 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink on your feet: Seamless Transition between Human-like Locomotion in Response to Changing Commands
Feb 26, 2025



While it is relatively easier to train humanoid robots to mimic specific locomotion skills, it is more challenging to learn from various motions and adhere to continuously changing commands. These robots must accurately track motion instructions, seamlessly transition between a variety of movements, and master intermediate motions not present in their reference data. In this work, we propose a novel approach that integrates human-like motion transfer with precise velocity tracking by a series of improvements to classical imitation learning. To enhance generalization, we employ the Wasserstein divergence criterion (WGAN-div). Furthermore, a Hybrid Internal Model provides structured estimates of hidden states and velocity to enhance mobile stability and environment adaptability, while a curiosity bonus fosters exploration. Our comprehensive method promises highly human-like locomotion that adapts to varying velocity requirements, direct generalization to unseen motions and multitasking, as well as zero-shot transfer to the simulator and the real world across different terrains. These advancements are validated through simulations across various robot models and extensive real-world experiments.
Vision-based Distributed Multi-UAV Collision Avoidance via Deep Reinforcement Learning for Navigation
Mar 05, 2022
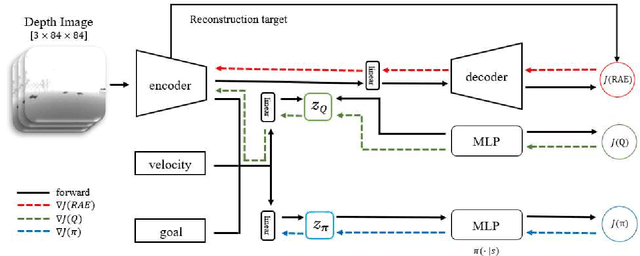
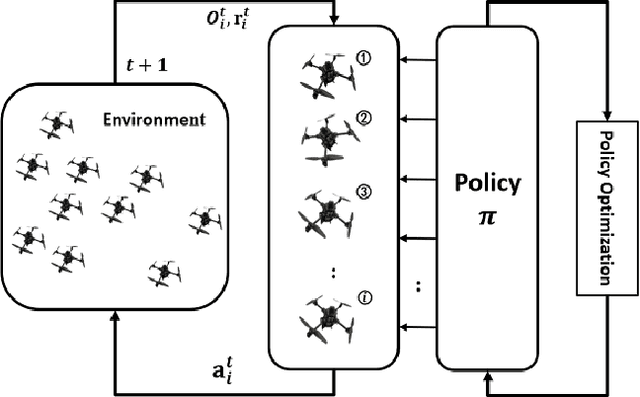
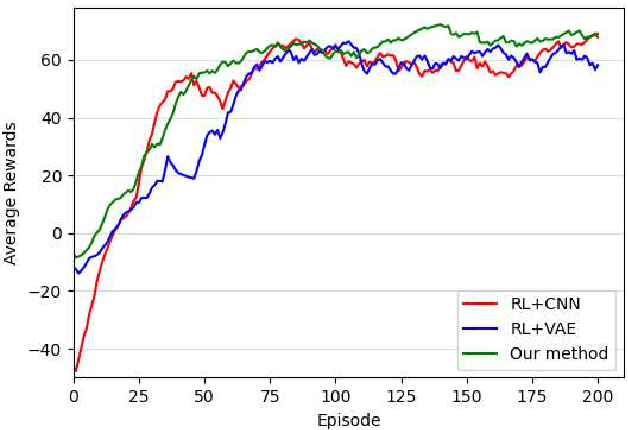
Online path planning for multiple unmanned aerial vehicle (multi-UAV) systems is considered a challenging task. It needs to ensure collision-free path planning in real-time, especially when the multi-UAV systems can become very crowded on certain occasions. In this paper, we presented a vision-based decentralized collision-avoidance policy for multi-UAV systems, which takes depth images and inertial measurements as sensory inputs and outputs UAV's steering commands. The policy is trained together with the latent representation of depth images using a policy gradient-based reinforcement learning algorithm and autoencoder in the multi-UAV threedimensional workspaces. Each UAV follows the same trained policy and acts independently to reach the goal without colliding or communicating with other UAVs. We validate our policy in various simulated scenarios. The experimental results show that our learned policy can guarantee fully autonomous collision-free navigation for multi-UAV in the three-dimensional workspaces with good robustness and scalability.