 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAACR-Bench: Evaluating Automatic Code Review with Holistic Repository-Level Context
Jan 27, 2026High-quality evaluation benchmarks are pivotal for deploying Large Language Models (LLMs) in Automated Code Review (ACR). However, existing benchmarks suffer from two critical limitations: first, the lack of multi-language support in repository-level contexts, which restricts the generalizability of evaluation results; second, the reliance on noisy, incomplete ground truth derived from raw Pull Request (PR) comments, which constrains the scope of issue detection. To address these challenges, we introduce AACR-Bench a comprehensive benchmark that provides full cross-file context across multiple programming languages. Unlike traditional datasets, AACR-Bench employs an "AI-assisted, Expert-verified" annotation pipeline to uncover latent defects often overlooked in original PRs, resulting in a 285\% increase in defect coverage. Extensive evaluations of mainstream LLMs on AACR-Bench reveal that previous assessments may have either misjudged or only partially captured model capabilities due to data limitations. Our work establishes a more rigorous standard for ACR evaluation and offers new insights on LLM based ACR, i.e., the granularity/level of context and the choice of retrieval methods significantly impact ACR performance, and this influence varies depending on the LLM, programming language, and the LLM usage paradigm e.g., whether an Agent architecture is employed. The code, data, and other artifacts of our evaluation set are available at https://github.com/alibaba/aacr-bench .
Audit-LLM: Multi-Agent Collaboration for Log-based Insider Threat Detection
Aug 12, 2024



Log-based insider threat detection (ITD) detects malicious user activities by auditing log entries. Recently, large language models (LLMs) with strong common sense knowledge have emerged in the domain of ITD. Nevertheless, diverse activity types and overlong log files pose a significant challenge for LLMs in directly discerning malicious ones within myriads of normal activities. Furthermore, the faithfulness hallucination issue from LLMs aggravates its application difficulty in ITD, as the generated conclusion may not align with user commands and activity context. In response to these challenges, we introduce Audit-LLM, a multi-agent log-based insider threat detection framework comprising three collaborative agents: (i) the Decomposer agent, breaking down the complex ITD task into manageable sub-tasks using Chain-of-Thought (COT) reasoning;(ii) the Tool Builder agent, creating reusable tools for sub-tasks to overcome context length limitations in LLMs; and (iii) the Executor agent, generating the final detection conclusion by invoking constructed tools. To enhance conclusion accuracy, we propose a pair-wise Evidence-based Multi-agent Debate (EMAD) mechanism, where two independent Executors iteratively refine their conclusions through reasoning exchange to reach a consensus. Comprehensive experiments conducted on three publicly available ITD datasets-CERT r4.2, CERT r5.2, and PicoDomain-demonstrate the superiority of our method over existing baselines and show that the proposed EMAD significantly improves the faithfulness of explanations generated by LLMs.
Macro action selection with deep reinforcement learning in StarCraft
Dec 02, 2018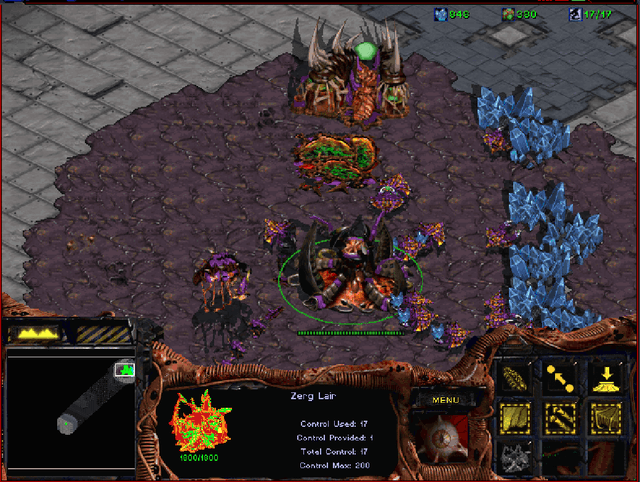

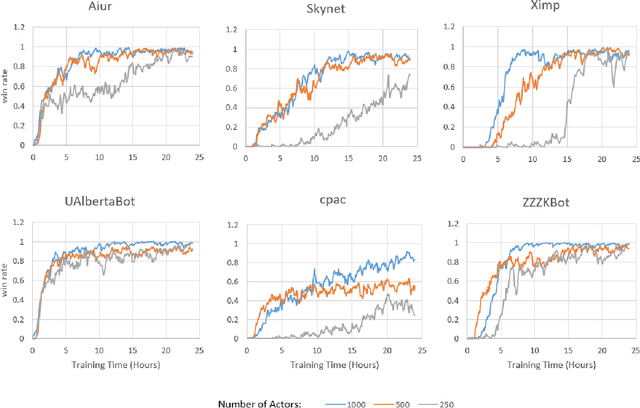
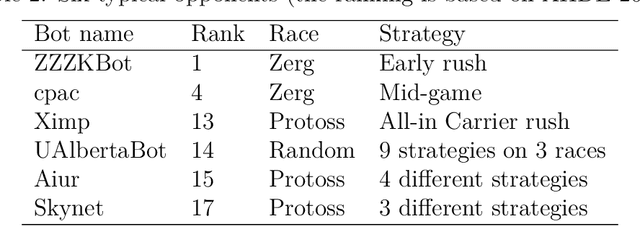
StarCraft (SC) is one of the most popular and successful Real Time Strategy (RTS) games. In recent years, SC is also considered as a testbed for AI research, due to its enormous state space, hidden information, multi-agent collaboration and so on. Thanks to the annual AIIDE and CIG competitions, a growing number of bots are proposed and being continuously improved. However, a big gap still remains between the top bot and the professional human players. One vital reason is that current bots mainly rely on predefined rules to perform macro actions. These rules are not scalable and efficient enough to cope with the large but partially observed macro state space in SC. In this paper, we propose a DRL based framework to do macro action selection. Our framework combines the reinforcement learning approach Ape-X DQN with Long-Short-Term-Memory (LSTM) to improve the macro action selection in bot. We evaluate our bot, named as LastOrder, on the AIIDE 2017 StarCraft AI competition bots set. Our bot achieves overall 83% win-rate, outperforming 26 bots in total 28 entrants.