based Transformer for Point Cloud Understanding
Jul 18, 2024



Despite the significant advancements in pre-training methods for point cloud understanding, directly capturing intricate shape information from irregular point clouds without reliance on external data remains a formidable challenge. To address this problem, we propose GPSFormer, an innovative Global Perception and Local Structure Fitting-based Transformer, which learns detailed shape information from point clouds with remarkable precision. The core of GPSFormer is the Global Perception Module (GPM) and the Local Structure Fitting Convolution (LSFConv). Specifically, GPM utilizes Adaptive Deformable Graph Convolution (ADGConv) to identify short-range dependencies among similar features in the feature space and employs Multi-Head Attention (MHA) to learn long-range dependencies across all positions within the feature space, ultimately enabling flexible learning of contextual representations. Inspired by Taylor series, we design LSFConv, which learns both low-order fundamental and high-order refinement information from explicitly encoded local geometric structures. Integrating the GPM and LSFConv as fundamental components, we construct GPSFormer, a cutting-edge Transformer that effectively captures global and local structures of point clouds. Extensive experiments validate GPSFormer's effectiveness in three point cloud tasks: shape classification, part segmentation, and few-shot learning. The code of GPSFormer is available at \url{https://github.com/changshuowang/GPSFormer}.
Debiasing Machine Unlearning with Counterfactual Examples
Apr 24, 2024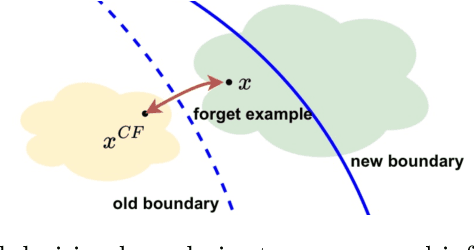

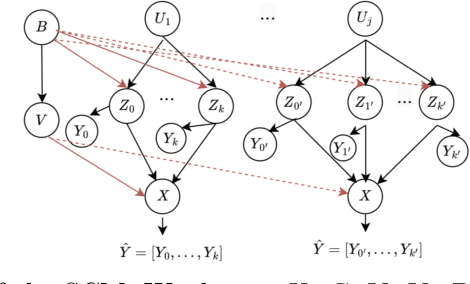
The right to be forgotten (RTBF) seeks to safeguard individuals from the enduring effects of their historical actions by implementing machine-learning techniques. These techniques facilitate the deletion of previously acquired knowledge without requiring extensive model retraining. However, they often overlook a critical issue: unlearning processes bias. This bias emerges from two main sources: (1) data-level bias, characterized by uneven data removal, and (2) algorithm-level bias, which leads to the contamination of the remaining dataset, thereby degrading model accuracy. In this work, we analyze the causal factors behind the unlearning process and mitigate biases at both data and algorithmic levels. Typically, we introduce an intervention-based approach, where knowledge to forget is erased with a debiased dataset. Besides, we guide the forgetting procedure by leveraging counterfactual examples, as they maintain semantic data consistency without hurting performance on the remaining dataset. Experimental results demonstrate that our method outperforms existing machine unlearning baselines on evaluation metrics.
TalkingGaussian: Structure-Persistent 3D Talking Head Synthesis via Gaussian Splatting
Apr 23, 2024


Radiance fields have demonstrated impressive performance in synthesizing lifelike 3D talking heads. However, due to the difficulty in fitting steep appearance changes, the prevailing paradigm that presents facial motions by directly modifying point appearance may lead to distortions in dynamic regions. To tackle this challenge, we introduce TalkingGaussian, a deformation-based radiance fields framework for high-fidelity talking head synthesis. Leveraging the point-based Gaussian Splatting, facial motions can be represented in our method by applying smooth and continuous deformations to persistent Gaussian primitives, without requiring to learn the difficult appearance change like previous methods. Due to this simplification, precise facial motions can be synthesized while keeping a highly intact facial feature. Under such a deformation paradigm, we further identify a face-mouth motion inconsistency that would affect the learning of detailed speaking motions. To address this conflict, we decompose the model into two branches separately for the face and inside mouth areas, therefore simplifying the learning tasks to help reconstruct more accurate motion and structure of the mouth region. Extensive experiments demonstrate that our method renders high-quality lip-synchronized talking head videos, with better facial fidelity and higher efficiency compared with previous methods.
DNGaussian: Optimizing Sparse-View 3D Gaussian Radiance Fields with Global-Local Depth Normalization
Mar 13, 2024



Radiance fields have demonstrated impressive performance in synthesizing novel views from sparse input views, yet prevailing methods suffer from high training costs and slow inference speed. This paper introduces DNGaussian, a depth-regularized framework based on 3D Gaussian radiance fields, offering real-time and high-quality few-shot novel view synthesis at low costs. Our motivation stems from the highly efficient representation and surprising quality of the recent 3D Gaussian Splatting, despite it will encounter a geometry degradation when input views decrease. In the Gaussian radiance fields, we find this degradation in scene geometry primarily lined to the positioning of Gaussian primitives and can be mitigated by depth constraint. Consequently, we propose a Hard and Soft Depth Regularization to restore accurate scene geometry under coarse monocular depth supervision while maintaining a fine-grained color appearance. To further refine detailed geometry reshaping, we introduce Global-Local Depth Normalization, enhancing the focus on small local depth changes. Extensive experiments on LLFF, DTU, and Blender datasets demonstrate that DNGaussian outperforms state-of-the-art methods, achieving comparable or better results with significantly reduced memory cost, a $25 \times$ reduction in training time, and over $3000 \times$ faster rendering speed.
PL-FSCIL: Harnessing the Power of Prompts for Few-Shot Class-Incremental Learning
Jan 26, 2024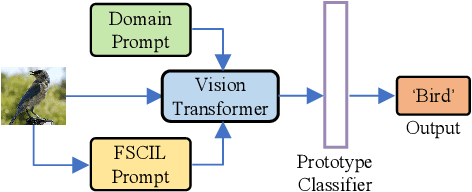
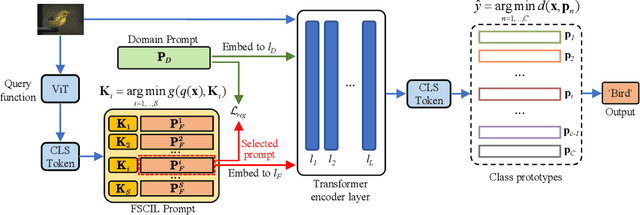
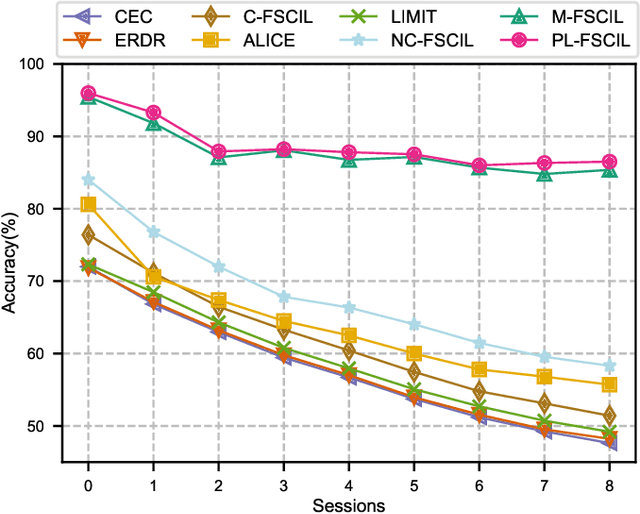
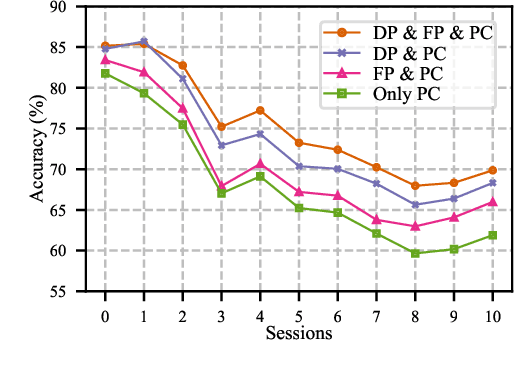
Few-Shot Class-Incremental Learning (FSCIL) aims to enable deep neural networks to learn new tasks incrementally from a small number of labeled samples without forgetting previously learned tasks, closely mimicking human learning patterns. In this paper, we propose a novel approach called Prompt Learning for FSCIL (PL-FSCIL), which harnesses the power of prompts in conjunction with a pre-trained Vision Transformer (ViT) model to address the challenges of FSCIL effectively. Our work pioneers the use of visual prompts in FSCIL, which is characterized by its notable simplicity. PL-FSCIL consists of two distinct prompts: the Domain Prompt and the FSCIL Prompt. Both are vectors that augment the model by embedding themselves into the attention layer of the ViT model. Specifically, the Domain Prompt assists the ViT model in adapting to new data domains. The task-specific FSCIL Prompt, coupled with a prototype classifier, amplifies the model's ability to effectively handle FSCIL tasks. We validate the efficacy of PL-FSCIL on widely used benchmark datasets such as CIFAR-100 and CUB-200. The results showcase competitive performance, underscoring its promising potential for real-world applications where high-quality data is often scarce. The source code is available at: https://github.com/TianSongS/PL-FSCIL.
Deep Learning-based 3D Point Cloud Classification: A Systematic Survey and Outlook
Nov 05, 2023In recent years, point cloud representation has become one of the research hotspots in the field of computer vision, and has been widely used in many fields, such as autonomous driving, virtual reality, robotics, etc. Although deep learning techniques have achieved great success in processing regular structured 2D grid image data, there are still great challenges in processing irregular, unstructured point cloud data. Point cloud classification is the basis of point cloud analysis, and many deep learning-based methods have been widely used in this task. Therefore, the purpose of this paper is to provide researchers in this field with the latest research progress and future trends. First, we introduce point cloud acquisition, characteristics, and challenges. Second, we review 3D data representations, storage formats, and commonly used datasets for point cloud classification. We then summarize deep learning-based methods for point cloud classification and complement recent research work. Next, we compare and analyze the performance of the main methods. Finally, we discuss some challenges and future directions for point cloud classification.
Occluded Person Re-Identification with Deep Learning: A Survey and Perspectives
Nov 01, 2023Person re-identification (Re-ID) technology plays an increasingly crucial role in intelligent surveillance systems. Widespread occlusion significantly impacts the performance of person Re-ID. Occluded person Re-ID refers to a pedestrian matching method that deals with challenges such as pedestrian information loss, noise interference, and perspective misalignment. It has garnered extensive attention from researchers. Over the past few years, several occlusion-solving person Re-ID methods have been proposed, tackling various sub-problems arising from occlusion. However, there is a lack of comprehensive studies that compare, summarize, and evaluate the potential of occluded person Re-ID methods in detail. In this review, we start by providing a detailed overview of the datasets and evaluation scheme used for occluded person Re-ID. Next, we scientifically classify and analyze existing deep learning-based occluded person Re-ID methods from various perspectives, summarizing them concisely. Furthermore, we conduct a systematic comparison among these methods, identify the state-of-the-art approaches, and present an outlook on the future development of occluded person Re-ID.