 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoordinated Humanoid Manipulation with Choice Policies
Dec 31, 2025Humanoid robots hold great promise for operating in human-centric environments, yet achieving robust whole-body coordination across the head, hands, and legs remains a major challenge. We present a system that combines a modular teleoperation interface with a scalable learning framework to address this problem. Our teleoperation design decomposes humanoid control into intuitive submodules, which include hand-eye coordination, grasp primitives, arm end-effector tracking, and locomotion. This modularity allows us to collect high-quality demonstrations efficiently. Building on this, we introduce Choice Policy, an imitation learning approach that generates multiple candidate actions and learns to score them. This architecture enables both fast inference and effective modeling of multimodal behaviors. We validate our approach on two real-world tasks: dishwasher loading and whole-body loco-manipulation for whiteboard wiping. Experiments show that Choice Policy significantly outperforms diffusion policies and standard behavior cloning. Furthermore, our results indicate that hand-eye coordination is critical for success in long-horizon tasks. Our work demonstrates a practical path toward scalable data collection and learning for coordinated humanoid manipulation in unstructured environments.
MomaGraph: State-Aware Unified Scene Graphs with Vision-Language Model for Embodied Task Planning
Dec 18, 2025Mobile manipulators in households must both navigate and manipulate. This requires a compact, semantically rich scene representation that captures where objects are, how they function, and which parts are actionable. Scene graphs are a natural choice, yet prior work often separates spatial and functional relations, treats scenes as static snapshots without object states or temporal updates, and overlooks information most relevant for accomplishing the current task. To address these limitations, we introduce MomaGraph, a unified scene representation for embodied agents that integrates spatial-functional relationships and part-level interactive elements. However, advancing such a representation requires both suitable data and rigorous evaluation, which have been largely missing. We thus contribute MomaGraph-Scenes, the first large-scale dataset of richly annotated, task-driven scene graphs in household environments, along with MomaGraph-Bench, a systematic evaluation suite spanning six reasoning capabilities from high-level planning to fine-grained scene understanding. Built upon this foundation, we further develop MomaGraph-R1, a 7B vision-language model trained with reinforcement learning on MomaGraph-Scenes. MomaGraph-R1 predicts task-oriented scene graphs and serves as a zero-shot task planner under a Graph-then-Plan framework. Extensive experiments demonstrate that our model achieves state-of-the-art results among open-source models, reaching 71.6% accuracy on the benchmark (+11.4% over the best baseline), while generalizing across public benchmarks and transferring effectively to real-robot experiments.
HuB: Learning Extreme Humanoid Balance
May 12, 2025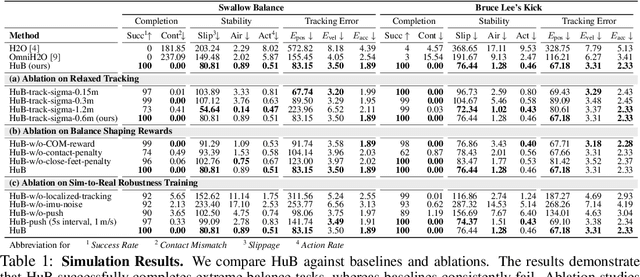
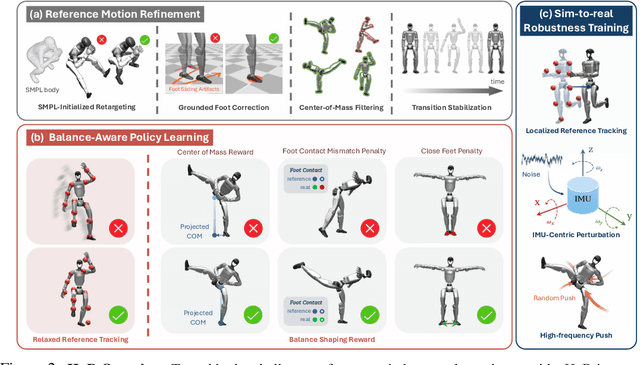
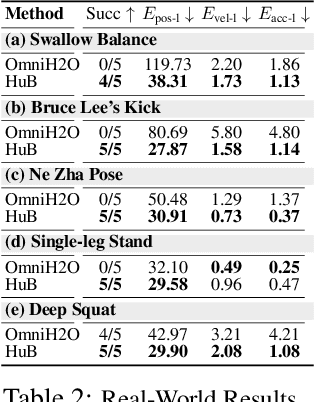
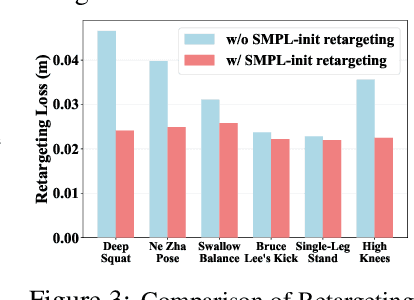
The human body demonstrates exceptional motor capabilities-such as standing steadily on one foot or performing a high kick with the leg raised over 1.5 meters-both requiring precise balance control. While recent research on humanoid control has leveraged reinforcement learning to track human motions for skill acquisition, applying this paradigm to balance-intensive tasks remains challenging. In this work, we identify three key obstacles: instability from reference motion errors, learning difficulties due to morphological mismatch, and the sim-to-real gap caused by sensor noise and unmodeled dynamics. To address these challenges, we propose HuB (Humanoid Balance), a unified framework that integrates reference motion refinement, balance-aware policy learning, and sim-to-real robustness training, with each component targeting a specific challenge. We validate our approach on the Unitree G1 humanoid robot across challenging quasi-static balance tasks, including extreme single-legged poses such as Swallow Balance and Bruce Lee's Kick. Our policy remains stable even under strong physical disturbances-such as a forceful soccer strike-while baseline methods consistently fail to complete these tasks. Project website: https://hub-robot.github.io
RoboVerse: Towards a Unified Platform, Dataset and Benchmark for Scalable and Generalizable Robot Learning
Apr 26, 2025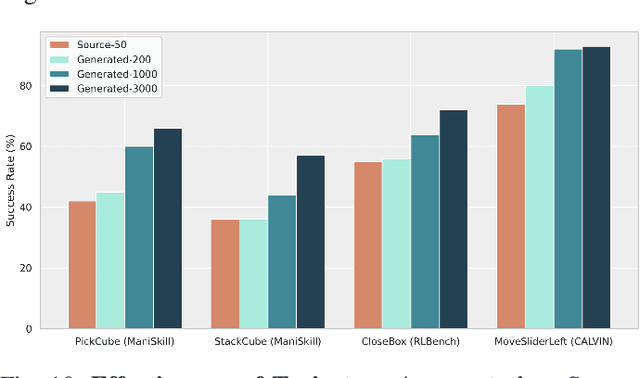



Data scaling and standardized evaluation benchmarks have driven significant advances in natural language processing and computer vision. However, robotics faces unique challenges in scaling data and establishing evaluation protocols. Collecting real-world data is resource-intensive and inefficient, while benchmarking in real-world scenarios remains highly complex. Synthetic data and simulation offer promising alternatives, yet existing efforts often fall short in data quality, diversity, and benchmark standardization. To address these challenges, we introduce RoboVerse, a comprehensive framework comprising a simulation platform, a synthetic dataset, and unified benchmarks. Our simulation platform supports multiple simulators and robotic embodiments, enabling seamless transitions between different environments. The synthetic dataset, featuring high-fidelity physics and photorealistic rendering, is constructed through multiple approaches. Additionally, we propose unified benchmarks for imitation learning and reinforcement learning, enabling evaluation across different levels of generalization. At the core of the simulation platform is MetaSim, an infrastructure that abstracts diverse simulation environments into a universal interface. It restructures existing simulation environments into a simulator-agnostic configuration system, as well as an API aligning different simulator functionalities, such as launching simulation environments, loading assets with initial states, stepping the physics engine, etc. This abstraction ensures interoperability and extensibility. Comprehensive experiments demonstrate that RoboVerse enhances the performance of imitation learning, reinforcement learning, world model learning, and sim-to-real transfer. These results validate the reliability of our dataset and benchmarks, establishing RoboVerse as a robust solution for advancing robot learning.
Improving Vision-Language-Action Model with Online Reinforcement Learning
Jan 28, 2025
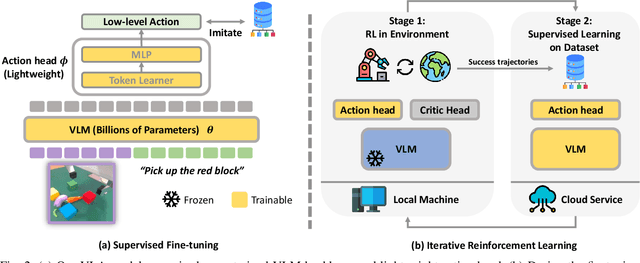

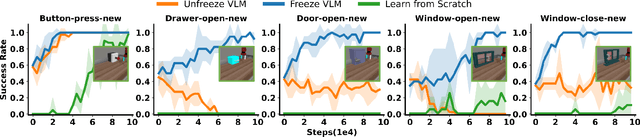
Recent studies have successfully integrated large vision-language models (VLMs) into low-level robotic control by supervised fine-tuning (SFT) with expert robotic datasets, resulting in what we term vision-language-action (VLA) models. Although the VLA models are powerful, how to improve these large models during interaction with environments remains an open question. In this paper, we explore how to further improve these VLA models via Reinforcement Learning (RL), a commonly used fine-tuning technique for large models. However, we find that directly applying online RL to large VLA models presents significant challenges, including training instability that severely impacts the performance of large models, and computing burdens that exceed the capabilities of most local machines. To address these challenges, we propose iRe-VLA framework, which iterates between Reinforcement Learning and Supervised Learning to effectively improve VLA models, leveraging the exploratory benefits of RL while maintaining the stability of supervised learning. Experiments in two simulated benchmarks and a real-world manipulation suite validate the effectiveness of our method.
Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations
Dec 19, 2024



Recent advancements in robotics have focused on developing generalist policies capable of performing multiple tasks. Typically, these policies utilize pre-trained vision encoders to capture crucial information from current observations. However, previous vision encoders, which trained on two-image contrastive learning or single-image reconstruction, can not perfectly capture the sequential information essential for embodied tasks. Recently, video diffusion models (VDMs) have demonstrated the capability to accurately predict future image sequences, exhibiting a good understanding of physical dynamics. Motivated by the strong visual prediction capabilities of VDMs, we hypothesize that they inherently possess visual representations that reflect the evolution of the physical world, which we term predictive visual representations. Building on this hypothesis, we propose the Video Prediction Policy (VPP), a generalist robotic policy conditioned on the predictive visual representations from VDMs. To further enhance these representations, we incorporate diverse human or robotic manipulation datasets, employing unified video-generation training objectives. VPP consistently outperforms existing methods across two simulated and two real-world benchmarks. Notably, it achieves a 28.1\% relative improvement in the Calvin ABC-D benchmark compared to the previous state-of-the-art and delivers a 28.8\% increase in success rates for complex real-world dexterous manipulation tasks.
Prediction with Action: Visual Policy Learning via Joint Denoising Process
Nov 27, 2024



Diffusion models have demonstrated remarkable capabilities in image generation tasks, including image editing and video creation, representing a good understanding of the physical world. On the other line, diffusion models have also shown promise in robotic control tasks by denoising actions, known as diffusion policy. Although the diffusion generative model and diffusion policy exhibit distinct capabilities--image prediction and robotic action, respectively--they technically follow a similar denoising process. In robotic tasks, the ability to predict future images and generate actions is highly correlated since they share the same underlying dynamics of the physical world. Building on this insight, we introduce PAD, a novel visual policy learning framework that unifies image Prediction and robot Action within a joint Denoising process. Specifically, PAD utilizes Diffusion Transformers (DiT) to seamlessly integrate images and robot states, enabling the simultaneous prediction of future images and robot actions. Additionally, PAD supports co-training on both robotic demonstrations and large-scale video datasets and can be easily extended to other robotic modalities, such as depth images. PAD outperforms previous methods, achieving a significant 26.3% relative improvement on the full Metaworld benchmark, by utilizing a single text-conditioned visual policy within a data-efficient imitation learning setting. Furthermore, PAD demonstrates superior generalization to unseen tasks in real-world robot manipulation settings with 28.0% success rate increase compared to the strongest baseline. Project page at https://sites.google.com/view/pad-paper
Learning Smooth Humanoid Locomotion through Lipschitz-Constrained Policies
Oct 15, 2024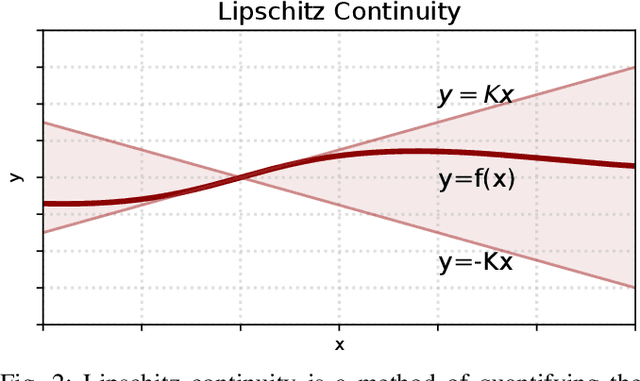
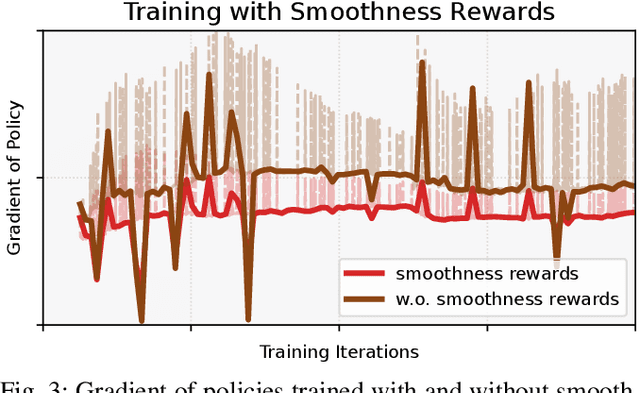
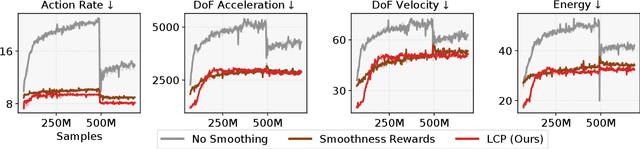
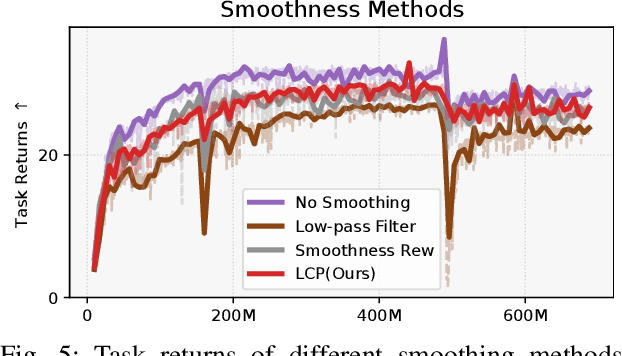
Reinforcement learning combined with sim-to-real transfer offers a general framework for developing locomotion controllers for legged robots. To facilitate successful deployment in the real world, smoothing techniques, such as low-pass filters and smoothness rewards, are often employed to develop policies with smooth behaviors. However, because these techniques are non-differentiable and usually require tedious tuning of a large set of hyperparameters, they tend to require extensive manual tuning for each robotic platform. To address this challenge and establish a general technique for enforcing smooth behaviors, we propose a simple and effective method that imposes a Lipschitz constraint on a learned policy, which we refer to as Lipschitz-Constrained Policies (LCP). We show that the Lipschitz constraint can be implemented in the form of a gradient penalty, which provides a differentiable objective that can be easily incorporated with automatic differentiation frameworks. We demonstrate that LCP effectively replaces the need for smoothing rewards or low-pass filters and can be easily integrated into training frameworks for many distinct humanoid robots. We extensively evaluate LCP in both simulation and real-world humanoid robots, producing smooth and robust locomotion controllers. All simulation and deployment code, along with complete checkpoints, is available on our project page: https://lipschitz-constrained-policy.github.io.
Advancing Humanoid Locomotion: Mastering Challenging Terrains with Denoising World Model Learning
Aug 26, 2024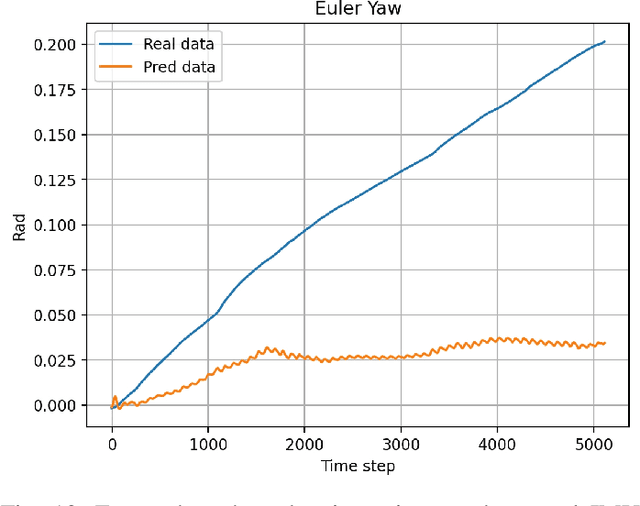
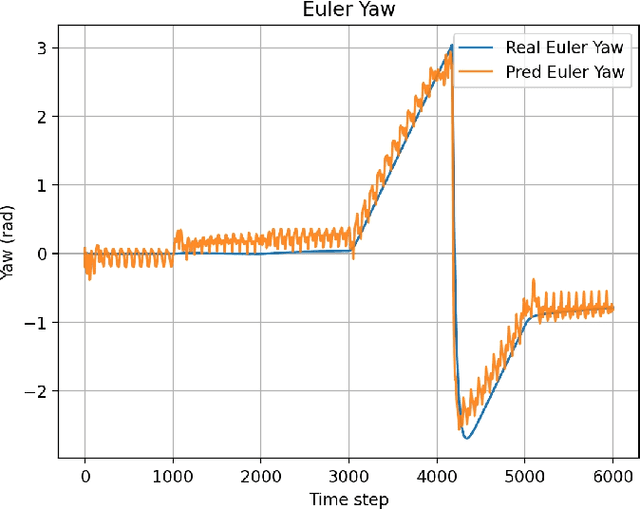
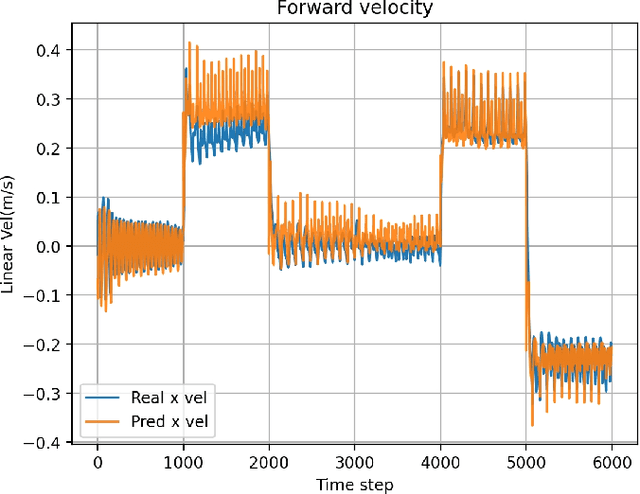
Humanoid robots, with their human-like skeletal structure, are especially suited for tasks in human-centric environments. However, this structure is accompanied by additional challenges in locomotion controller design, especially in complex real-world environments. As a result, existing humanoid robots are limited to relatively simple terrains, either with model-based control or model-free reinforcement learning. In this work, we introduce Denoising World Model Learning (DWL), an end-to-end reinforcement learning framework for humanoid locomotion control, which demonstrates the world's first humanoid robot to master real-world challenging terrains such as snowy and inclined land in the wild, up and down stairs, and extremely uneven terrains. All scenarios run the same learned neural network with zero-shot sim-to-real transfer, indicating the superior robustness and generalization capability of the proposed method.
Humanoid-Gym: Reinforcement Learning for Humanoid Robot with Zero-Shot Sim2Real Transfer
Apr 08, 2024



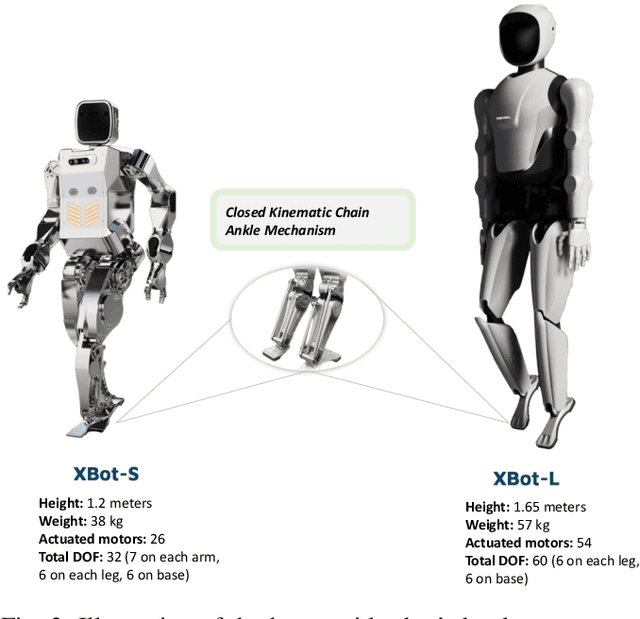
Humanoid-Gym is an easy-to-use reinforcement learning (RL) framework based on Nvidia Isaac Gym, designed to train locomotion skills for humanoid robots, emphasizing zero-shot transfer from simulation to the real-world environment. Humanoid-Gym also integrates a sim-to-sim framework from Isaac Gym to Mujoco that allows users to verify the trained policies in different physical simulations to ensure the robustness and generalization of the policies. This framework is verified by RobotEra's XBot-S (1.2-meter tall humanoid robot) and XBot-L (1.65-meter tall humanoid robot) in a real-world environment with zero-shot sim-to-real transfer. The project website and source code can be found at: https://sites.google.com/view/humanoid-gym/.