 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoReMi: Grounding Language Model by Detecting and Recovering from Plan-Execution Misalignment
Paper and Code
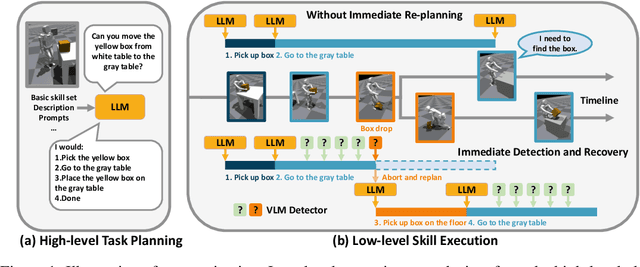

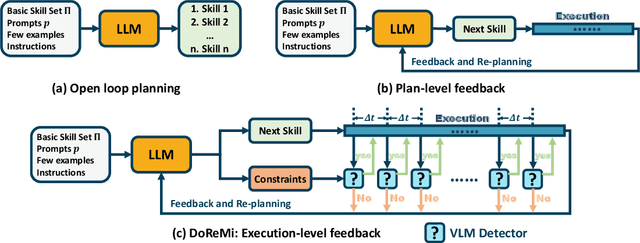
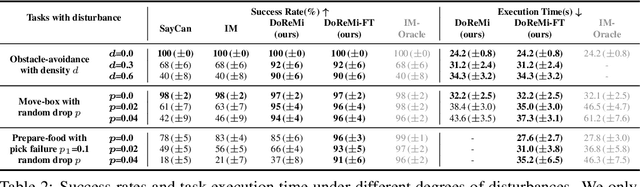
Large language models encode a vast amount of semantic knowledge and possess remarkable understanding and reasoning capabilities. Previous research has explored how to ground language models in robotic tasks to ensure that the sequences generated by the language model are both logically correct and practically executable. However, low-level execution may deviate from the high-level plan due to environmental perturbations or imperfect controller design. In this paper, we propose DoReMi, a novel language model grounding framework that enables immediate Detection and Recovery from Misalignments between plan and execution. Specifically, during low-level skill execution, we use a vision question answering (VQA) model to regularly detect plan-execution misalignments. If certain misalignment occurs, our method will call the language model to re-plan in order to recover from misalignments. Experiments on various complex tasks including robot arms and humanoid robots demonstrate that our method can lead to higher task success rates and shorter task completion times. Videos of DoReMi are available at https://sites.google.com/view/doremi-paper.