 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink on your feet: Seamless Transition between Human-like Locomotion in Response to Changing Commands
Feb 26, 2025



While it is relatively easier to train humanoid robots to mimic specific locomotion skills, it is more challenging to learn from various motions and adhere to continuously changing commands. These robots must accurately track motion instructions, seamlessly transition between a variety of movements, and master intermediate motions not present in their reference data. In this work, we propose a novel approach that integrates human-like motion transfer with precise velocity tracking by a series of improvements to classical imitation learning. To enhance generalization, we employ the Wasserstein divergence criterion (WGAN-div). Furthermore, a Hybrid Internal Model provides structured estimates of hidden states and velocity to enhance mobile stability and environment adaptability, while a curiosity bonus fosters exploration. Our comprehensive method promises highly human-like locomotion that adapts to varying velocity requirements, direct generalization to unseen motions and multitasking, as well as zero-shot transfer to the simulator and the real world across different terrains. These advancements are validated through simulations across various robot models and extensive real-world experiments.
DoReMi: Grounding Language Model by Detecting and Recovering from Plan-Execution Misalignment
Jul 01, 2023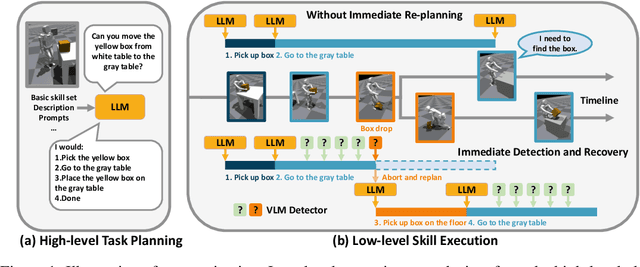

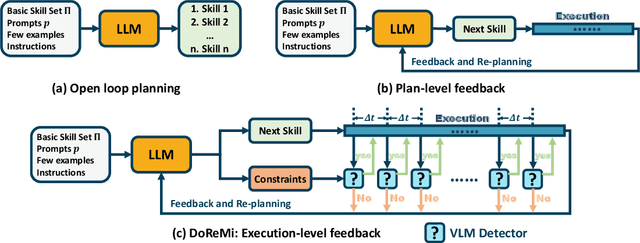
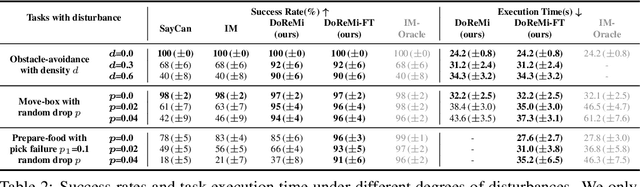
Large language models encode a vast amount of semantic knowledge and possess remarkable understanding and reasoning capabilities. Previous research has explored how to ground language models in robotic tasks to ensure that the sequences generated by the language model are both logically correct and practically executable. However, low-level execution may deviate from the high-level plan due to environmental perturbations or imperfect controller design. In this paper, we propose DoReMi, a novel language model grounding framework that enables immediate Detection and Recovery from Misalignments between plan and execution. Specifically, during low-level skill execution, we use a vision question answering (VQA) model to regularly detect plan-execution misalignments. If certain misalignment occurs, our method will call the language model to re-plan in order to recover from misalignments. Experiments on various complex tasks including robot arms and humanoid robots demonstrate that our method can lead to higher task success rates and shorter task completion times. Videos of DoReMi are available at https://sites.google.com/view/doremi-paper.
Decentralized Motor Skill Learning for Complex Robotic Systems
Jun 30, 2023Reinforcement learning (RL) has achieved remarkable success in complex robotic systems (eg. quadruped locomotion). In previous works, the RL-based controller was typically implemented as a single neural network with concatenated observation input. However, the corresponding learned policy is highly task-specific. Since all motors are controlled in a centralized way, out-of-distribution local observations can impact global motors through the single coupled neural network policy. In contrast, animals and humans can control their limbs separately. Inspired by this biological phenomenon, we propose a Decentralized motor skill (DEMOS) learning algorithm to automatically discover motor groups that can be decoupled from each other while preserving essential connections and then learn a decentralized motor control policy. Our method improves the robustness and generalization of the policy without sacrificing performance. Experiments on quadruped and humanoid robots demonstrate that the learned policy is robust against local motor malfunctions and can be transferred to new tasks.
AMP in the wild: Learning robust, agile, natural legged locomotion skills
Apr 21, 2023The successful transfer of a learned controller from simulation to the real world for a legged robot requires not only the ability to identify the system, but also accurate estimation of the robot's state. In this paper, we propose a novel algorithm that can infer not only information about the parameters of the dynamic system, but also estimate important information about the robot's state from previous observations. We integrate our algorithm with Adversarial Motion Priors and achieve a robust, agile, and natural gait in both simulation and on a Unitree A1 quadruped robot in the real world. Empirical results demonstrate that our proposed algorithm enables traversing challenging terrains with lower power consumption compared to the baselines. Both qualitative and quantitative results are presented in this paper.