 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC$^{2}$TC: A Training-Free Framework for Efficient Tabular Data Condensation
Feb 25, 2026Tabular data is the primary data format in industrial relational databases, underpinning modern data analytics and decision-making. However, the increasing scale of tabular data poses significant computational and storage challenges to learning-based analytical systems. This highlights the need for data-efficient learning, which enables effective model training and generalization using substantially fewer samples. Dataset condensation (DC) has emerged as a promising data-centric paradigm that synthesizes small yet informative datasets to preserve data utility while reducing storage and training costs. However, existing DC methods are computationally intensive due to reliance on complex gradient-based optimization. Moreover, they often overlook key characteristics of tabular data, such as heterogeneous features and class imbalance. To address these limitations, we introduce C$^{2}$TC (Class-Adaptive Clustering for Tabular Condensation), the first training-free tabular dataset condensation framework that jointly optimizes class allocation and feature representation, enabling efficient and scalable condensation. Specifically, we reformulate the dataset condensation objective into a novel class-adaptive cluster allocation problem (CCAP), which eliminates costly training and integrates adaptive label allocation to handle class imbalance. To solve the NP-hard CCAP, we develop HFILS, a heuristic local search that alternates between soft allocation and class-wise clustering to efficiently obtain high-quality solutions. Moreover, a hybrid categorical feature encoding (HCFE) is proposed for semantics-preserving clustering of heterogeneous discrete attributes. Extensive experiments on 10 real-world datasets demonstrate that C$^{2}$TC improves efficiency by at least 2 orders of magnitude over state-of-the-art baselines, while achieving superior downstream performance.
Linking Heterogeneous Data with Coordinated Agent Flows for Social Media Analysis
Oct 30, 2025Social media platforms generate massive volumes of heterogeneous data, capturing user behaviors, textual content, temporal dynamics, and network structures. Analyzing such data is crucial for understanding phenomena such as opinion dynamics, community formation, and information diffusion. However, discovering insights from this complex landscape is exploratory, conceptually challenging, and requires expertise in social media mining and visualization. Existing automated approaches, though increasingly leveraging large language models (LLMs), remain largely confined to structured tabular data and cannot adequately address the heterogeneity of social media analysis. We present SIA (Social Insight Agents), an LLM agent system that links heterogeneous multi-modal data -- including raw inputs (e.g., text, network, and behavioral data), intermediate outputs, mined analytical results, and visualization artifacts -- through coordinated agent flows. Guided by a bottom-up taxonomy that connects insight types with suitable mining and visualization techniques, SIA enables agents to plan and execute coherent analysis strategies. To ensure multi-modal integration, it incorporates a data coordinator that unifies tabular, textual, and network data into a consistent flow. Its interactive interface provides a transparent workflow where users can trace, validate, and refine the agent's reasoning, supporting both adaptability and trustworthiness. Through expert-centered case studies and quantitative evaluation, we show that SIA effectively discovers diverse and meaningful insights from social media while supporting human-agent collaboration in complex analytical tasks.
Diversity is Strength: Mastering Football Full Game with Interactive Reinforcement Learning of Multiple AIs
Jun 28, 2023

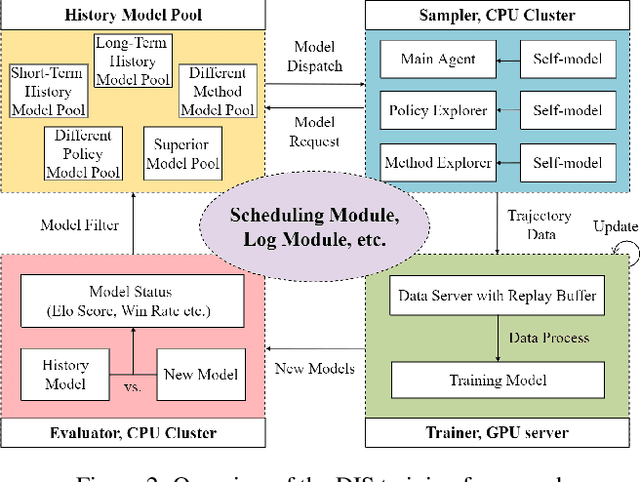
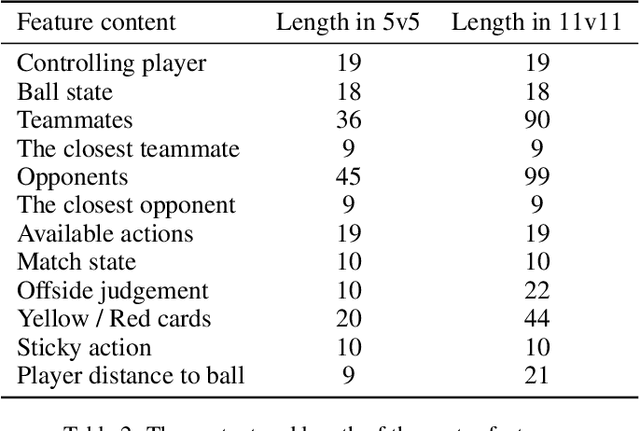
Training AI with strong and rich strategies in multi-agent environments remains an important research topic in Deep Reinforcement Learning (DRL). The AI's strength is closely related to its diversity of strategies, and this relationship can guide us to train AI with both strong and rich strategies. To prove this point, we propose Diversity is Strength (DIS), a novel DRL training framework that can simultaneously train multiple kinds of AIs. These AIs are linked through an interconnected history model pool structure, which enhances their capabilities and strategy diversities. We also design a model evaluation and screening scheme to select the best models to enrich the model pool and obtain the final AI. The proposed training method provides diverse, generalizable, and strong AI strategies without using human data. We tested our method in an AI competition based on Google Research Football (GRF) and won the 5v5 and 11v11 tracks. The method enables a GRF AI to have a high level on both 5v5 and 11v11 tracks for the first time, which are under complex multi-agent environments. The behavior analysis shows that the trained AI has rich strategies, and the ablation experiments proved that the designed modules benefit the training process.
Mastering Asymmetrical Multiplayer Game with Multi-Agent Asymmetric-Evolution Reinforcement Learning
Apr 20, 2023Asymmetrical multiplayer (AMP) game is a popular game genre which involves multiple types of agents competing or collaborating with each other in the game. It is difficult to train powerful agents that can defeat top human players in AMP games by typical self-play training method because of unbalancing characteristics in their asymmetrical environments. We propose asymmetric-evolution training (AET), a novel multi-agent reinforcement learning framework that can train multiple kinds of agents simultaneously in AMP game. We designed adaptive data adjustment (ADA) and environment randomization (ER) to optimize the AET process. We tested our method in a complex AMP game named Tom \& Jerry, and our AIs trained without using any human data can achieve a win rate of 98.5% against top human players over 65 matches. The ablation experiments indicated that the proposed modules are beneficial to the framework.
Macro action selection with deep reinforcement learning in StarCraft
Dec 02, 2018

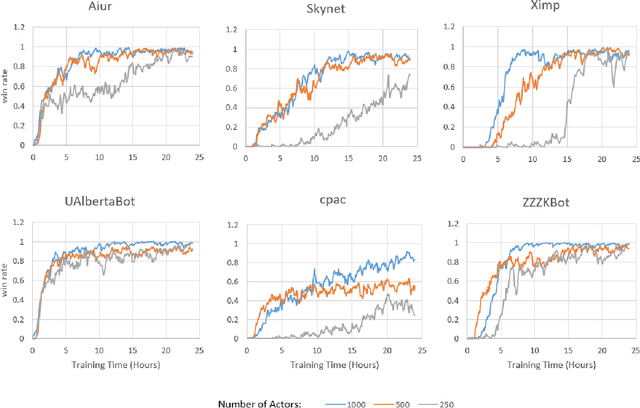
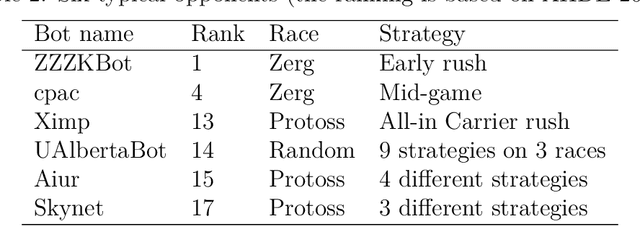
StarCraft (SC) is one of the most popular and successful Real Time Strategy (RTS) games. In recent years, SC is also considered as a testbed for AI research, due to its enormous state space, hidden information, multi-agent collaboration and so on. Thanks to the annual AIIDE and CIG competitions, a growing number of bots are proposed and being continuously improved. However, a big gap still remains between the top bot and the professional human players. One vital reason is that current bots mainly rely on predefined rules to perform macro actions. These rules are not scalable and efficient enough to cope with the large but partially observed macro state space in SC. In this paper, we propose a DRL based framework to do macro action selection. Our framework combines the reinforcement learning approach Ape-X DQN with Long-Short-Term-Memory (LSTM) to improve the macro action selection in bot. We evaluate our bot, named as LastOrder, on the AIIDE 2017 StarCraft AI competition bots set. Our bot achieves overall 83% win-rate, outperforming 26 bots in total 28 entrants.