 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMastering the Game of Go with Self-play Experience Replay
Jan 06, 2026The game of Go has long served as a benchmark for artificial intelligence, demanding sophisticated strategic reasoning and long-term planning. Previous approaches such as AlphaGo and its successors, have predominantly relied on model-based Monte-Carlo Tree Search (MCTS). In this work, we present QZero, a novel model-free reinforcement learning algorithm that forgoes search during training and learns a Nash equilibrium policy through self-play and off-policy experience replay. Built upon entropy-regularized Q-learning, QZero utilizes a single Q-value network to unify policy evaluation and improvement. Starting tabula rasa without human data and trained for 5 months with modest compute resources (7 GPUs), QZero achieved a performance level comparable to that of AlphaGo. This demonstrates, for the first time, the efficiency of using model-free reinforcement learning to master the game of Go, as well as the feasibility of off-policy reinforcement learning in solving large-scale and complex environments.
GMS-VINS:Multi-category Dynamic Objects Semantic Segmentation for Enhanced Visual-Inertial Odometry Using a Promptable Foundation Model
Nov 28, 2024

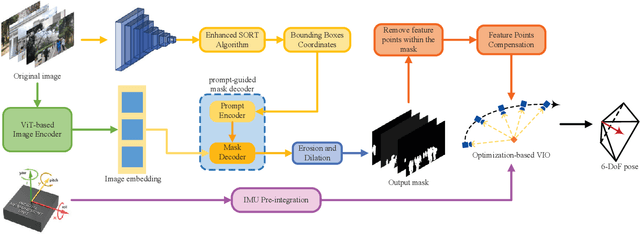
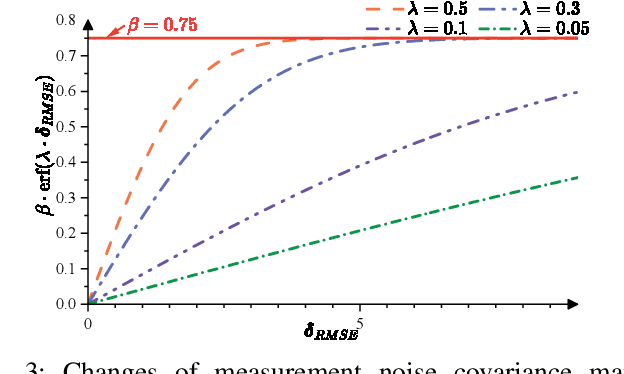
Visual-inertial odometry (VIO) is widely used in various fields, such as robots, drones, and autonomous vehicles, due to its low cost and complementary sensors. Most VIO methods presuppose that observed objects are static and time-invariant. However, real-world scenes often feature dynamic objects, compromising the accuracy of pose estimation. These moving entities include cars, trucks, buses, motorcycles, and pedestrians. The diversity and partial occlusion of these objects present a tough challenge for existing dynamic object removal techniques. To tackle this challenge, we introduce GMS-VINS, which integrates an enhanced SORT algorithm along with a robust multi-category segmentation framework into VIO, thereby improving pose estimation accuracy in environments with diverse dynamic objects and frequent occlusions. Leveraging the promptable foundation model, our solution efficiently tracks and segments a wide range of object categories. The enhanced SORT algorithm significantly improves the reliability of tracking multiple dynamic objects, especially in urban settings with partial occlusions or swift movements. We evaluated our proposed method using multiple public datasets representing various scenes, as well as in a real-world scenario involving diverse dynamic objects. The experimental results demonstrate that our proposed method performs impressively in multiple scenarios, outperforming other state-of-the-art methods. This highlights its remarkable generalization and adaptability in diverse dynamic environments, showcasing its potential to handle various dynamic objects in practical applications.
Mastering Asymmetrical Multiplayer Game with Multi-Agent Asymmetric-Evolution Reinforcement Learning
Apr 20, 2023Asymmetrical multiplayer (AMP) game is a popular game genre which involves multiple types of agents competing or collaborating with each other in the game. It is difficult to train powerful agents that can defeat top human players in AMP games by typical self-play training method because of unbalancing characteristics in their asymmetrical environments. We propose asymmetric-evolution training (AET), a novel multi-agent reinforcement learning framework that can train multiple kinds of agents simultaneously in AMP game. We designed adaptive data adjustment (ADA) and environment randomization (ER) to optimize the AET process. We tested our method in a complex AMP game named Tom \& Jerry, and our AIs trained without using any human data can achieve a win rate of 98.5% against top human players over 65 matches. The ablation experiments indicated that the proposed modules are beneficial to the framework.
A Method of Generating Measurable Panoramic Image for Indoor Mobile Measurement System
Oct 27, 2020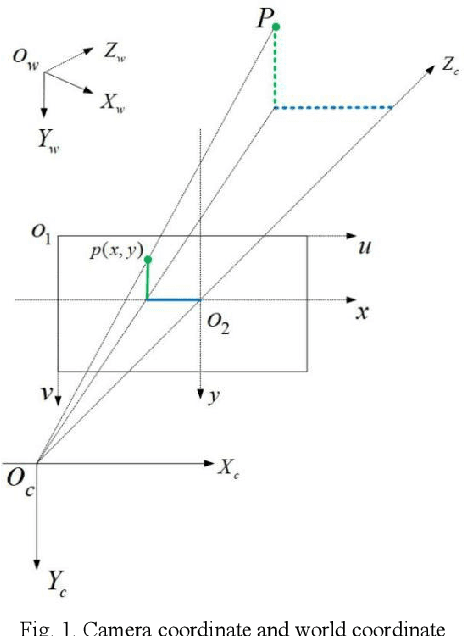
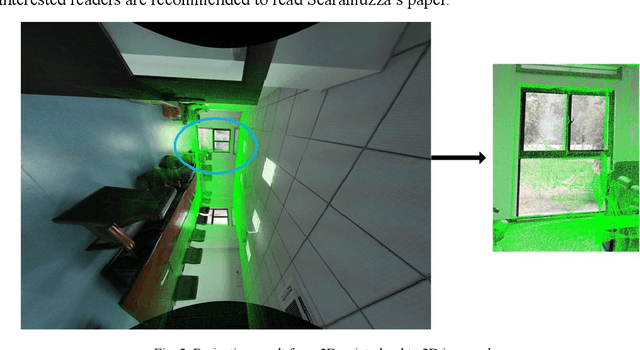

This paper designs a technique route to generate high-quality panoramic image with depth information, which involves two critical research hotspots: fusion of LiDAR and image data and image stitching. For the fusion of 3D points and image data, since a sparse depth map can be firstly generated by projecting LiDAR point onto the RGB image plane based on our reliable calibrated and synchronized sensors, we adopt a parameter self-adaptive framework to produce 2D dense depth map. For image stitching, optimal seamline for the overlapping area is searched using a graph-cuts-based method to alleviate the geometric influence and image blending based on the pyramid multi-band is utilized to eliminate the photometric effects near the stitching line. Since each pixel is associated with a depth value, we design this depth value as a radius in the spherical projection which can further project the panoramic image to the world coordinate and consequently produces a high-quality measurable panoramic image. The purposed method is tested on the data from our data collection platform and presents a satisfactory application prospects.
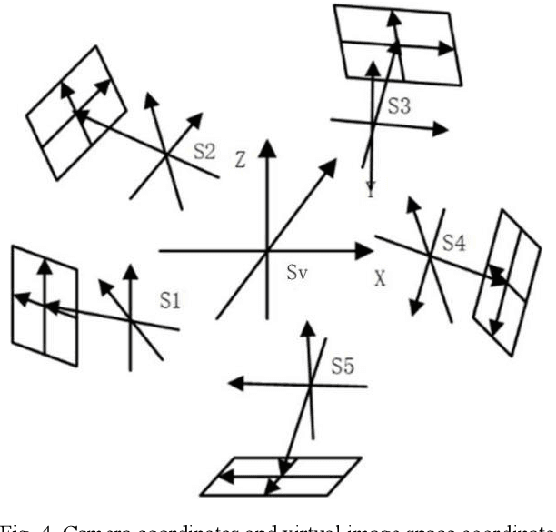
A Simple and Efficient Registration of 3D Point Cloud and Image Data for Indoor Mobile Mapping System
Oct 27, 2020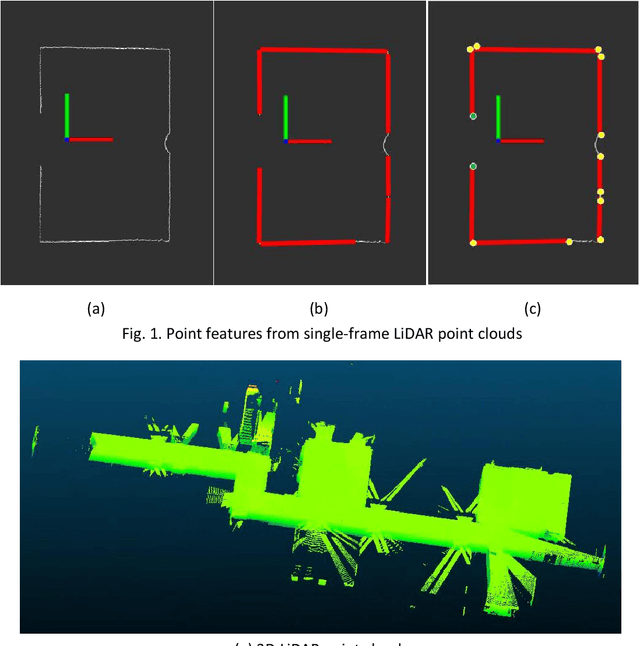


Registration of 3D LiDAR point clouds with optical images is critical in the combination of multi-source data. Geometric misalignment originally exists in the pose data between LiDAR point clouds and optical images. To improve the accuracy of the initial pose and the applicability of the integration of 3D points and image data, we develop a simple but efficient registration method. We firstly extract point features from LiDAR point clouds and images: point features is extracted from single-frame LiDAR and point features from images using classical Canny method. Cost map is subsequently built based on Canny image edge detection. The optimization direction is guided by the cost map where low cost represents the the desired direction, and loss function is also considered to improve the robustness of the the purposed method. Experiments show pleasant results.
M^3VSNet: Unsupervised Multi-metric Multi-view Stereo Network
May 28, 2020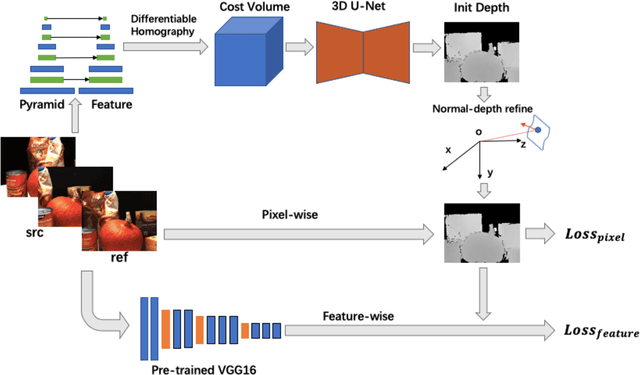
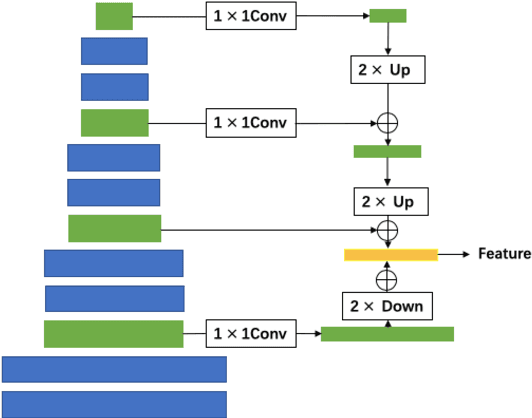
The present Multi-view stereo (MVS) methods with supervised learning-based networks have an impressive performance comparing with traditional MVS methods. However, the ground-truth depth maps for training are hard to be obtained and are within limited kinds of scenarios. In this paper, we propose a novel unsupervised multi-metric MVS network, named M^3VSNet, for dense point cloud reconstruction without any supervision. To improve the robustness and completeness of point cloud reconstruction, we propose a novel multi-metric loss function that combines pixel-wise and feature-wise loss function to learn the inherent constraints from different perspectives of matching correspondences. Besides, we also incorporate the normal-depth consistency in the 3D point cloud format to improve the accuracy and continuity of the estimated depth maps. Experimental results show that M3VSNet establishes the state-of-the-arts unsupervised method and achieves comparable performance with previous supervised MVSNet on the DTU dataset and demonstrates the powerful generalization ability on the Tanks and Temples benchmark with effective improvement. Our code is available at https://github.com/whubaichuan/M3VSNet.
CAE-LO: LiDAR Odometry Leveraging Fully Unsupervised Convolutional Auto-Encoder for Interest Point Detection and Feature Description
Jan 12, 2020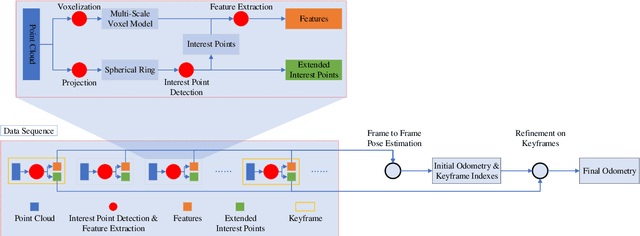

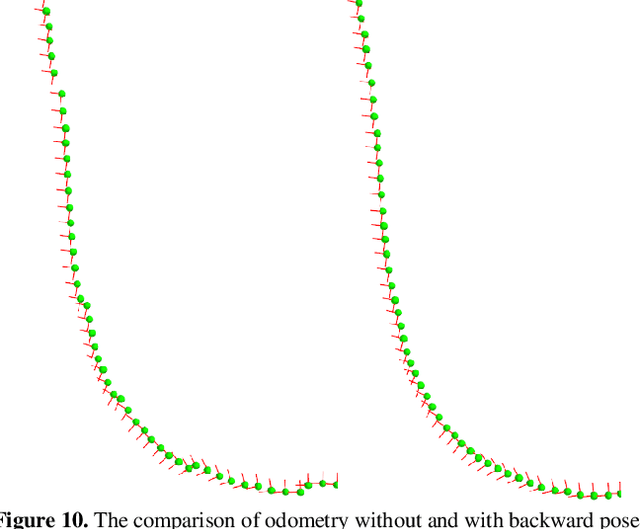
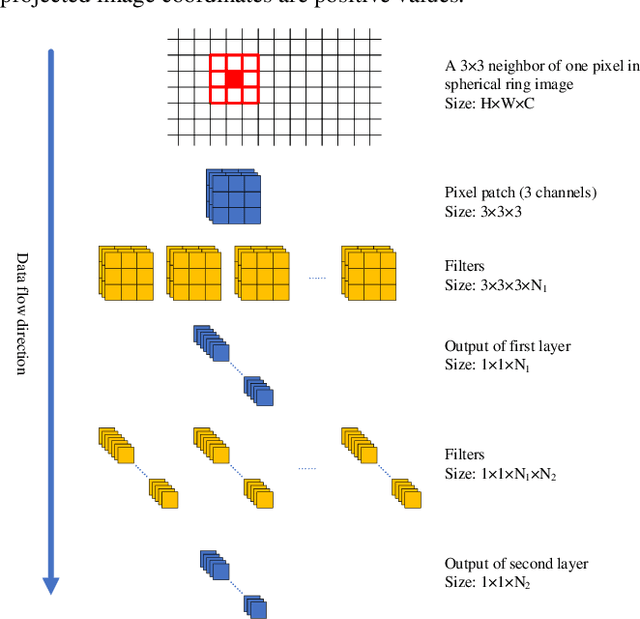
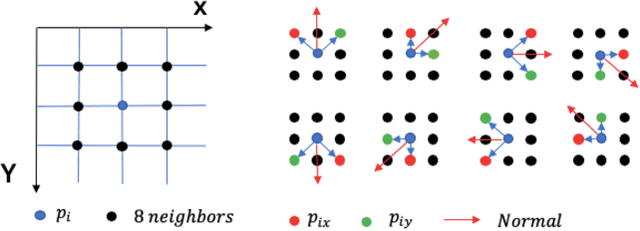
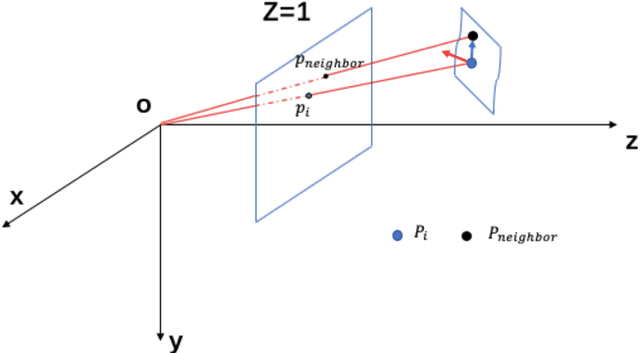
As an important technology in 3D mapping, autonomous driving, and robot navigation, LiDAR odometry is still a challenging task. Appropriate data structure and unsupervised deep learning are the keys to achieve an easy adjusted LiDAR odometry solution with high performance. Utilizing compact 2D structured spherical ring projection model and voxel model which preserves the original shape of input data, we propose a fully unsupervised Convolutional Auto-Encoder based LiDAR Odometry (CAE-LO) that detects interest points from spherical ring data using 2D CAE and extracts features from multi-resolution voxel model using 3D CAE. We make several key contributions: 1) experiments based on KITTI dataset show that our interest points can capture more local details to improve the matching success rate on unstructured scenarios and our features outperform state-of-the-art by more than 50% in matching inlier ratio; 2) besides, we also propose a keyframe selection method based on matching pairs transferring, an odometry refinement method for keyframes based on extended interest points from spherical rings, and a backward pose update method. The odometry refinement experiments verify the proposed ideas' feasibility and effectiveness.
On-policy Reinforcement Learning with Entropy Regularization
Dec 20, 2019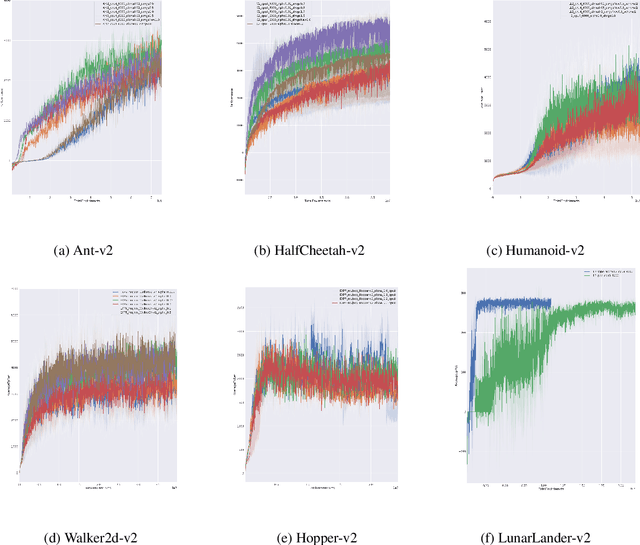
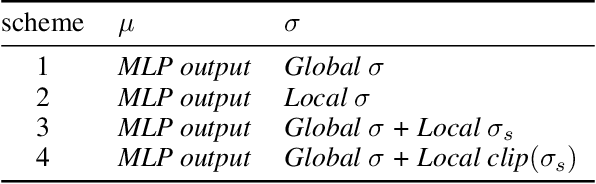
Entropy regularization is an imported idea in reinforcement learning, with great success in recent algorithms like Soft Actor Critic and Soft Q Network. In this work we extend this idea into the on-policy realm. With the soft gradient policy theorem, we construct the maximum entropy reinforcement learning framework for on-policy RL. For policy gradient based on-policy algorithms, policy network is often represented as Gaussian distribution with the action variance restricted to be global for all the states observed from the environment. We propose an idea called action variance scale for policy network and find it can work collaboratively with the idea of entropy regularization. In this paper, we choose the state-of-the-art on-policy algorithm, Proximal Policy Optimization, as our basal algorithm and present Soft Proximal Policy Optimization (SPPO). PPO is a popular on-policy RL algorithm with great stability and parallelism. But like many on-policy algorithm, PPO can also suffer from low sample efficiency and local optimum problem. In the entropy-regularized framework, SPPO can guide the agent to succeed at the task while maintaining exploration by acting as randomly as possible. Our method outperforms prior works on a range of continuous control benchmark tasks, Furthermore, our method can be easily extended to large scale experiment and achieve stable learning at high throughput.
Soft Q-network
Dec 20, 2019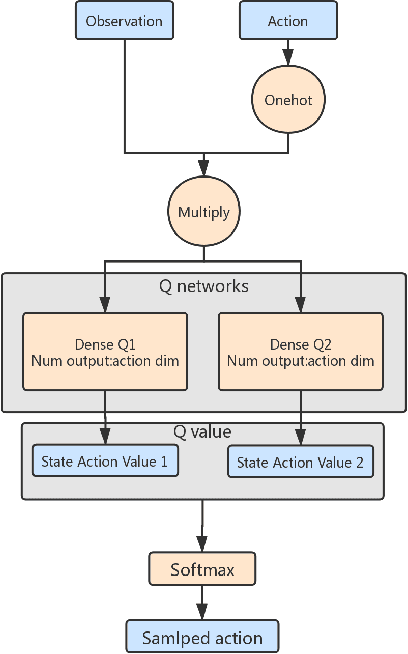
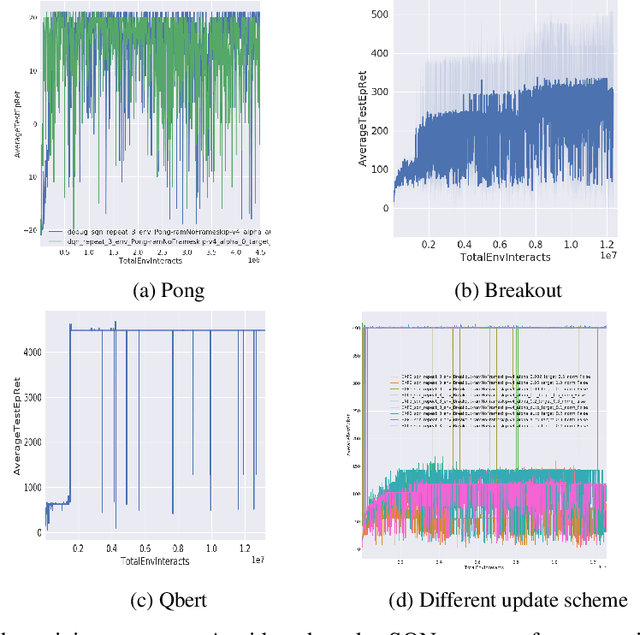
When DQN is announced by deepmind in 2013, the whole world is surprised by the simplicity and promising result, but due to the low efficiency and stability of this method, it is hard to solve many problems. After all these years, people purposed more and more complicated ideas for improving, many of them use distributed Deep-RL which needs tons of cores to run the simulators. However, the basic ideas behind all this technique are sometimes just a modified DQN. So we asked a simple question, is there a more elegant way to improve the DQN model? Instead of adding more and more small fixes on it, we redesign the problem setting under a popular entropy regularization framework which leads to better performance and theoretical guarantee. Finally, we purposed SQN, a new off-policy algorithm with better performance and stability.