 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Domain Adaptation for Occlusion Resilient Human Pose Estimation
Jan 06, 2025



Occlusions are a significant challenge to human pose estimation algorithms, often resulting in inaccurate and anatomically implausible poses. Although current occlusion-robust human pose estimation algorithms exhibit impressive performance on existing datasets, their success is largely attributed to supervised training and the availability of additional information, such as multiple views or temporal continuity. Furthermore, these algorithms typically suffer from performance degradation under distribution shifts. While existing domain adaptive human pose estimation algorithms address this bottleneck, they tend to perform suboptimally when the target domain images are occluded, a common occurrence in real-life scenarios. To address these challenges, we propose OR-POSE: Unsupervised Domain Adaptation for Occlusion Resilient Human POSE Estimation. OR-POSE is an innovative unsupervised domain adaptation algorithm which effectively mitigates domain shifts and overcomes occlusion challenges by employing the mean teacher framework for iterative pseudo-label refinement. Additionally, OR-POSE reinforces realistic pose prediction by leveraging a learned human pose prior which incorporates the anatomical constraints of humans in the adaptation process. Lastly, OR-POSE avoids overfitting to inaccurate pseudo labels generated from heavily occluded images by employing a novel visibility-based curriculum learning approach. This enables the model to gradually transition from training samples with relatively less occlusion to more challenging, heavily occluded samples. Extensive experiments show that OR-POSE outperforms existing analogous state-of-the-art algorithms by $\sim$ 7% on challenging occluded human pose estimation datasets.
Unfair Alignment: Examining Safety Alignment Across Vision Encoder Layers in Vision-Language Models
Nov 06, 2024



Vision-language models (VLMs) have improved significantly in multi-modal tasks, but their more complex architecture makes their safety alignment more challenging than the alignment of large language models (LLMs). In this paper, we reveal an unfair distribution of safety across the layers of VLM's vision encoder, with earlier and middle layers being disproportionately vulnerable to malicious inputs compared to the more robust final layers. This 'cross-layer' vulnerability stems from the model's inability to generalize its safety training from the default architectural settings used during training to unseen or out-of-distribution scenarios, leaving certain layers exposed. We conduct a comprehensive analysis by projecting activations from various intermediate layers and demonstrate that these layers are more likely to generate harmful outputs when exposed to malicious inputs. Our experiments with LLaVA-1.5 and Llama 3.2 show discrepancies in attack success rates and toxicity scores across layers, indicating that current safety alignment strategies focused on a single default layer are insufficient.
Causal Inference Using LLM-Guided Discovery
Oct 23, 2023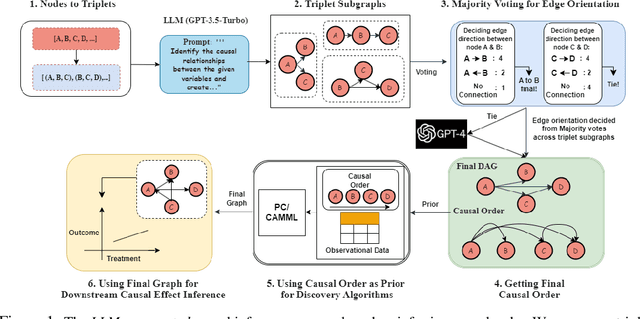

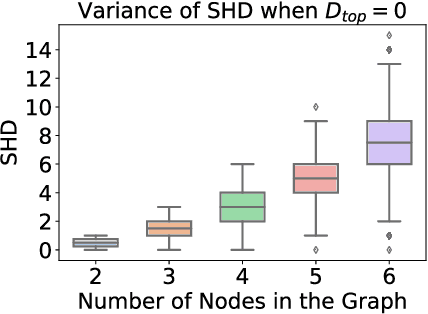

At the core of causal inference lies the challenge of determining reliable causal graphs solely based on observational data. Since the well-known backdoor criterion depends on the graph, any errors in the graph can propagate downstream to effect inference. In this work, we initially show that complete graph information is not necessary for causal effect inference; the topological order over graph variables (causal order) alone suffices. Further, given a node pair, causal order is easier to elicit from domain experts compared to graph edges since determining the existence of an edge can depend extensively on other variables. Interestingly, we find that the same principle holds for Large Language Models (LLMs) such as GPT-3.5-turbo and GPT-4, motivating an automated method to obtain causal order (and hence causal effect) with LLMs acting as virtual domain experts. To this end, we employ different prompting strategies and contextual cues to propose a robust technique of obtaining causal order from LLMs. Acknowledging LLMs' limitations, we also study possible techniques to integrate LLMs with established causal discovery algorithms, including constraint-based and score-based methods, to enhance their performance. Extensive experiments demonstrate that our approach significantly improves causal ordering accuracy as compared to discovery algorithms, highlighting the potential of LLMs to enhance causal inference across diverse fields.
Building a Winning Team: Selecting Source Model Ensembles using a Submodular Transferability Estimation Approach
Sep 05, 2023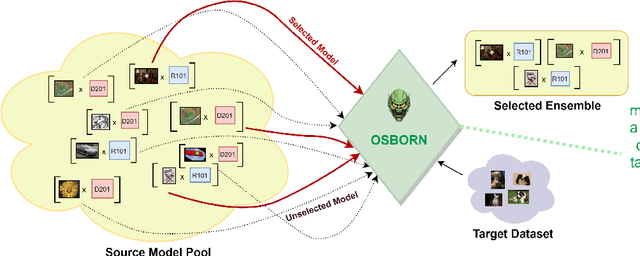


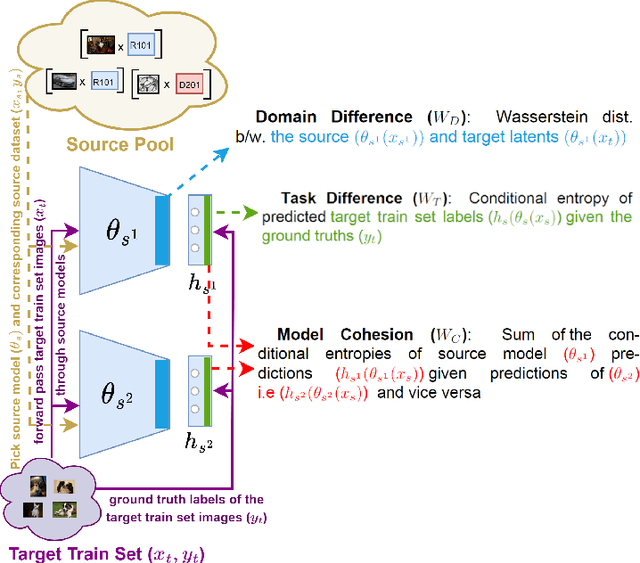
Estimating the transferability of publicly available pretrained models to a target task has assumed an important place for transfer learning tasks in recent years. Existing efforts propose metrics that allow a user to choose one model from a pool of pre-trained models without having to fine-tune each model individually and identify one explicitly. With the growth in the number of available pre-trained models and the popularity of model ensembles, it also becomes essential to study the transferability of multiple-source models for a given target task. The few existing efforts study transferability in such multi-source ensemble settings using just the outputs of the classification layer and neglect possible domain or task mismatch. Moreover, they overlook the most important factor while selecting the source models, viz., the cohesiveness factor between them, which can impact the performance and confidence in the prediction of the ensemble. To address these gaps, we propose a novel Optimal tranSport-based suBmOdular tRaNsferability metric (OSBORN) to estimate the transferability of an ensemble of models to a downstream task. OSBORN collectively accounts for image domain difference, task difference, and cohesiveness of models in the ensemble to provide reliable estimates of transferability. We gauge the performance of OSBORN on both image classification and semantic segmentation tasks. Our setup includes 28 source datasets, 11 target datasets, 5 model architectures, and 2 pre-training methods. We benchmark our method against current state-of-the-art metrics MS-LEEP and E-LEEP, and outperform them consistently using the proposed approach.
Rethinking Counterfactual Data Augmentation Under Confounding
May 29, 2023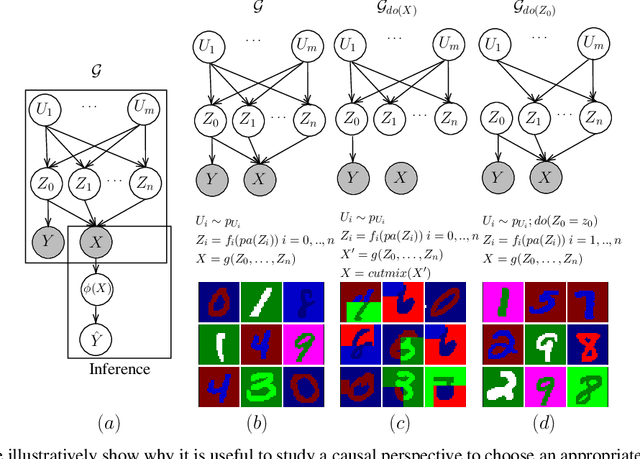
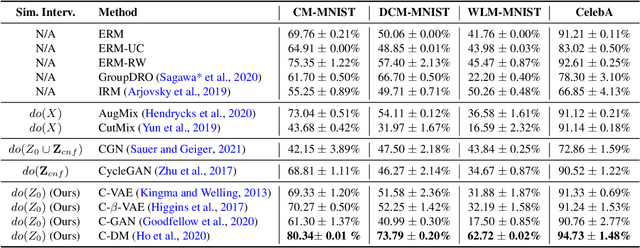
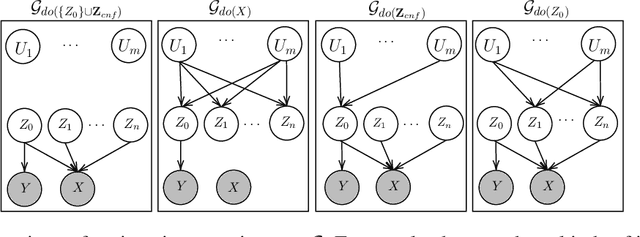

Counterfactual data augmentation has recently emerged as a method to mitigate confounding biases in the training data for a machine learning model. These biases, such as spurious correlations, arise due to various observed and unobserved confounding variables in the data generation process. In this paper, we formally analyze how confounding biases impact downstream classifiers and present a causal viewpoint to the solutions based on counterfactual data augmentation. We explore how removing confounding biases serves as a means to learn invariant features, ultimately aiding in generalization beyond the observed data distribution. Additionally, we present a straightforward yet powerful algorithm for generating counterfactual images, which effectively mitigates the influence of confounding effects on downstream classifiers. Through experiments on MNIST variants and the CelebA datasets, we demonstrate the effectiveness and practicality of our approach.
Learning Causal Attributions in Neural Networks: Beyond Direct Effects
Mar 24, 2023
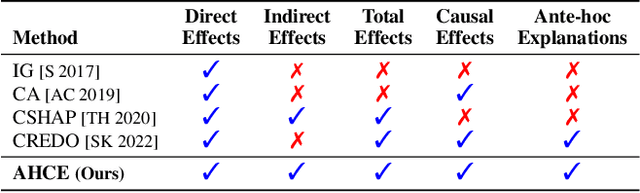
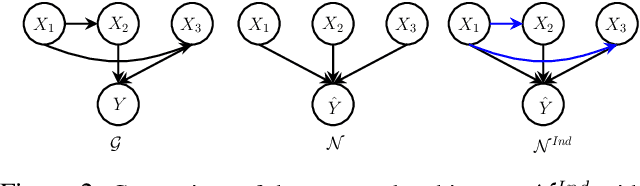

There has been a growing interest in capturing and maintaining causal relationships in Neural Network (NN) models in recent years. We study causal approaches to estimate and maintain input-output attributions in NN models in this work. In particular, existing efforts in this direction assume independence among input variables (by virtue of the NN architecture), and hence study only direct causal effects. Viewing an NN as a structural causal model (SCM), we instead focus on going beyond direct effects, introduce edges among input features, and provide a simple yet effective methodology to capture and maintain direct and indirect causal effects while training an NN model. We also propose effective approximation strategies to quantify causal attributions in high dimensional data. Our wide range of experiments on synthetic and real-world datasets show that the proposed ante-hoc method learns causal attributions for both direct and indirect causal effects close to the ground truth effects.
Towards Estimating Transferability using Hard Subsets
Jan 17, 2023
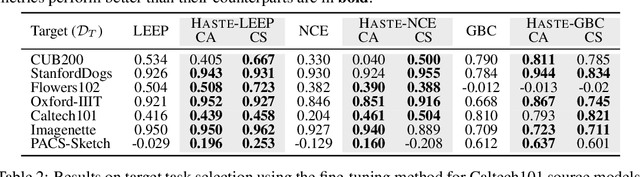
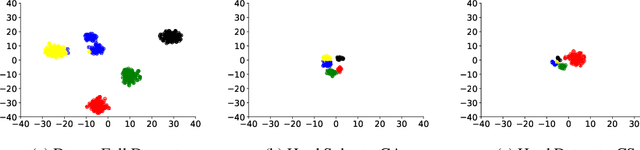
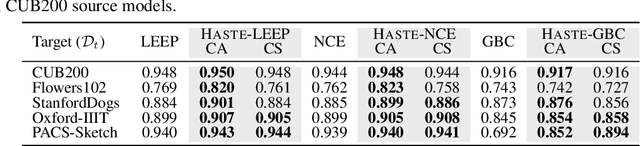
As transfer learning techniques are increasingly used to transfer knowledge from the source model to the target task, it becomes important to quantify which source models are suitable for a given target task without performing computationally expensive fine tuning. In this work, we propose HASTE (HArd Subset TransfErability), a new strategy to estimate the transferability of a source model to a particular target task using only a harder subset of target data. By leveraging the internal and output representations of model, we introduce two techniques, one class agnostic and another class specific, to identify harder subsets and show that HASTE can be used with any existing transferability metric to improve their reliability. We further analyze the relation between HASTE and the optimal average log likelihood as well as negative conditional entropy and empirically validate our theoretical bounds. Our experimental results across multiple source model architectures, target datasets, and transfer learning tasks show that HASTE modified metrics are consistently better or on par with the state of the art transferability metrics.