 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-Policy Evaluation with Strategic Agents via Local Disclosure
Jun 05, 2026We study off-policy evaluation (OPE) under strategic behavior where decision subjects (or agents) respond to a decision maker's policy by strategically modifying their covariates. Such behavior induces a policy-dependent covariate shift, breaking the standard assumption in existing methods that covariates are exogenous to the policy. Related work addresses this challenge by imposing strong assumptions such as repeated interactions or full knowledge of agents' response behavior, substantially limiting its applicability to OPE. In contrast, we consider a one-shot OPE setting where the decision maker has only partial knowledge of the agents' response behavior. Our key insight is that disclosing local information through post-hoc explanations reveals agents' pre-strategic covariates prior to adaptation, mitigating the information loss induced by strategic behavior. Leveraging this structure, we estimate a statistical model for the agents' responses and construct a doubly robust estimator for policy value. By assuming that the agents' cost sensitivity follows a conditional log-normal distribution, we establish consistency of the proposed estimator and validate our approach empirically. More broadly, our results highlight how interaction design can mitigate information asymmetry by revealing otherwise hidden structure in agents' strategic responses.
When Shift Happens - Confounding Is to Blame
May 27, 2025Distribution shifts introduce uncertainty that undermines the robustness and generalization capabilities of machine learning models. While conventional wisdom suggests that learning causal-invariant representations enhances robustness to such shifts, recent empirical studies present a counterintuitive finding: (i) empirical risk minimization (ERM) can rival or even outperform state-of-the-art out-of-distribution (OOD) generalization methods, and (ii) its OOD generalization performance improves when all available covariates, not just causal ones, are utilized. Drawing on both empirical and theoretical evidence, we attribute this phenomenon to hidden confounding. Shifts in hidden confounding induce changes in data distributions that violate assumptions commonly made by existing OOD generalization approaches. Under such conditions, we prove that effective generalization requires learning environment-specific relationships, rather than relying solely on invariant ones. Furthermore, we show that models augmented with proxies for hidden confounders can mitigate the challenges posed by hidden confounding shifts. These findings offer new theoretical insights and practical guidance for designing robust OOD generalization algorithms and principled covariate selection strategies.
Efficient Vocabulary-Free Fine-Grained Visual Recognition in the Age of Multimodal LLMs
May 02, 2025Fine-grained Visual Recognition (FGVR) involves distinguishing between visually similar categories, which is inherently challenging due to subtle inter-class differences and the need for large, expert-annotated datasets. In domains like medical imaging, such curated datasets are unavailable due to issues like privacy concerns and high annotation costs. In such scenarios lacking labeled data, an FGVR model cannot rely on a predefined set of training labels, and hence has an unconstrained output space for predictions. We refer to this task as Vocabulary-Free FGVR (VF-FGVR), where a model must predict labels from an unconstrained output space without prior label information. While recent Multimodal Large Language Models (MLLMs) show potential for VF-FGVR, querying these models for each test input is impractical because of high costs and prohibitive inference times. To address these limitations, we introduce \textbf{Nea}rest-Neighbor Label \textbf{R}efinement (NeaR), a novel approach that fine-tunes a downstream CLIP model using labels generated by an MLLM. Our approach constructs a weakly supervised dataset from a small, unlabeled training set, leveraging MLLMs for label generation. NeaR is designed to handle the noise, stochasticity, and open-endedness inherent in labels generated by MLLMs, and establishes a new benchmark for efficient VF-FGVR.
Detecting and Measuring Confounding Using Causal Mechanism Shifts
Sep 26, 2024

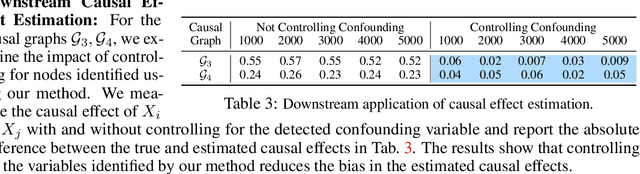
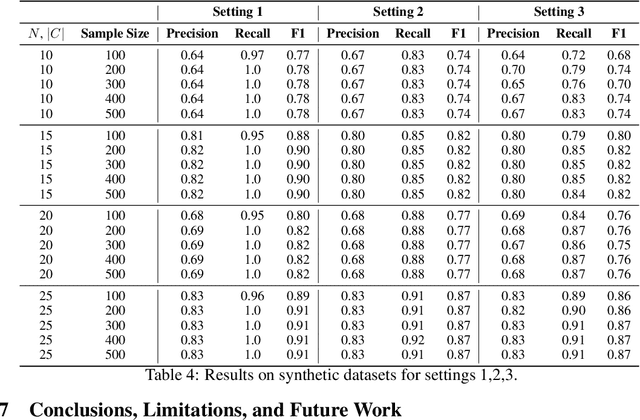
Detecting and measuring confounding effects from data is a key challenge in causal inference. Existing methods frequently assume causal sufficiency, disregarding the presence of unobserved confounding variables. Causal sufficiency is both unrealistic and empirically untestable. Additionally, existing methods make strong parametric assumptions about the underlying causal generative process to guarantee the identifiability of confounding variables. Relaxing the causal sufficiency and parametric assumptions and leveraging recent advancements in causal discovery and confounding analysis with non-i.i.d. data, we propose a comprehensive approach for detecting and measuring confounding. We consider various definitions of confounding and introduce tailored methodologies to achieve three objectives: (i) detecting and measuring confounding among a set of variables, (ii) separating observed and unobserved confounding effects, and (iii) understanding the relative strengths of confounding bias between different sets of variables. We present useful properties of a confounding measure and present measures that satisfy those properties. Empirical results support the theoretical analysis.
Teaching Transformers Causal Reasoning through Axiomatic Training
Jul 10, 2024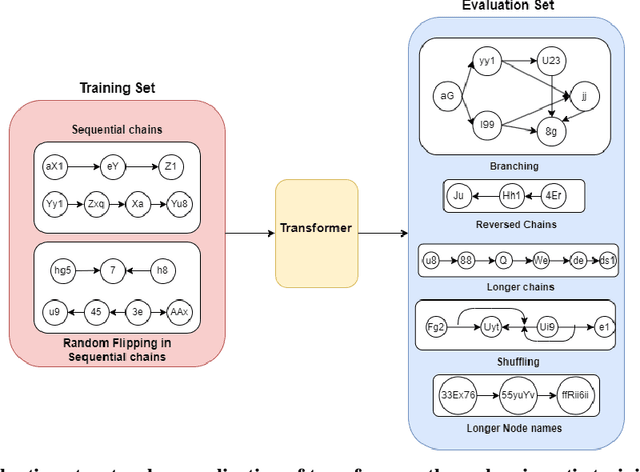
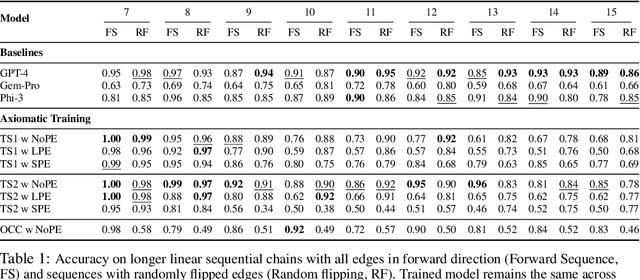
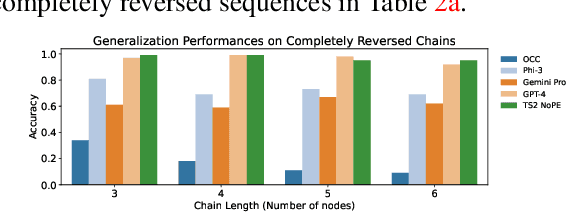
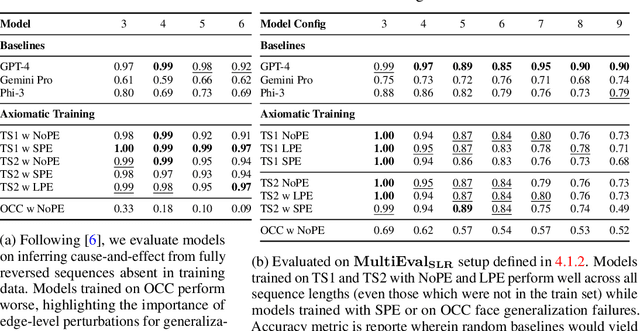
For text-based AI systems to interact in the real world, causal reasoning is an essential skill. Since interventional data is costly to generate, we study to what extent an agent can learn causal reasoning from passive data. Specifically, we consider an axiomatic training setup where an agent learns from multiple demonstrations of a causal axiom (or rule), rather than incorporating the axiom as an inductive bias or inferring it from data values. A key question is whether the agent would learn to generalize from the axiom demonstrations to new scenarios. For example, if a transformer model is trained on demonstrations of the causal transitivity axiom over small graphs, would it generalize to applying the transitivity axiom over large graphs? Our results, based on a novel axiomatic training scheme, indicate that such generalization is possible. We consider the task of inferring whether a variable causes another variable, given a causal graph structure. We find that a 67 million parameter transformer model, when trained on linear causal chains (along with some noisy variations) can generalize well to new kinds of graphs, including longer causal chains, causal chains with reversed order, and graphs with branching; even when it is not explicitly trained for such settings. Our model performs at par (or even better) than many larger language models such as GPT-4, Gemini Pro, and Phi-3. Overall, our axiomatic training framework provides a new paradigm of learning causal reasoning from passive data that can be used to learn arbitrary axioms, as long as sufficient demonstrations can be generated.
Can Better Text Semantics in Prompt Tuning Improve VLM Generalization?
May 13, 2024Going beyond mere fine-tuning of vision-language models (VLMs), learnable prompt tuning has emerged as a promising, resource-efficient alternative. Despite their potential, effectively learning prompts faces the following challenges: (i) training in a low-shot scenario results in overfitting, limiting adaptability and yielding weaker performance on newer classes or datasets; (ii) prompt-tuning's efficacy heavily relies on the label space, with decreased performance in large class spaces, signaling potential gaps in bridging image and class concepts. In this work, we ask the question if better text semantics can help address these concerns. In particular, we introduce a prompt-tuning method that leverages class descriptions obtained from large language models (LLMs). Our approach constructs part-level description-guided views of both image and text features, which are subsequently aligned to learn more generalizable prompts. Our comprehensive experiments, conducted across 11 benchmark datasets, outperform established methods, demonstrating substantial improvements.
Debiasing Machine Unlearning with Counterfactual Examples
Apr 24, 2024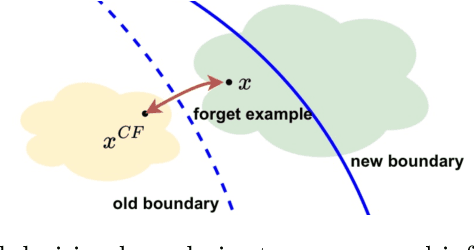

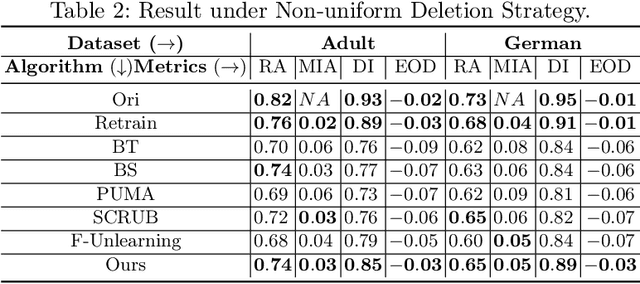
The right to be forgotten (RTBF) seeks to safeguard individuals from the enduring effects of their historical actions by implementing machine-learning techniques. These techniques facilitate the deletion of previously acquired knowledge without requiring extensive model retraining. However, they often overlook a critical issue: unlearning processes bias. This bias emerges from two main sources: (1) data-level bias, characterized by uneven data removal, and (2) algorithm-level bias, which leads to the contamination of the remaining dataset, thereby degrading model accuracy. In this work, we analyze the causal factors behind the unlearning process and mitigate biases at both data and algorithmic levels. Typically, we introduce an intervention-based approach, where knowledge to forget is erased with a debiased dataset. Besides, we guide the forgetting procedure by leveraging counterfactual examples, as they maintain semantic data consistency without hurting performance on the remaining dataset. Experimental results demonstrate that our method outperforms existing machine unlearning baselines on evaluation metrics.
Causal Inference Using LLM-Guided Discovery
Oct 23, 2023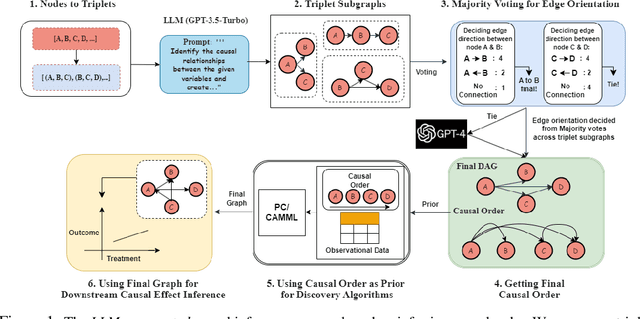

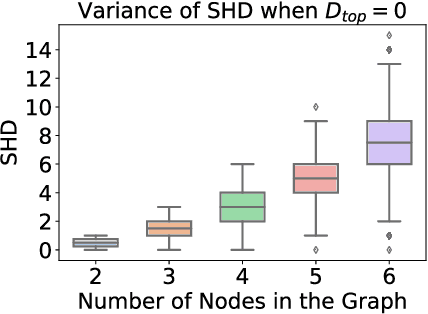

At the core of causal inference lies the challenge of determining reliable causal graphs solely based on observational data. Since the well-known backdoor criterion depends on the graph, any errors in the graph can propagate downstream to effect inference. In this work, we initially show that complete graph information is not necessary for causal effect inference; the topological order over graph variables (causal order) alone suffices. Further, given a node pair, causal order is easier to elicit from domain experts compared to graph edges since determining the existence of an edge can depend extensively on other variables. Interestingly, we find that the same principle holds for Large Language Models (LLMs) such as GPT-3.5-turbo and GPT-4, motivating an automated method to obtain causal order (and hence causal effect) with LLMs acting as virtual domain experts. To this end, we employ different prompting strategies and contextual cues to propose a robust technique of obtaining causal order from LLMs. Acknowledging LLMs' limitations, we also study possible techniques to integrate LLMs with established causal discovery algorithms, including constraint-based and score-based methods, to enhance their performance. Extensive experiments demonstrate that our approach significantly improves causal ordering accuracy as compared to discovery algorithms, highlighting the potential of LLMs to enhance causal inference across diverse fields.
Rethinking Counterfactual Data Augmentation Under Confounding
May 29, 2023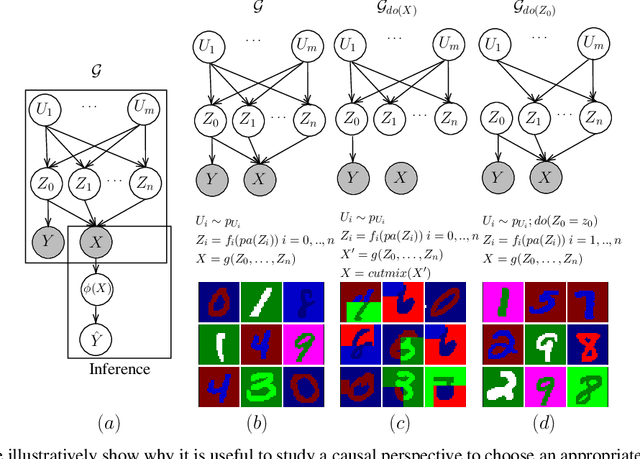
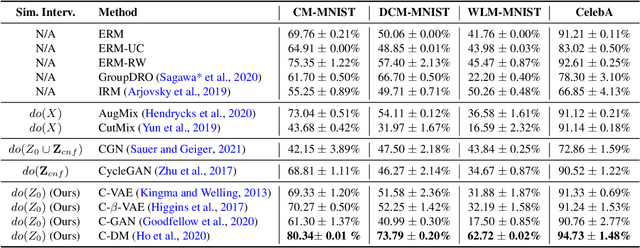
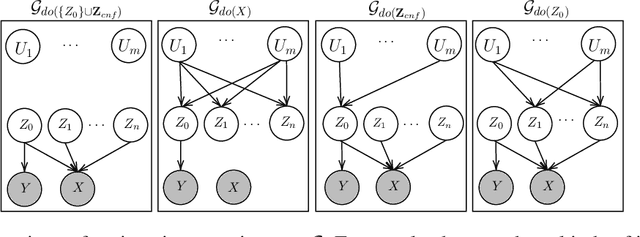

Counterfactual data augmentation has recently emerged as a method to mitigate confounding biases in the training data for a machine learning model. These biases, such as spurious correlations, arise due to various observed and unobserved confounding variables in the data generation process. In this paper, we formally analyze how confounding biases impact downstream classifiers and present a causal viewpoint to the solutions based on counterfactual data augmentation. We explore how removing confounding biases serves as a means to learn invariant features, ultimately aiding in generalization beyond the observed data distribution. Additionally, we present a straightforward yet powerful algorithm for generating counterfactual images, which effectively mitigates the influence of confounding effects on downstream classifiers. Through experiments on MNIST variants and the CelebA datasets, we demonstrate the effectiveness and practicality of our approach.
Estimating Treatment Effects using Neurosymbolic Program Synthesis
Nov 08, 2022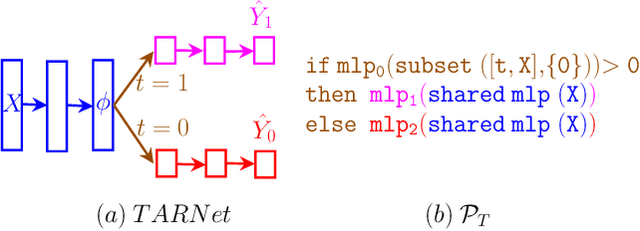

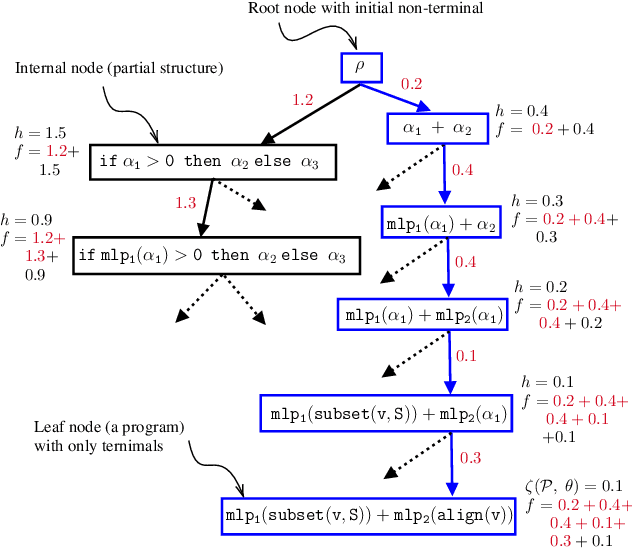
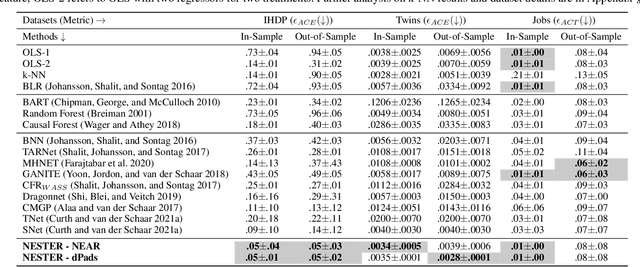
Estimating treatment effects from observational data is a central problem in causal inference. Methods to solve this problem exploit inductive biases and heuristics from causal inference to design multi-head neural network architectures and regularizers. In this work, we propose to use neurosymbolic program synthesis, a data-efficient, and interpretable technique, to solve the treatment effect estimation problem. We theoretically show that neurosymbolic programming can solve the treatment effect estimation problem. By designing a Domain Specific Language (DSL) for treatment effect estimation problem based on the inductive biases used in literature, we argue that neurosymbolic programming is a better alternative to treatment effect estimation than traditional methods. Our empirical study reveals that our method, which implicitly encodes inductive biases in a DSL, achieves better performance on benchmark datasets than the state-of-the-art methods.