 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Humanoid Locomotion: Mastering Challenging Terrains with Denoising World Model Learning
Aug 26, 2024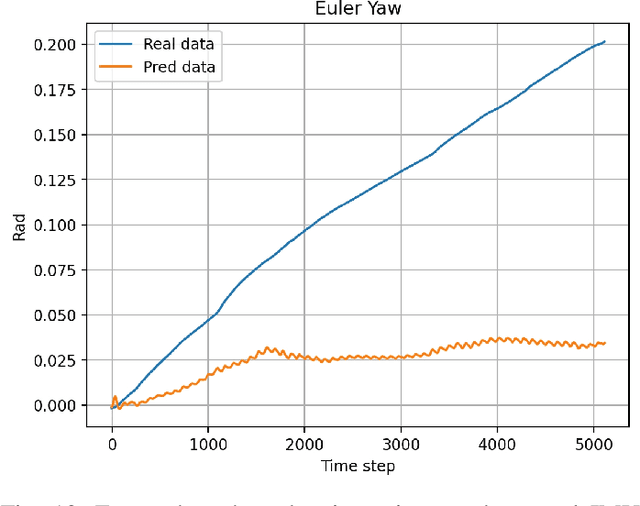
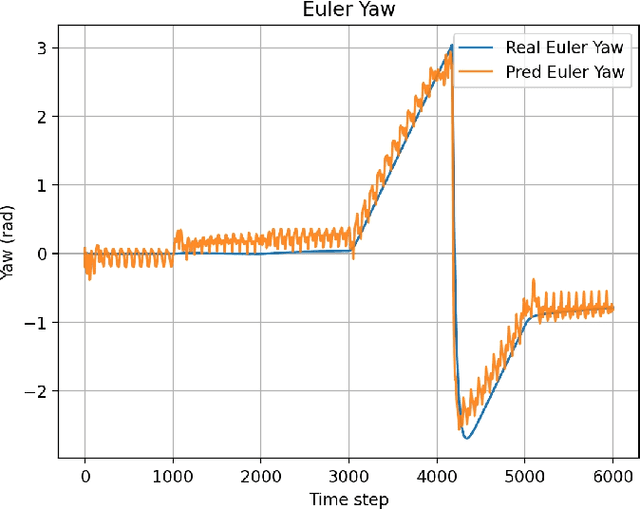
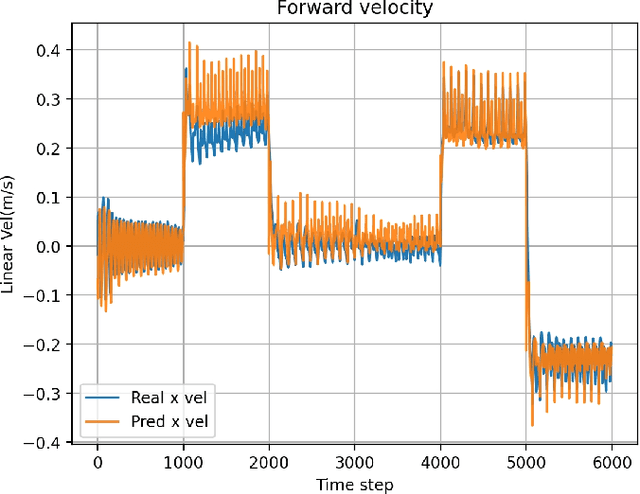
Humanoid robots, with their human-like skeletal structure, are especially suited for tasks in human-centric environments. However, this structure is accompanied by additional challenges in locomotion controller design, especially in complex real-world environments. As a result, existing humanoid robots are limited to relatively simple terrains, either with model-based control or model-free reinforcement learning. In this work, we introduce Denoising World Model Learning (DWL), an end-to-end reinforcement learning framework for humanoid locomotion control, which demonstrates the world's first humanoid robot to master real-world challenging terrains such as snowy and inclined land in the wild, up and down stairs, and extremely uneven terrains. All scenarios run the same learned neural network with zero-shot sim-to-real transfer, indicating the superior robustness and generalization capability of the proposed method.
Humanoid-Gym: Reinforcement Learning for Humanoid Robot with Zero-Shot Sim2Real Transfer
Apr 08, 2024



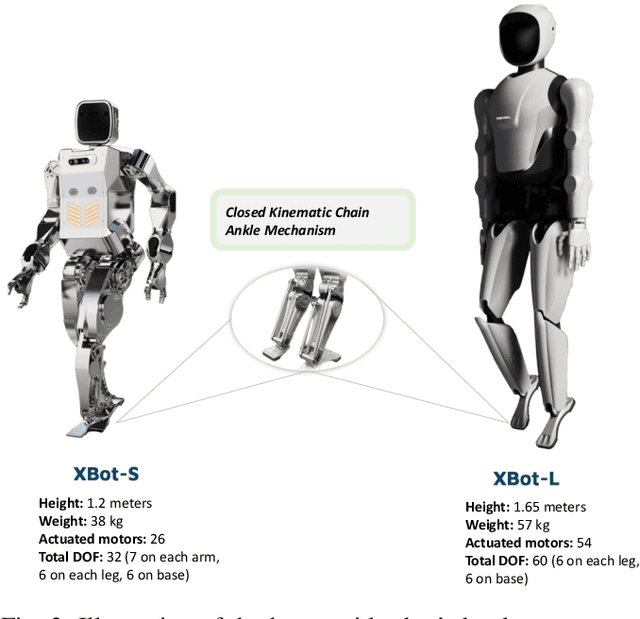
Humanoid-Gym is an easy-to-use reinforcement learning (RL) framework based on Nvidia Isaac Gym, designed to train locomotion skills for humanoid robots, emphasizing zero-shot transfer from simulation to the real-world environment. Humanoid-Gym also integrates a sim-to-sim framework from Isaac Gym to Mujoco that allows users to verify the trained policies in different physical simulations to ensure the robustness and generalization of the policies. This framework is verified by RobotEra's XBot-S (1.2-meter tall humanoid robot) and XBot-L (1.65-meter tall humanoid robot) in a real-world environment with zero-shot sim-to-real transfer. The project website and source code can be found at: https://sites.google.com/view/humanoid-gym/.
On-policy Reinforcement Learning with Entropy Regularization
Dec 20, 2019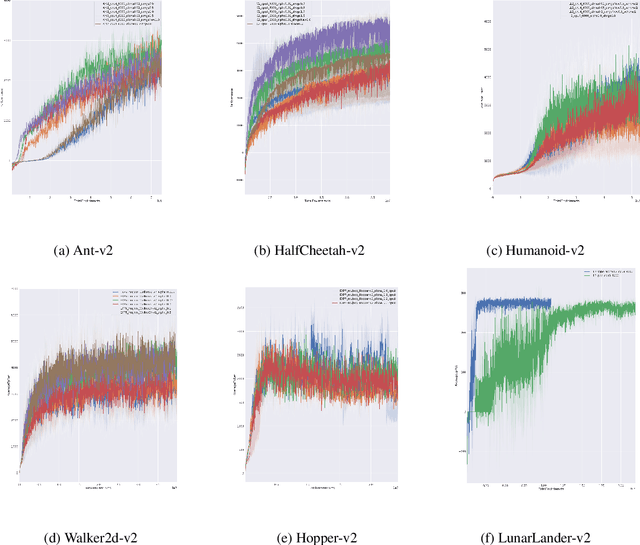
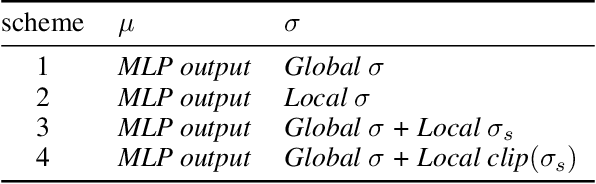
Entropy regularization is an imported idea in reinforcement learning, with great success in recent algorithms like Soft Actor Critic and Soft Q Network. In this work we extend this idea into the on-policy realm. With the soft gradient policy theorem, we construct the maximum entropy reinforcement learning framework for on-policy RL. For policy gradient based on-policy algorithms, policy network is often represented as Gaussian distribution with the action variance restricted to be global for all the states observed from the environment. We propose an idea called action variance scale for policy network and find it can work collaboratively with the idea of entropy regularization. In this paper, we choose the state-of-the-art on-policy algorithm, Proximal Policy Optimization, as our basal algorithm and present Soft Proximal Policy Optimization (SPPO). PPO is a popular on-policy RL algorithm with great stability and parallelism. But like many on-policy algorithm, PPO can also suffer from low sample efficiency and local optimum problem. In the entropy-regularized framework, SPPO can guide the agent to succeed at the task while maintaining exploration by acting as randomly as possible. Our method outperforms prior works on a range of continuous control benchmark tasks, Furthermore, our method can be easily extended to large scale experiment and achieve stable learning at high throughput.
Soft Q-network
Dec 20, 2019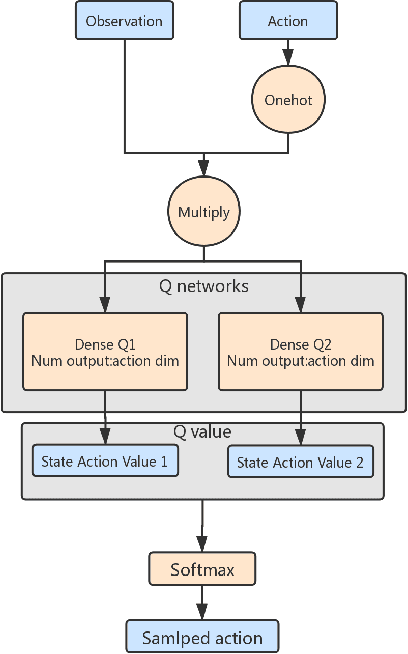
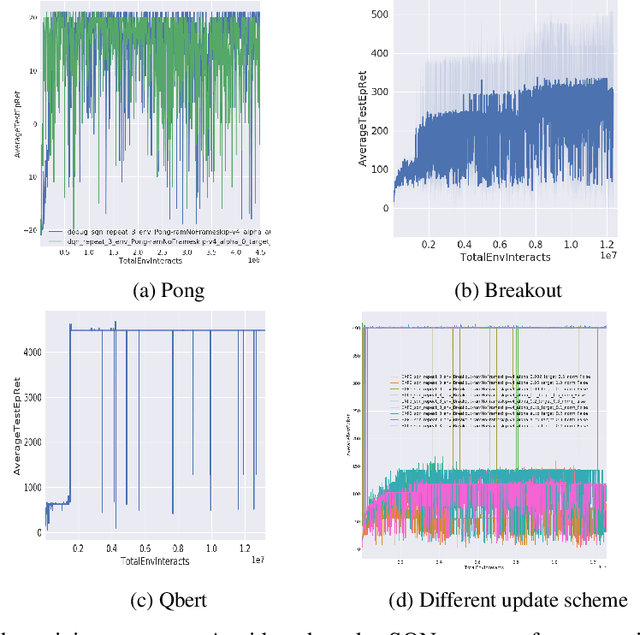
When DQN is announced by deepmind in 2013, the whole world is surprised by the simplicity and promising result, but due to the low efficiency and stability of this method, it is hard to solve many problems. After all these years, people purposed more and more complicated ideas for improving, many of them use distributed Deep-RL which needs tons of cores to run the simulators. However, the basic ideas behind all this technique are sometimes just a modified DQN. So we asked a simple question, is there a more elegant way to improve the DQN model? Instead of adding more and more small fixes on it, we redesign the problem setting under a popular entropy regularization framework which leads to better performance and theoretical guarantee. Finally, we purposed SQN, a new off-policy algorithm with better performance and stability.
High efficiency rl agent
Sep 11, 2019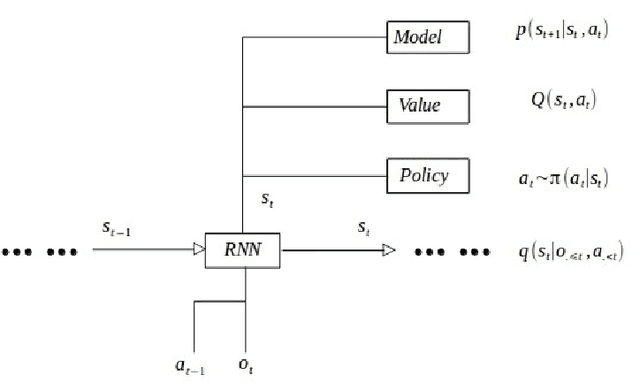

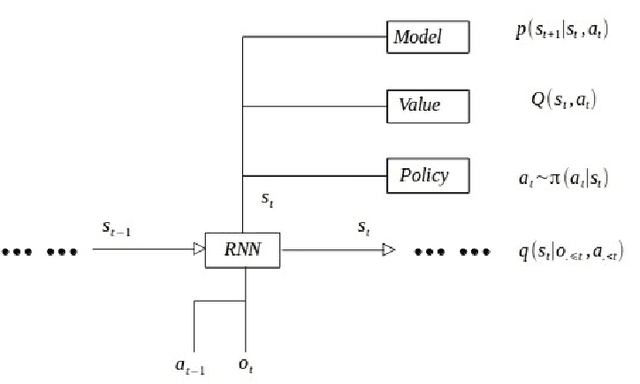
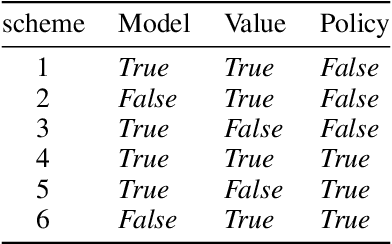
Now a day, model free algorithm achieve state of art performance on many RL problems, but the low efficiency of model free algorithm limited the usage. We combine model base RL, soft actor-critic framework, and curiosity. proposed an agent called RMC, giving a promise way to achieve good performance while maintain data efficiency. We suppress the performance of SAC and achieve state of the art performance, both on efficiency and stability. Meanwhile we can solving POMDP problem and achieve great generalization from MDP to POMDP.