 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink on your feet: Seamless Transition between Human-like Locomotion in Response to Changing Commands
Feb 26, 2025



While it is relatively easier to train humanoid robots to mimic specific locomotion skills, it is more challenging to learn from various motions and adhere to continuously changing commands. These robots must accurately track motion instructions, seamlessly transition between a variety of movements, and master intermediate motions not present in their reference data. In this work, we propose a novel approach that integrates human-like motion transfer with precise velocity tracking by a series of improvements to classical imitation learning. To enhance generalization, we employ the Wasserstein divergence criterion (WGAN-div). Furthermore, a Hybrid Internal Model provides structured estimates of hidden states and velocity to enhance mobile stability and environment adaptability, while a curiosity bonus fosters exploration. Our comprehensive method promises highly human-like locomotion that adapts to varying velocity requirements, direct generalization to unseen motions and multitasking, as well as zero-shot transfer to the simulator and the real world across different terrains. These advancements are validated through simulations across various robot models and extensive real-world experiments.
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
Feb 25, 2024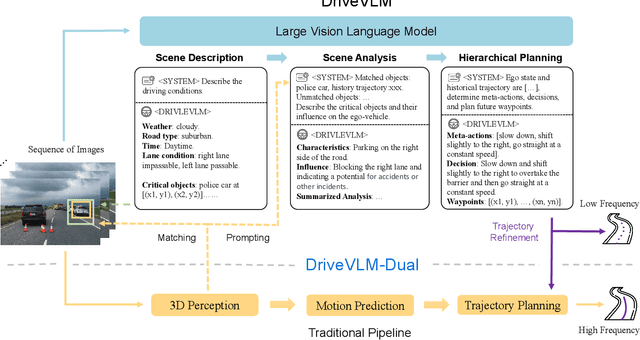
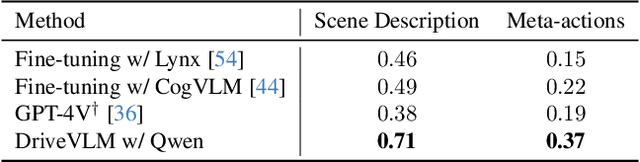
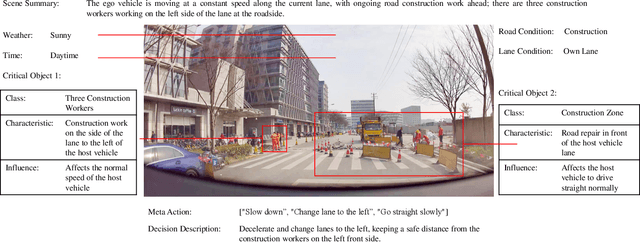
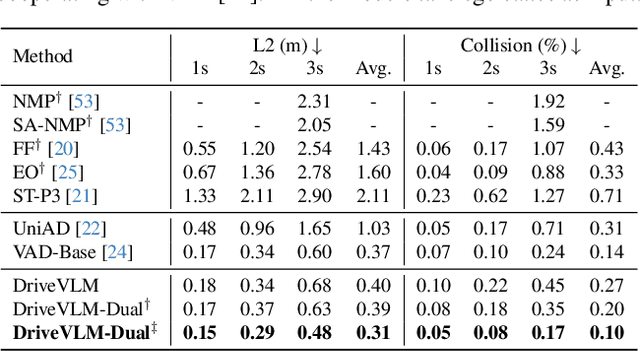
A primary hurdle of autonomous driving in urban environments is understanding complex and long-tail scenarios, such as challenging road conditions and delicate human behaviors. We introduce DriveVLM, an autonomous driving system leveraging Vision-Language Models (VLMs) for enhanced scene understanding and planning capabilities. DriveVLM integrates a unique combination of chain-of-thought (CoT) modules for scene description, scene analysis, and hierarchical planning. Furthermore, recognizing the limitations of VLMs in spatial reasoning and heavy computational requirements, we propose DriveVLM-Dual, a hybrid system that synergizes the strengths of DriveVLM with the traditional autonomous driving pipeline. DriveVLM-Dual achieves robust spatial understanding and real-time inference speed. Extensive experiments on both the nuScenes dataset and our SUP-AD dataset demonstrate the effectiveness of DriveVLM and the enhanced performance of DriveVLM-Dual, surpassing existing methods in complex and unpredictable driving conditions.
DiCLET-TTS: Diffusion Model based Cross-lingual Emotion Transfer for Text-to-Speech -- A Study between English and Mandarin
Sep 02, 2023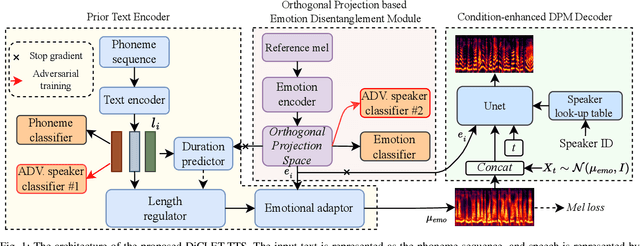
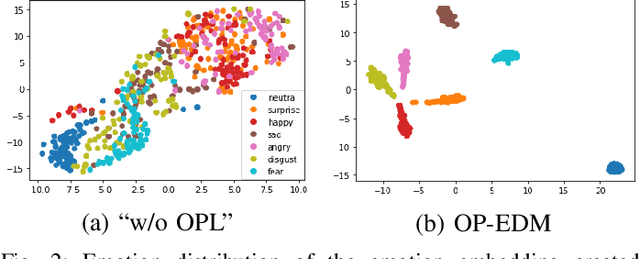
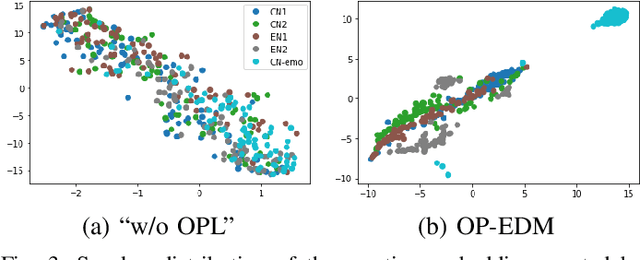
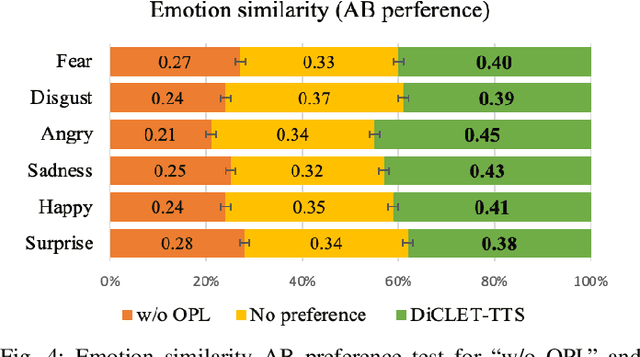
While the performance of cross-lingual TTS based on monolingual corpora has been significantly improved recently, generating cross-lingual speech still suffers from the foreign accent problem, leading to limited naturalness. Besides, current cross-lingual methods ignore modeling emotion, which is indispensable paralinguistic information in speech delivery. In this paper, we propose DiCLET-TTS, a Diffusion model based Cross-Lingual Emotion Transfer method that can transfer emotion from a source speaker to the intra- and cross-lingual target speakers. Specifically, to relieve the foreign accent problem while improving the emotion expressiveness, the terminal distribution of the forward diffusion process is parameterized into a speaker-irrelevant but emotion-related linguistic prior by a prior text encoder with the emotion embedding as a condition. To address the weaker emotional expressiveness problem caused by speaker disentanglement in emotion embedding, a novel orthogonal projection based emotion disentangling module (OP-EDM) is proposed to learn the speaker-irrelevant but emotion-discriminative embedding. Moreover, a condition-enhanced DPM decoder is introduced to strengthen the modeling ability of the speaker and the emotion in the reverse diffusion process to further improve emotion expressiveness in speech delivery. Cross-lingual emotion transfer experiments show the superiority of DiCLET-TTS over various competitive models and the good design of OP-EDM in learning speaker-irrelevant but emotion-discriminative embedding.
Diff-Foley: Synchronized Video-to-Audio Synthesis with Latent Diffusion Models
Jun 29, 2023
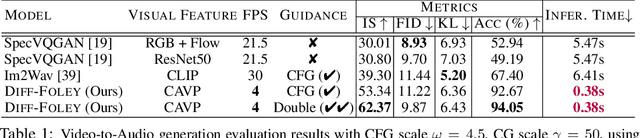
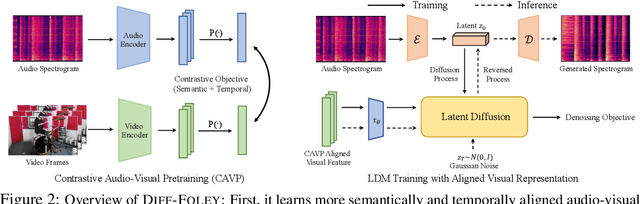

The Video-to-Audio (V2A) model has recently gained attention for its practical application in generating audio directly from silent videos, particularly in video/film production. However, previous methods in V2A have limited generation quality in terms of temporal synchronization and audio-visual relevance. We present Diff-Foley, a synchronized Video-to-Audio synthesis method with a latent diffusion model (LDM) that generates high-quality audio with improved synchronization and audio-visual relevance. We adopt contrastive audio-visual pretraining (CAVP) to learn more temporally and semantically aligned features, then train an LDM with CAVP-aligned visual features on spectrogram latent space. The CAVP-aligned features enable LDM to capture the subtler audio-visual correlation via a cross-attention module. We further significantly improve sample quality with `double guidance'. Diff-Foley achieves state-of-the-art V2A performance on current large scale V2A dataset. Furthermore, we demonstrate Diff-Foley practical applicability and generalization capabilities via downstream finetuning. Project Page: see https://diff-foley.github.io/
ChatDB: Augmenting LLMs with Databases as Their Symbolic Memory
Jun 07, 2023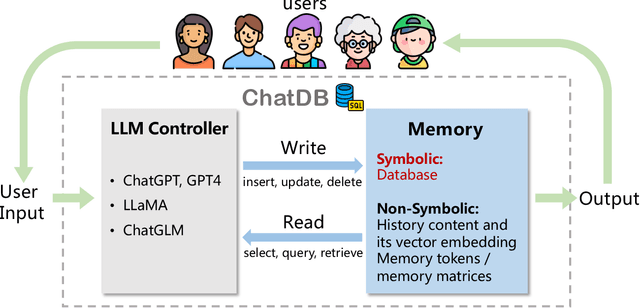

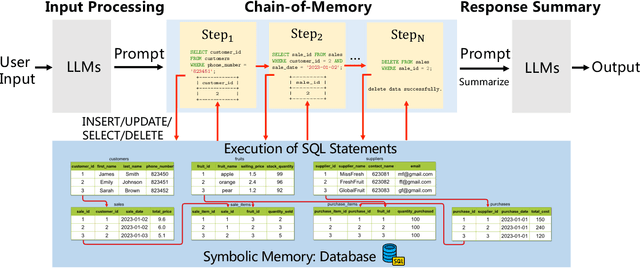
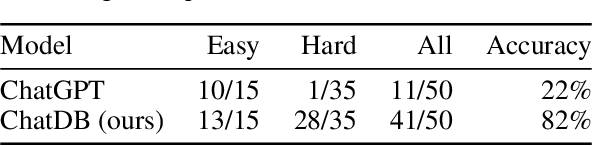
Large language models (LLMs) with memory are computationally universal. However, mainstream LLMs are not taking full advantage of memory, and the designs are heavily influenced by biological brains. Due to their approximate nature and proneness to the accumulation of errors, conventional neural memory mechanisms cannot support LLMs to simulate complex reasoning. In this paper, we seek inspiration from modern computer architectures to augment LLMs with symbolic memory for complex multi-hop reasoning. Such a symbolic memory framework is instantiated as an LLM and a set of SQL databases, where the LLM generates SQL instructions to manipulate the SQL databases. We validate the effectiveness of the proposed memory framework on a synthetic dataset requiring complex reasoning. The project website is available at https://chatdatabase.github.io/ .
ViP3D: End-to-end Visual Trajectory Prediction via 3D Agent Queries
Aug 02, 2022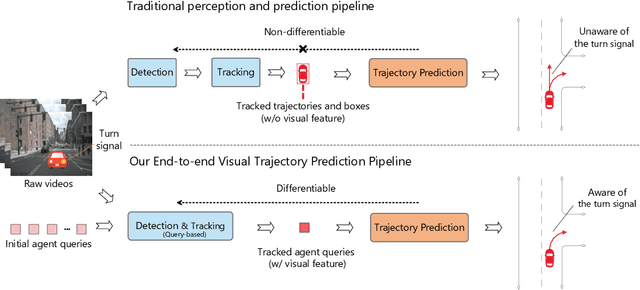
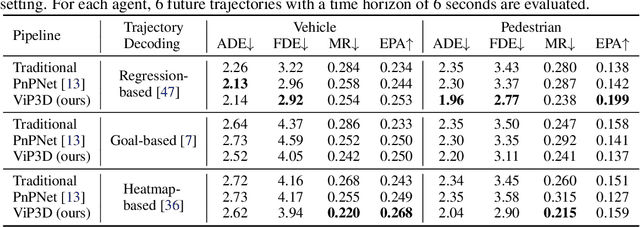
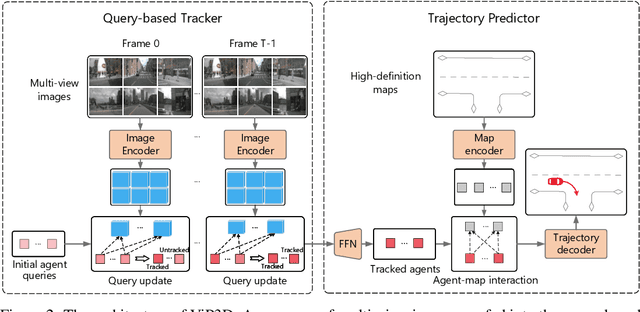
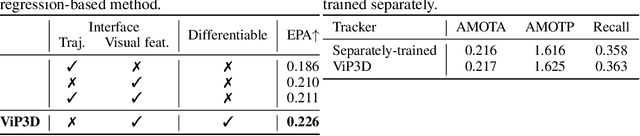
Existing autonomous driving pipelines separate the perception module from the prediction module. The two modules communicate via hand-picked features such as agent boxes and trajectories as interfaces. Due to this separation, the prediction module only receives partial information from the perception module. Even worse, errors from the perception modules can propagate and accumulate, adversely affecting the prediction results. In this work, we propose ViP3D, a visual trajectory prediction pipeline that leverages the rich information from raw videos to predict future trajectories of agents in a scene. ViP3D employs sparse agent queries throughout the pipeline, making it fully differentiable and interpretable. Furthermore, we propose an evaluation metric for this novel end-to-end visual trajectory prediction task. Extensive experimental results on the nuScenes dataset show the strong performance of ViP3D over traditional pipelines and previous end-to-end models.
Controllable and Lossless Non-Autoregressive End-to-End Text-to-Speech
Jul 13, 2022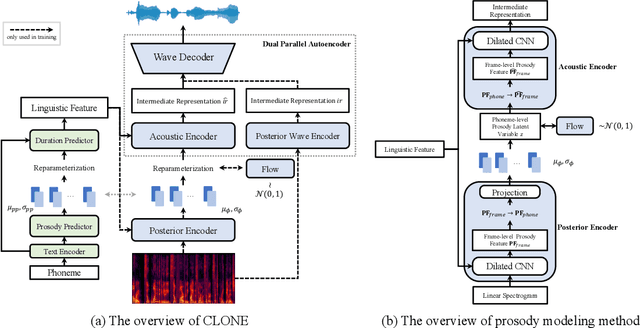
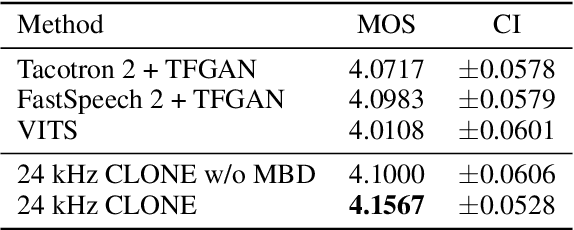
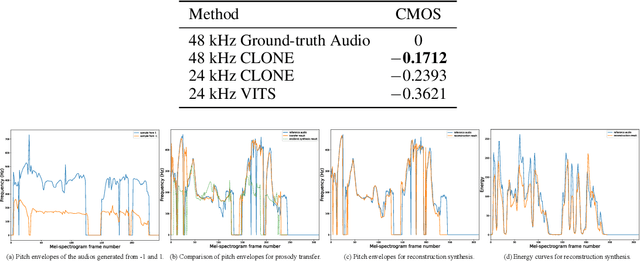

Some recent studies have demonstrated the feasibility of single-stage neural text-to-speech, which does not need to generate mel-spectrograms but generates the raw waveforms directly from the text. Single-stage text-to-speech often faces two problems: a) the one-to-many mapping problem due to multiple speech variations and b) insufficiency of high frequency reconstruction due to the lack of supervision of ground-truth acoustic features during training. To solve the a) problem and generate more expressive speech, we propose a novel phoneme-level prosody modeling method based on a variational autoencoder with normalizing flows to model underlying prosodic information in speech. We also use the prosody predictor to support end-to-end expressive speech synthesis. Furthermore, we propose the dual parallel autoencoder to introduce supervision of the ground-truth acoustic features during training to solve the b) problem enabling our model to generate high-quality speech. We compare the synthesis quality with state-of-the-art text-to-speech systems on an internal expressive English dataset. Both qualitative and quantitative evaluations demonstrate the superiority and robustness of our method for lossless speech generation while also showing a strong capability in prosody modeling.
Neural Dubber: Dubbing for Silent Videos According to Scripts
Oct 15, 2021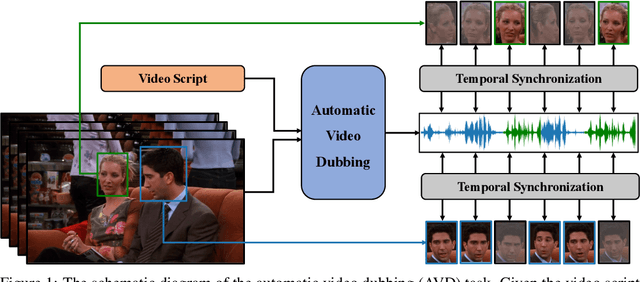
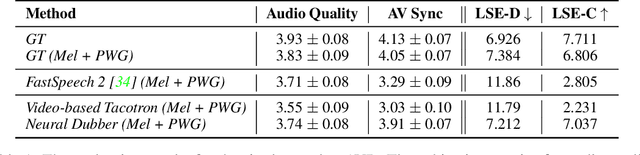
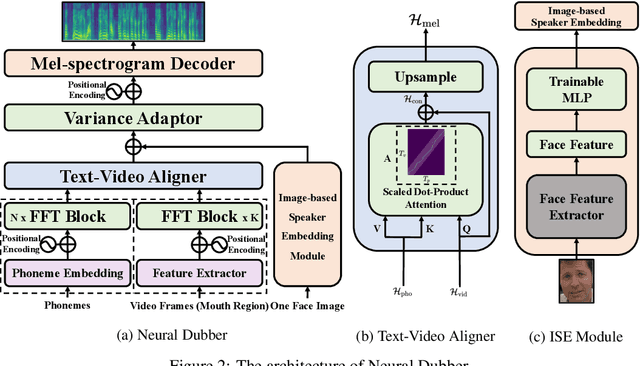
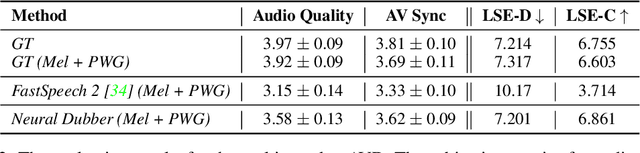
Dubbing is a post-production process of re-recording actors' dialogues, which is extensively used in filmmaking and video production. It is usually performed manually by professional voice actors who read lines with proper prosody, and in synchronization with the pre-recorded videos. In this work, we propose Neural Dubber, the first neural network model to solve a novel automatic video dubbing (AVD) task: synthesizing human speech synchronized with the given silent video from the text. Neural Dubber is a multi-modal text-to-speech (TTS) model that utilizes the lip movement in the video to control the prosody of the generated speech. Furthermore, an image-based speaker embedding (ISE) module is developed for the multi-speaker setting, which enables Neural Dubber to generate speech with a reasonable timbre according to the speaker's face. Experiments on the chemistry lecture single-speaker dataset and LRS2 multi-speaker dataset show that Neural Dubber can generate speech audios on par with state-of-the-art TTS models in terms of speech quality. Most importantly, both qualitative and quantitative evaluations show that Neural Dubber can control the prosody of synthesized speech by the video, and generate high-fidelity speech temporally synchronized with the video.
FastSpeech 2: Fast and High-Quality End-to-End Text to Speech
Jun 22, 2020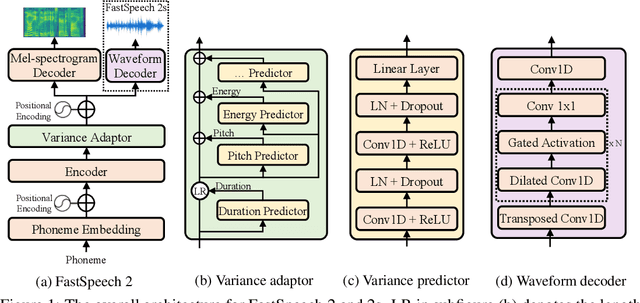
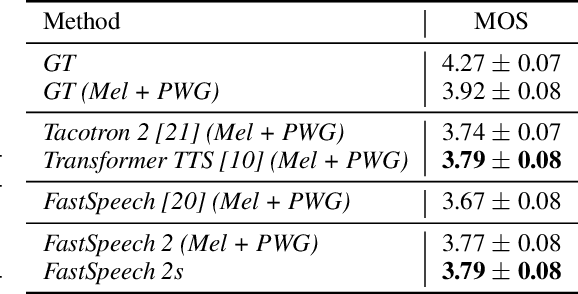
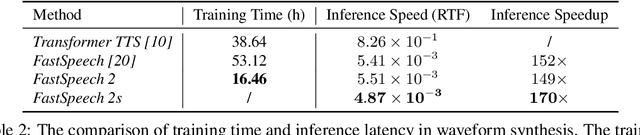
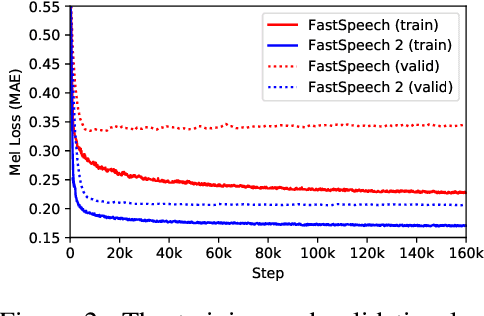
Advanced text to speech (TTS) models such as FastSpeech can synthesize speech significantly faster than previous autoregressive models with comparable quality. The training of FastSpeech model relies on an autoregressive teacher model for duration prediction (to provide more information as input) and knowledge distillation (to simplify the data distribution in output), which can ease the one-to-many mapping problem (i.e., multiple speech variations correspond to the same text) in TTS. However, FastSpeech has several disadvantages: 1) the teacher-student distillation pipeline is complicated, 2) the duration extracted from the teacher model is not accurate enough, and the target mel-spectrograms distilled from teacher model suffer from information loss due to data simplification, both of which limit the voice quality. In this paper, we propose FastSpeech 2, which addresses the issues in FastSpeech and better solves the one-to-many mapping problem in TTS by 1) directly training the model with ground-truth target instead of the simplified output from teacher, and 2) introducing more variation information of speech (e.g., pitch, energy and more accurate duration) as conditional inputs. Specifically, we extract duration, pitch and energy from speech waveform and directly take them as conditional inputs during training and use predicted values during inference. We further design FastSpeech 2s, which is the first attempt to directly generate speech waveform from text in parallel, enjoying the benefit of full end-to-end training and even faster inference than FastSpeech. Experimental results show that 1) FastSpeech 2 and 2s outperform FastSpeech in voice quality with much simplified training pipeline and reduced training time; 2) FastSpeech 2 and 2s can match the voice quality of autoregressive models while enjoying much faster inference speed.