 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Autonomous Laboratory Safety Monitoring with Vision Language Models: Learning to See Hazards Through Scene Structure
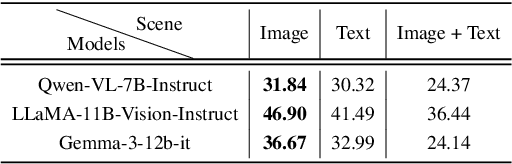
Jan 31, 2026Laboratories are prone to severe injuries from minor unsafe actions, yet continuous safety monitoring -- beyond mandatory pre-lab safety training -- is limited by human availability. Vision language models (VLMs) offer promise for autonomous laboratory safety monitoring, but their effectiveness in realistic settings is unclear due to the lack of visual evaluation data, as most safety incidents are documented primarily as unstructured text. To address this gap, we first introduce a structured data generation pipeline that converts textual laboratory scenarios into aligned triples of (image, scene graph, ground truth), using large language models as scene graph architects and image generation models as renderers. Our experiments on the synthetic dataset of 1,207 samples across 362 unique scenarios and seven open- and closed-source models show that VLMs perform effectively given textual scene graph, but degrade substantially in visual-only settings indicating difficulty in extracting structured object relationships directly from pixels. To overcome this, we propose a post-training context-engineering approach, scene-graph-guided alignment, to bridge perceptual gaps in VLMs by translating visual inputs into structured scene graphs better aligned with VLM reasoning, improving hazard detection performance in visual only settings.
HEAL: An Empirical Study on Hallucinations in Embodied Agents Driven by Large Language Models
Jun 18, 2025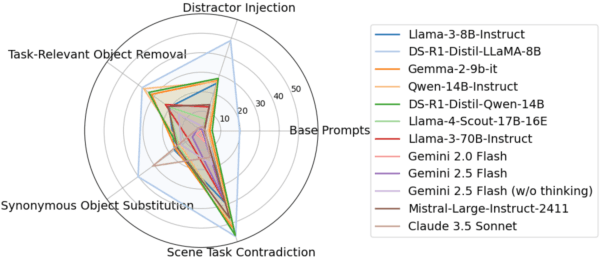
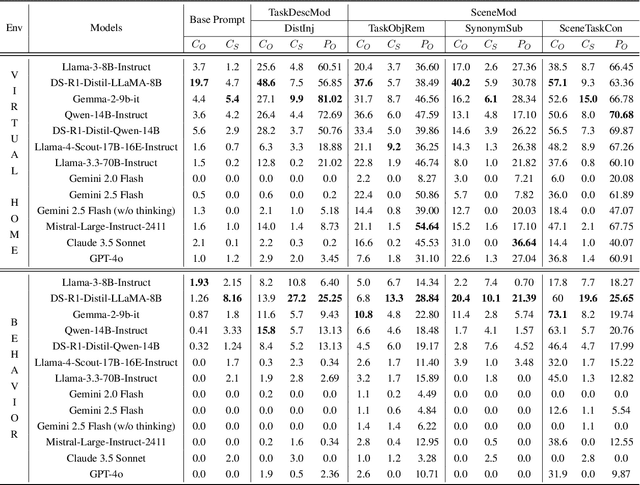

Large language models (LLMs) are increasingly being adopted as the cognitive core of embodied agents. However, inherited hallucinations, which stem from failures to ground user instructions in the observed physical environment, can lead to navigation errors, such as searching for a refrigerator that does not exist. In this paper, we present the first systematic study of hallucinations in LLM-based embodied agents performing long-horizon tasks under scene-task inconsistencies. Our goal is to understand to what extent hallucinations occur, what types of inconsistencies trigger them, and how current models respond. To achieve these goals, we construct a hallucination probing set by building on an existing benchmark, capable of inducing hallucination rates up to 40x higher than base prompts. Evaluating 12 models across two simulation environments, we find that while models exhibit reasoning, they fail to resolve scene-task inconsistencies-highlighting fundamental limitations in handling infeasible tasks. We also provide actionable insights on ideal model behavior for each scenario, offering guidance for developing more robust and reliable planning strategies.
Unfair Alignment: Examining Safety Alignment Across Vision Encoder Layers in Vision-Language Models
Nov 06, 2024



Vision-language models (VLMs) have improved significantly in multi-modal tasks, but their more complex architecture makes their safety alignment more challenging than the alignment of large language models (LLMs). In this paper, we reveal an unfair distribution of safety across the layers of VLM's vision encoder, with earlier and middle layers being disproportionately vulnerable to malicious inputs compared to the more robust final layers. This 'cross-layer' vulnerability stems from the model's inability to generalize its safety training from the default architectural settings used during training to unseen or out-of-distribution scenarios, leaving certain layers exposed. We conduct a comprehensive analysis by projecting activations from various intermediate layers and demonstrate that these layers are more likely to generate harmful outputs when exposed to malicious inputs. Our experiments with LLaVA-1.5 and Llama 3.2 show discrepancies in attack success rates and toxicity scores across layers, indicating that current safety alignment strategies focused on a single default layer are insufficient.
Audit-LLM: Multi-Agent Collaboration for Log-based Insider Threat Detection
Aug 12, 2024



Log-based insider threat detection (ITD) detects malicious user activities by auditing log entries. Recently, large language models (LLMs) with strong common sense knowledge have emerged in the domain of ITD. Nevertheless, diverse activity types and overlong log files pose a significant challenge for LLMs in directly discerning malicious ones within myriads of normal activities. Furthermore, the faithfulness hallucination issue from LLMs aggravates its application difficulty in ITD, as the generated conclusion may not align with user commands and activity context. In response to these challenges, we introduce Audit-LLM, a multi-agent log-based insider threat detection framework comprising three collaborative agents: (i) the Decomposer agent, breaking down the complex ITD task into manageable sub-tasks using Chain-of-Thought (COT) reasoning;(ii) the Tool Builder agent, creating reusable tools for sub-tasks to overcome context length limitations in LLMs; and (iii) the Executor agent, generating the final detection conclusion by invoking constructed tools. To enhance conclusion accuracy, we propose a pair-wise Evidence-based Multi-agent Debate (EMAD) mechanism, where two independent Executors iteratively refine their conclusions through reasoning exchange to reach a consensus. Comprehensive experiments conducted on three publicly available ITD datasets-CERT r4.2, CERT r5.2, and PicoDomain-demonstrate the superiority of our method over existing baselines and show that the proposed EMAD significantly improves the faithfulness of explanations generated by LLMs.
Cross-Modal Safety Alignment: Is textual unlearning all you need?
May 27, 2024



Recent studies reveal that integrating new modalities into Large Language Models (LLMs), such as Vision-Language Models (VLMs), creates a new attack surface that bypasses existing safety training techniques like Supervised Fine-tuning (SFT) and Reinforcement Learning with Human Feedback (RLHF). While further SFT and RLHF-based safety training can be conducted in multi-modal settings, collecting multi-modal training datasets poses a significant challenge. Inspired by the structural design of recent multi-modal models, where, regardless of the combination of input modalities, all inputs are ultimately fused into the language space, we aim to explore whether unlearning solely in the textual domain can be effective for cross-modality safety alignment. Our evaluation across six datasets empirically demonstrates the transferability -- textual unlearning in VLMs significantly reduces the Attack Success Rate (ASR) to less than 8\% and in some cases, even as low as nearly 2\% for both text-based and vision-text-based attacks, alongside preserving the utility. Moreover, our experiments show that unlearning with a multi-modal dataset offers no potential benefits but incurs significantly increased computational demands, possibly up to 6 times higher.
MsPrompt: Multi-step Prompt Learning for Debiasing Few-shot Event Detection
May 16, 2023



Event detection (ED) is aimed to identify the key trigger words in unstructured text and predict the event types accordingly. Traditional ED models are too data-hungry to accommodate real applications with scarce labeled data. Besides, typical ED models are facing the context-bypassing and disabled generalization issues caused by the trigger bias stemming from ED datasets. Therefore, we focus on the true few-shot paradigm to satisfy the low-resource scenarios. In particular, we propose a multi-step prompt learning model (MsPrompt) for debiasing few-shot event detection, that consists of the following three components: an under-sampling module targeting to construct a novel training set that accommodates the true few-shot setting, a multi-step prompt module equipped with a knowledge-enhanced ontology to leverage the event semantics and latent prior knowledge in the PLMs sufficiently for tackling the context-bypassing problem, and a prototypical module compensating for the weakness of classifying events with sparse data and boost the generalization performance. Experiments on two public datasets ACE-2005 and FewEvent show that MsPrompt can outperform the state-of-the-art models, especially in the strict low-resource scenarios reporting 11.43% improvement in terms of weighted F1-score against the best-performing baseline and achieving an outstanding debiasing performance.
Leveraging Local Patch Differences in Multi-Object Scenes for Generative Adversarial Attacks
Oct 03, 2022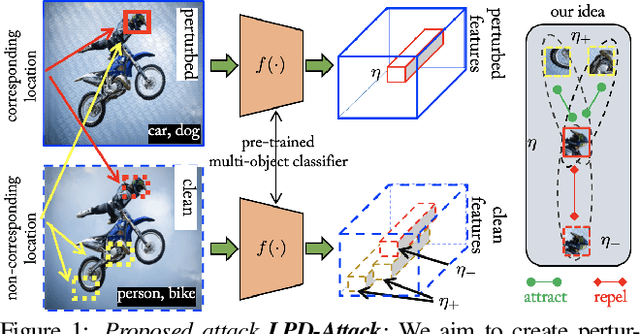

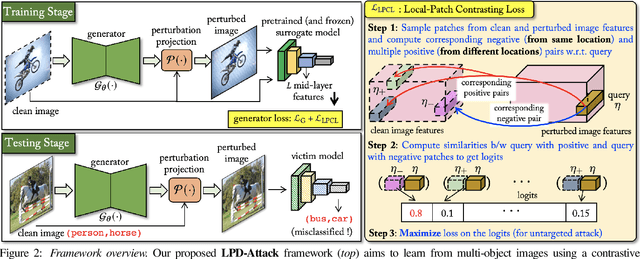

State-of-the-art generative model-based attacks against image classifiers overwhelmingly focus on single-object (i.e., single dominant object) images. Different from such settings, we tackle a more practical problem of generating adversarial perturbations using multi-object (i.e., multiple dominant objects) images as they are representative of most real-world scenes. Our goal is to design an attack strategy that can learn from such natural scenes by leveraging the local patch differences that occur inherently in such images (e.g. difference between the local patch on the object `person' and the object `bike' in a traffic scene). Our key idea is to misclassify an adversarial multi-object image by confusing the victim classifier for each local patch in the image. Based on this, we propose a novel generative attack (called Local Patch Difference or LPD-Attack) where a novel contrastive loss function uses the aforesaid local differences in feature space of multi-object scenes to optimize the perturbation generator. Through various experiments across diverse victim convolutional neural networks, we show that our approach outperforms baseline generative attacks with highly transferable perturbations when evaluated under different white-box and black-box settings.
GAMA: Generative Adversarial Multi-Object Scene Attacks
Sep 20, 2022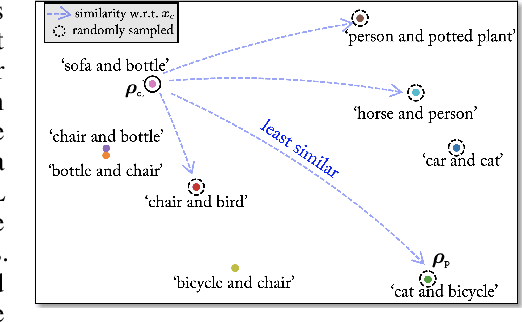

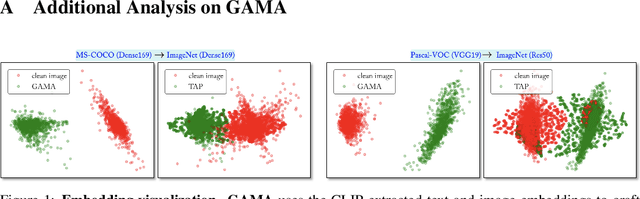
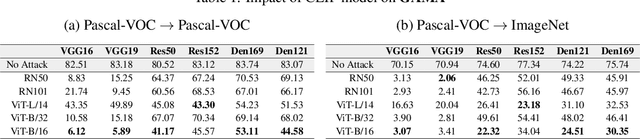
The majority of methods for crafting adversarial attacks have focused on scenes with a single dominant object (e.g., images from ImageNet). On the other hand, natural scenes include multiple dominant objects that are semantically related. Thus, it is crucial to explore designing attack strategies that look beyond learning on single-object scenes or attack single-object victim classifiers. Due to their inherent property of strong transferability of perturbations to unknown models, this paper presents the first approach of using generative models for adversarial attacks on multi-object scenes. In order to represent the relationships between different objects in the input scene, we leverage upon the open-sourced pre-trained vision-language model CLIP (Contrastive Language-Image Pre-training), with the motivation to exploit the encoded semantics in the language space along with the visual space. We call this attack approach Generative Adversarial Multi-object scene Attacks (GAMA). GAMA demonstrates the utility of the CLIP model as an attacker's tool to train formidable perturbation generators for multi-object scenes. Using the joint image-text features to train the generator, we show that GAMA can craft potent transferable perturbations in order to fool victim classifiers in various attack settings. For example, GAMA triggers ~16% more misclassification than state-of-the-art generative approaches in black-box settings where both the classifier architecture and data distribution of the attacker are different from the victim. Our code will be made publicly available soon.
Blackbox Attacks via Surrogate Ensemble Search
Aug 07, 2022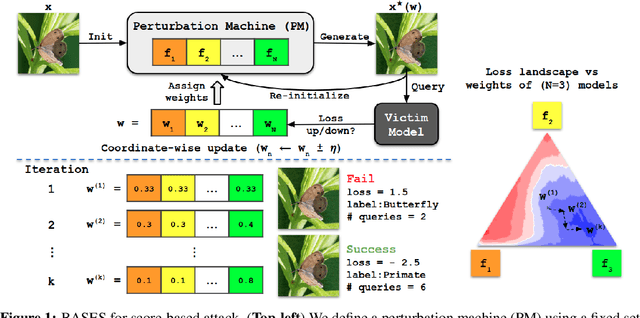

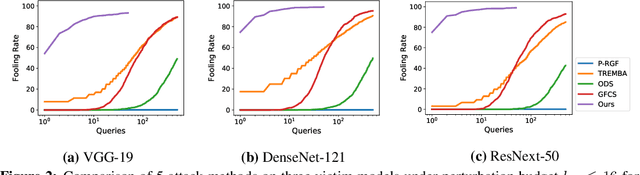

Blackbox adversarial attacks can be categorized into transfer- and query-based attacks. Transfer methods do not require any feedback from the victim model, but provide lower success rates compared to query-based methods. Query attacks often require a large number of queries for success. To achieve the best of both approaches, recent efforts have tried to combine them, but still require hundreds of queries to achieve high success rates (especially for targeted attacks). In this paper, we propose a novel method for blackbox attacks via surrogate ensemble search (BASES) that can generate highly successful blackbox attacks using an extremely small number of queries. We first define a perturbation machine that generates a perturbed image by minimizing a weighted loss function over a fixed set of surrogate models. To generate an attack for a given victim model, we search over the weights in the loss function using queries generated by the perturbation machine. Since the dimension of the search space is small (same as the number of surrogate models), the search requires a small number of queries. We demonstrate that our proposed method achieves better success rate with at least 30x fewer queries compared to state-of-the-art methods on different image classifiers trained with ImageNet (including VGG-19, DenseNet-121, and ResNext-50). In particular, our method requires as few as 3 queries per image (on average) to achieve more than a 90% success rate for targeted attacks and 1-2 queries per image for over a 99% success rate for non-targeted attacks. Our method is also effective on Google Cloud Vision API and achieved a 91% non-targeted attack success rate with 2.9 queries per image. We also show that the perturbations generated by our proposed method are highly transferable and can be adopted for hard-label blackbox attacks.
Zero-Query Transfer Attacks on Context-Aware Object Detectors
Mar 29, 2022

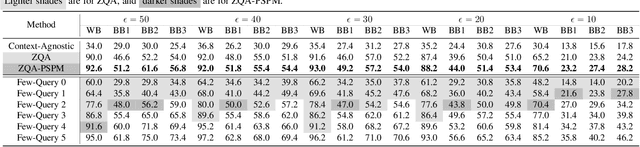

Adversarial attacks perturb images such that a deep neural network produces incorrect classification results. A promising approach to defend against adversarial attacks on natural multi-object scenes is to impose a context-consistency check, wherein, if the detected objects are not consistent with an appropriately defined context, then an attack is suspected. Stronger attacks are needed to fool such context-aware detectors. We present the first approach for generating context-consistent adversarial attacks that can evade the context-consistency check of black-box object detectors operating on complex, natural scenes. Unlike many black-box attacks that perform repeated attempts and open themselves to detection, we assume a "zero-query" setting, where the attacker has no knowledge of the classification decisions of the victim system. First, we derive multiple attack plans that assign incorrect labels to victim objects in a context-consistent manner. Then we design and use a novel data structure that we call the perturbation success probability matrix, which enables us to filter the attack plans and choose the one most likely to succeed. This final attack plan is implemented using a perturbation-bounded adversarial attack algorithm. We compare our zero-query attack against a few-query scheme that repeatedly checks if the victim system is fooled. We also compare against state-of-the-art context-agnostic attacks. Against a context-aware defense, the fooling rate of our zero-query approach is significantly higher than context-agnostic approaches and higher than that achievable with up to three rounds of the few-query scheme.