 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-Resilient Symbolic Regression with Dynamic Gating Reinforcement Learning
Jan 02, 2025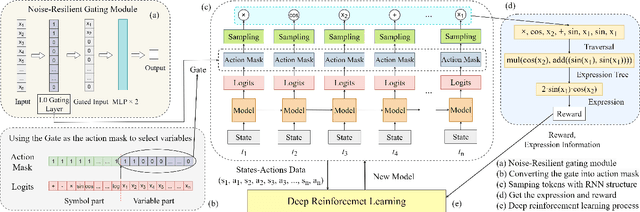
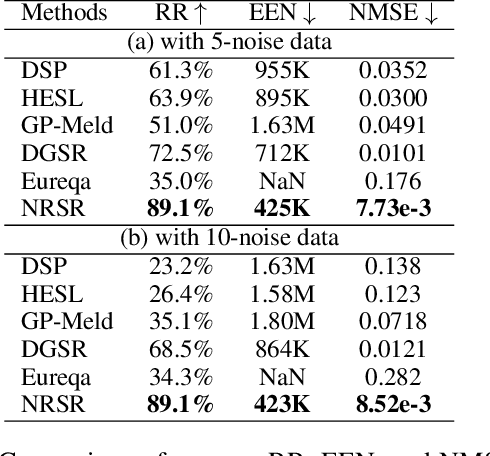
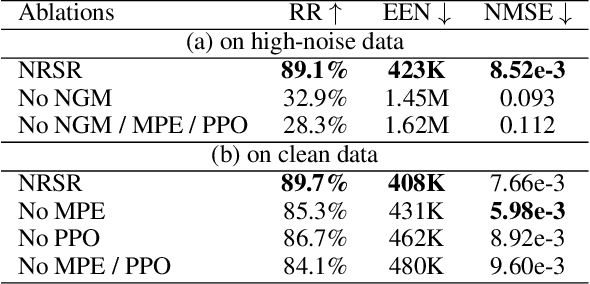
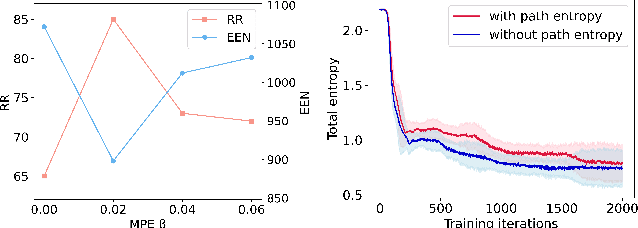
Symbolic regression (SR) has emerged as a pivotal technique for uncovering the intrinsic information within data and enhancing the interpretability of AI models. However, current state-of-the-art (sota) SR methods struggle to perform correct recovery of symbolic expressions from high-noise data. To address this issue, we introduce a novel noise-resilient SR (NRSR) method capable of recovering expressions from high-noise data. Our method leverages a novel reinforcement learning (RL) approach in conjunction with a designed noise-resilient gating module (NGM) to learn symbolic selection policies. The gating module can dynamically filter the meaningless information from high-noise data, thereby demonstrating a high noise-resilient capability for the SR process. And we also design a mixed path entropy (MPE) bonus term in the RL process to increase the exploration capabilities of the policy. Experimental results demonstrate that our method significantly outperforms several popular baselines on benchmarks with high-noise data. Furthermore, our method also can achieve sota performance on benchmarks with clean data, showcasing its robustness and efficacy in SR tasks.
Diversity is Strength: Mastering Football Full Game with Interactive Reinforcement Learning of Multiple AIs
Jun 28, 2023

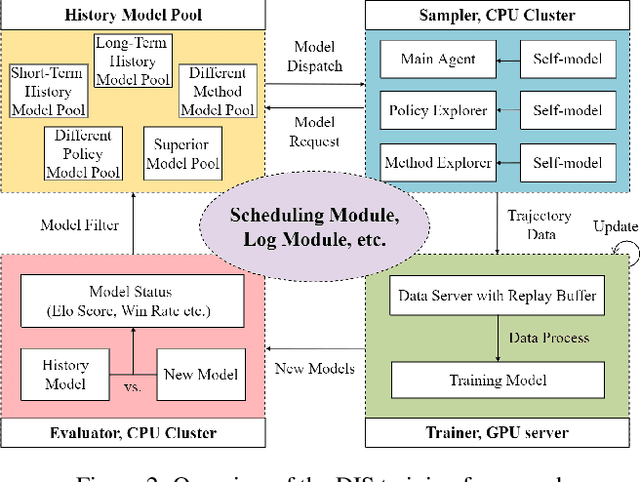
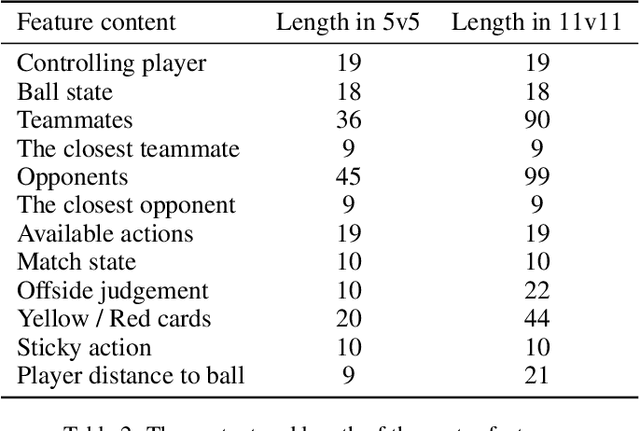
Training AI with strong and rich strategies in multi-agent environments remains an important research topic in Deep Reinforcement Learning (DRL). The AI's strength is closely related to its diversity of strategies, and this relationship can guide us to train AI with both strong and rich strategies. To prove this point, we propose Diversity is Strength (DIS), a novel DRL training framework that can simultaneously train multiple kinds of AIs. These AIs are linked through an interconnected history model pool structure, which enhances their capabilities and strategy diversities. We also design a model evaluation and screening scheme to select the best models to enrich the model pool and obtain the final AI. The proposed training method provides diverse, generalizable, and strong AI strategies without using human data. We tested our method in an AI competition based on Google Research Football (GRF) and won the 5v5 and 11v11 tracks. The method enables a GRF AI to have a high level on both 5v5 and 11v11 tracks for the first time, which are under complex multi-agent environments. The behavior analysis shows that the trained AI has rich strategies, and the ablation experiments proved that the designed modules benefit the training process.
Mastering Asymmetrical Multiplayer Game with Multi-Agent Asymmetric-Evolution Reinforcement Learning
Apr 20, 2023Asymmetrical multiplayer (AMP) game is a popular game genre which involves multiple types of agents competing or collaborating with each other in the game. It is difficult to train powerful agents that can defeat top human players in AMP games by typical self-play training method because of unbalancing characteristics in their asymmetrical environments. We propose asymmetric-evolution training (AET), a novel multi-agent reinforcement learning framework that can train multiple kinds of agents simultaneously in AMP game. We designed adaptive data adjustment (ADA) and environment randomization (ER) to optimize the AET process. We tested our method in a complex AMP game named Tom \& Jerry, and our AIs trained without using any human data can achieve a win rate of 98.5% against top human players over 65 matches. The ablation experiments indicated that the proposed modules are beneficial to the framework.