 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAGIS: Evidence-Based Multi-Agent Reasoning for Interpretable Strabismus Clinical Decision-Making
Jun 08, 2026Strabismus is a common ocular disorder that requires fine-grained subtype diagnosis for individualized treatment planning. However, existing deep learning methods mainly provide diagnostic predictions without transparent reasoning, while recent large vision-language models (LVLMs), although promising for joint image understanding and report generation, remain highly prone to hallucination in this evidence-sensitive and rule-driven medical task. To address these challenges, we propose MAGIS, an evidence-based Multi-AGent reasoning for Interpretable Strabismus diagnosis framework. MAGIS transforms black-box end-to-end generation into a structured diagnostic process consisting of candidate hypothesis generation, dual-evidence constrained context, evidence-based corrective verification, and report generation. Specifically, we introduce a Dual-Evidence Constrained Context (DECC) mechanism that jointly organizes visual evidence from the photograph of the nine cardinal positions of gaze and evidence-based clinical diagnostic rules into a constrained context for reliable diagnostic reasoning. We further develop an Evidence-Based Corrective Verification (EBCV) mechanism that verifies whether the current diagnostic hypothesis is supported by visual evidence, heatmap-based visual cues, and evidence-based clinical diagnostic rules. Hypothesis refinement is triggered when inconsistency is detected. Experiments on a fine-grained strabismus benchmark demonstrate that MAGIS not only significantly outperforms other state-of-the-art diagnostic systems, improving the weighted F1 score from 72.0% to 91.3%, but also substantially improves the clinical reliability (consistency, alignment, and completeness) of generated diagnostic reports. These results demonstrate that MAGIS provides an effective solution for building accurate, evidence-based, and clinically interpretable strabismus diagnosis systems.
CrackCLF: Automatic Pavement Crack Detection based on Closed-Loop Feedback
Nov 20, 2023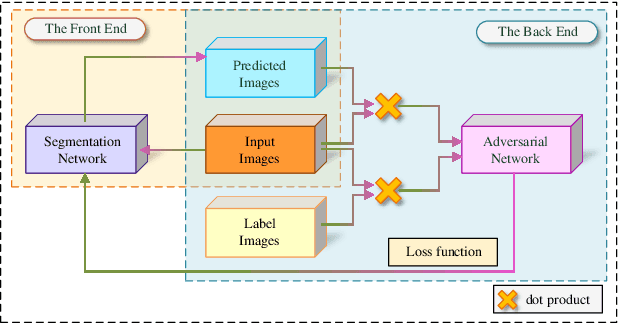

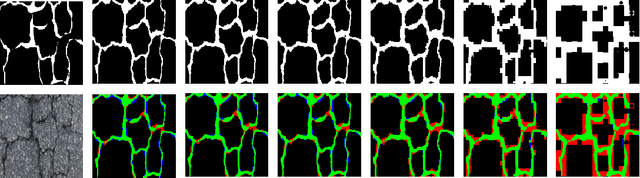
Automatic pavement crack detection is an important task to ensure the functional performances of pavements during their service life. Inspired by deep learning (DL), the encoder-decoder framework is a powerful tool for crack detection. However, these models are usually open-loop (OL) systems that tend to treat thin cracks as the background. Meanwhile, these models can not automatically correct errors in the prediction, nor can it adapt to the changes of the environment to automatically extract and detect thin cracks. To tackle this problem, we embed closed-loop feedback (CLF) into the neural network so that the model could learn to correct errors on its own, based on generative adversarial networks (GAN). The resulting model is called CrackCLF and includes the front and back ends, i.e. segmentation and adversarial network. The front end with U-shape framework is employed to generate crack maps, and the back end with a multi-scale loss function is used to correct higher-order inconsistencies between labels and crack maps (generated by the front end) to address open-loop system issues. Empirical results show that the proposed CrackCLF outperforms others methods on three public datasets. Moreover, the proposed CLF can be defined as a plug and play module, which can be embedded into different neural network models to improve their performances.
Why does Stereo Triangulation Not Work in UAV Distance Estimation
Jun 15, 2023



UAV distance estimation plays an important role for path planning of swarm UAVs and collision avoidance. However, the lack of annotated data seriously hinder the related studies. In this paper, we build and present a UAVDE dataset for UAV distance estimation, in which distance between two UAVs is obtained by UWB sensors. During experiments, we surprisingly observe that the commonly used stereo triangulation can not stand for UAV scenes. The core reason is the position deviation issue of UAVs due to long shooting distance and camera vibration, which is common in UAV scenes. To tackle this issue, we propose a novel position correction module (PCM), which can directly predict the offset between the image positions and the actual ones of UAVs and perform calculation compensation in stereo triangulation. Besides, to further boost performance on hard samples, we propose a dynamic iterative correction mechanism, which is composed of multiple stacked PCMs and a gating mechanism to adaptively determine whether further correction is required according to the difficulty of data samples. Consequently, the position deviation issue can be effectively alleviated. We conduct extensive experiments on UAVDE, and our proposed method can achieve a 38.84% performance improvement, which demonstrates its effectiveness and superiority. The code and dataset would be released.
RHA-Net: An Encoder-Decoder Network with Residual Blocks and Hybrid Attention Mechanisms for Pavement Crack Segmentation
Jul 28, 2022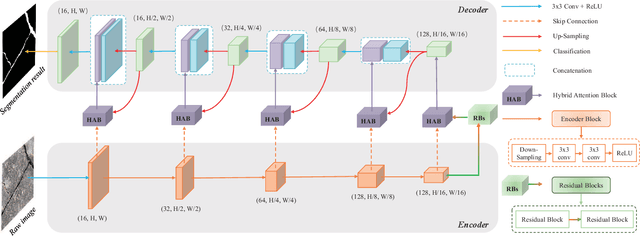

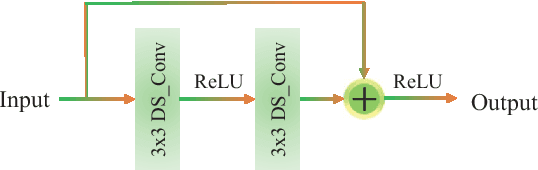
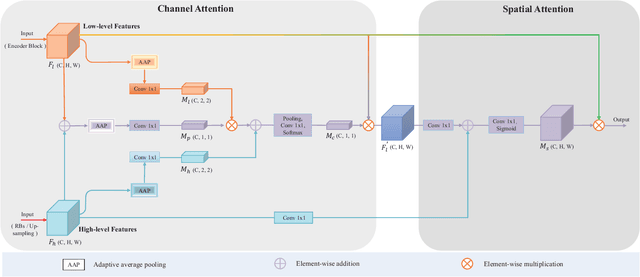
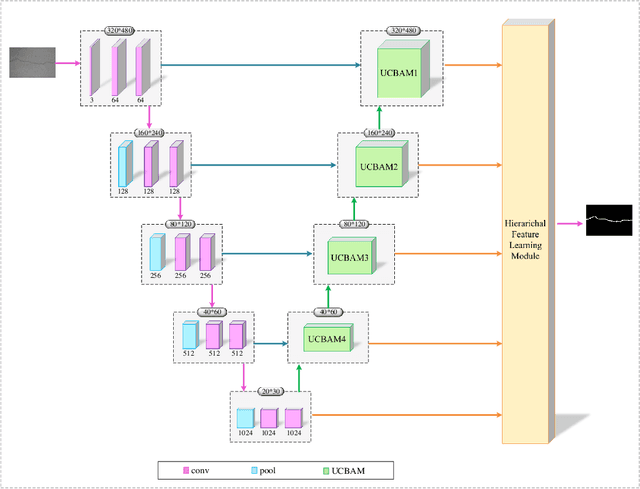
The acquisition and evaluation of pavement surface data play an essential role in pavement condition evaluation. In this paper, an efficient and effective end-to-end network for automatic pavement crack segmentation, called RHA-Net, is proposed to improve the pavement crack segmentation accuracy. The RHA-Net is built by integrating residual blocks (ResBlocks) and hybrid attention blocks into the encoder-decoder architecture. The ResBlocks are used to improve the ability of RHA-Net to extract high-level abstract features. The hybrid attention blocks are designed to fuse both low-level features and high-level features to help the model focus on correct channels and areas of cracks, thereby improving the feature presentation ability of RHA-Net. An image data set containing 789 pavement crack images collected by a self-designed mobile robot is constructed and used for training and evaluating the proposed model. Compared with other state-of-the-art networks, the proposed model achieves better performance and the functionalities of adding residual blocks and hybrid attention mechanisms are validated in a comprehensive ablation study. Additionally, a light-weighted version of the model generated by introducing depthwise separable convolution achieves better a performance and a much faster processing speed with 1/30 of the number of U-Net parameters. The developed system can segment pavement crack in real-time on an embedded device Jetson TX2 (25 FPS). The video taken in real-time experiments is released at https://youtu.be/3XIogk0fiG4.
AGENT: An Adaptive Grouping Entrapping Method of Flocking Systems
Jun 25, 2022



This study proposes a distributed algorithm that makes agents' adaptive grouping entrap multiple targets via automatic decision making, smooth flocking, and well-distributed entrapping. Agents make their own decisions about which targets to surround based on environmental information. An improved artificial potential field method is proposed to enable agents to smoothly and naturally change the formation to adapt to the environment. The proposed strategies guarantee that the coordination of swarm agents develops the phenomenon of multiple targets entrapping at the swarm level. We validate the performance of the proposed method using simulation experiments and design indicators for the analysis of these simulation and physical experiments.
VGSwarm: A Vision-based Gene Regulation Network for UAVs Swarm Behavior Emergence
Jun 17, 2022
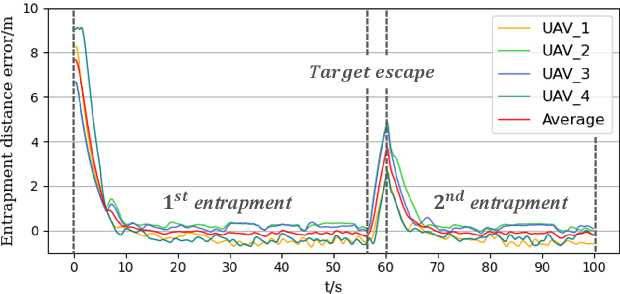

UAVs (Unmanned Aerial Vehicles) dynamic encirclement is an emerging field with great potential. Researchers often get inspirations from biological systems, either from macro-world like fish schools or bird flocks etc, or from micro-world like gene regulatory networks. However, most swarm control algorithms rely on centralized control, global information acquisition, or communication between neighboring agents. In this work, we propose a distributed swarm control method based purely on vision without any direct communications, in which swarm agents of e.g. UAVs can generate an entrapping pattern to encircle an escaping target of UAV based purly on their installed omnidirectional vision sensors. A finite-state-machine describing the behavior model of each individual drone is also designed so that a swarm of drones can accomplish searching and entrapping of the target collectively. We verify the effectiveness and efficiency of the proposed method in various simulation and real-world experiments.
A total hip surgery robot system based on intelligent positioning and optical measurement
Jun 15, 2022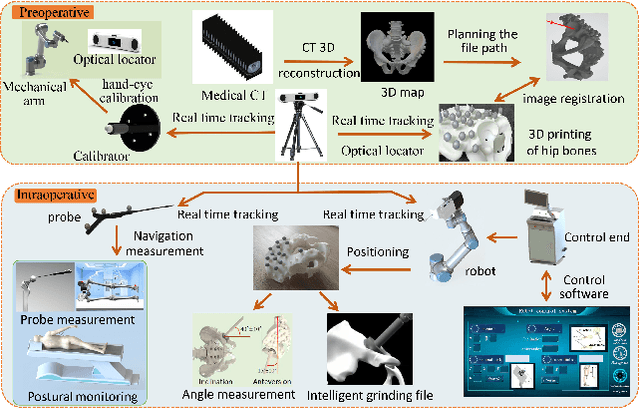

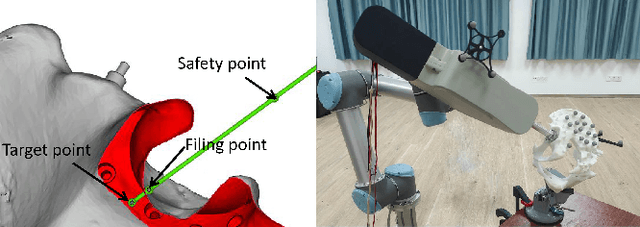
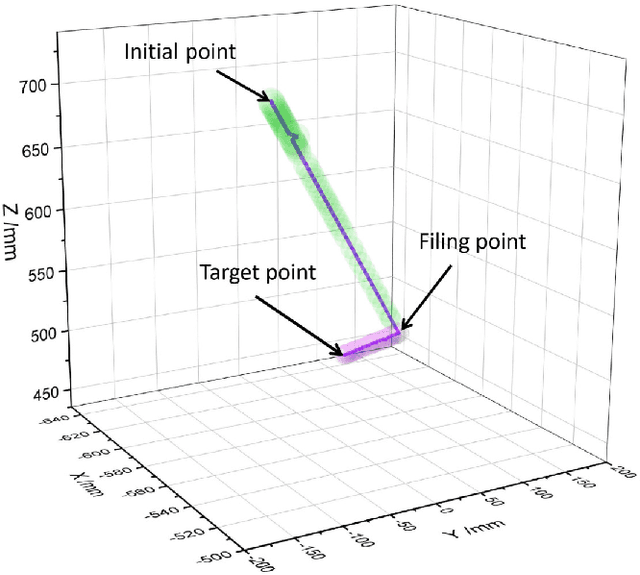
This paper represents the development and experimental evaluation of an autonomous navigation surgical robot system for total hip arthroplasty (THA). Existing robotic systems used in joint replacement surgery have achieved good clinical results, with reported better accuracy. While the surgeon needs to locate the robot arm to the target position during the operation, which is easily affected by the doctor of experience. Yet, the hand-hold acetabulum reamer is easy to appear with uneven strength and grinding file. Further, the lack of steps to measure the femoral neck length may lead to poor results.To tackle this challenge, our design contains the real-time traceable optical positioning strategy to reduce unnecessary manual adjustments to the robotic arm during surgery, the intelligent end-effector system to stable the grinding, and the optical probe to provide real-time measurement of femoral neck length and other parameters to choose the prosthesis. The length of the lower limbs was measured as the prosthesis was installed. Experimental evaluation showed that the robot of precision, execution ability, and robustness are better than expected.
Vision-based Distributed Multi-UAV Collision Avoidance via Deep Reinforcement Learning for Navigation
Mar 05, 2022
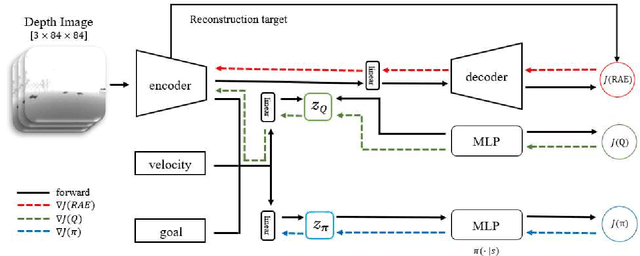
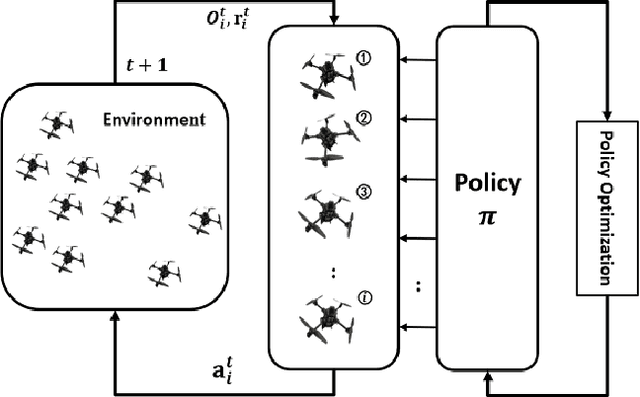
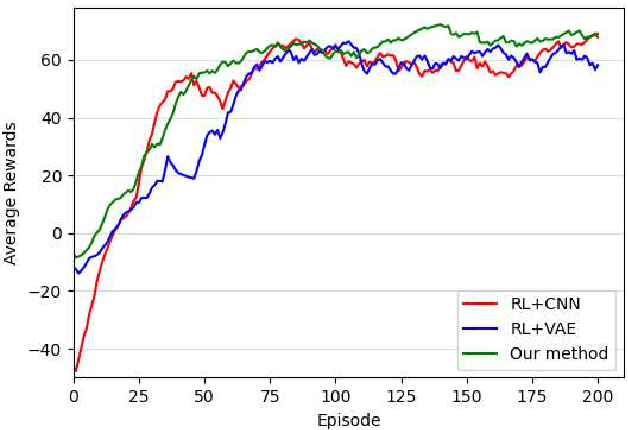
Online path planning for multiple unmanned aerial vehicle (multi-UAV) systems is considered a challenging task. It needs to ensure collision-free path planning in real-time, especially when the multi-UAV systems can become very crowded on certain occasions. In this paper, we presented a vision-based decentralized collision-avoidance policy for multi-UAV systems, which takes depth images and inertial measurements as sensory inputs and outputs UAV's steering commands. The policy is trained together with the latent representation of depth images using a policy gradient-based reinforcement learning algorithm and autoencoder in the multi-UAV threedimensional workspaces. Each UAV follows the same trained policy and acts independently to reach the goal without colliding or communicating with other UAVs. We validate our policy in various simulated scenarios. The experimental results show that our learned policy can guarantee fully autonomous collision-free navigation for multi-UAV in the three-dimensional workspaces with good robustness and scalability.
CI-Net: Contextual Information for Joint Semantic Segmentation and Depth Estimation
Jul 29, 2021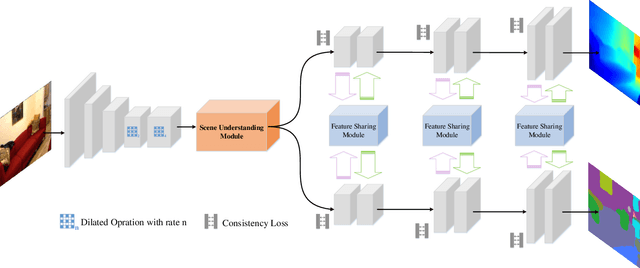
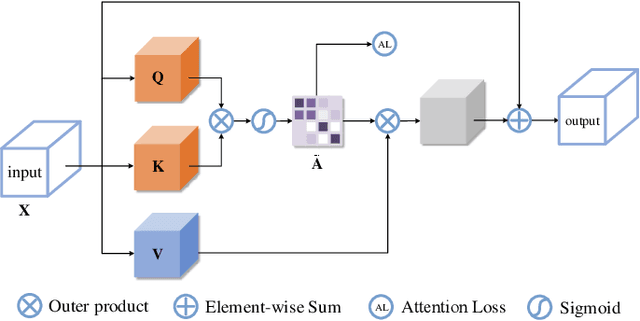
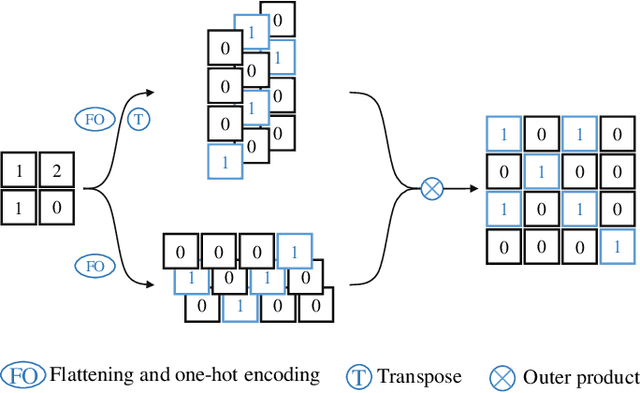
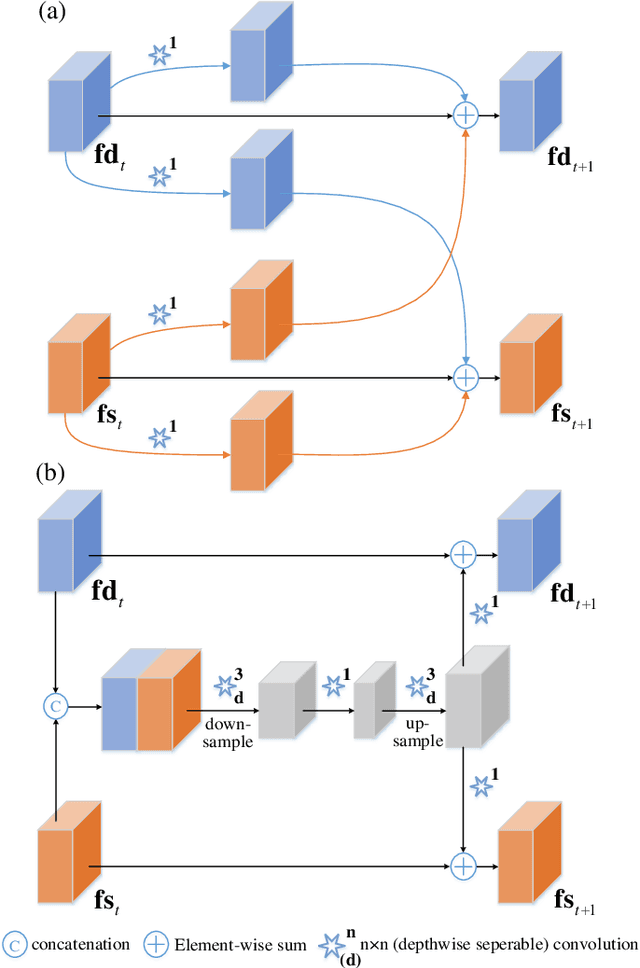
Monocular depth estimation and semantic segmentation are two fundamental goals of scene understanding. Due to the advantages of task interaction, many works study the joint task learning algorithm. However, most existing methods fail to fully leverage the semantic labels, ignoring the provided context structures and only using them to supervise the prediction of segmentation split. In this paper, we propose a network injected with contextual information (CI-Net) to solve the problem. Specifically, we introduce self-attention block in the encoder to generate attention map. With supervision from the ground truth created by semantic labels, the network is embedded with contextual information so that it could understand the scene better, utilizing dependent features to make accurate prediction. Besides, a feature sharing module is constructed to make the task-specific features deeply fused and a consistency loss is devised to make the features mutually guided. We evaluate the proposed CI-Net on the NYU-Depth-v2 and SUN-RGBD datasets. The experimental results validate that our proposed CI-Net is competitive with the state-of-the-arts.
Genetic U-Net: Automatically Designing Lightweight U-shaped CNN Architectures Using the Genetic Algorithm for Retinal Vessel Segmentation
Nov 03, 2020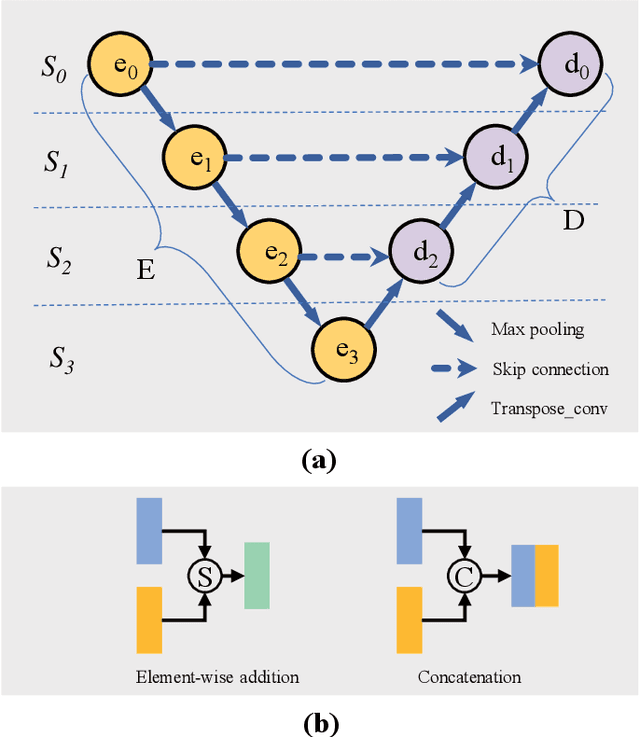
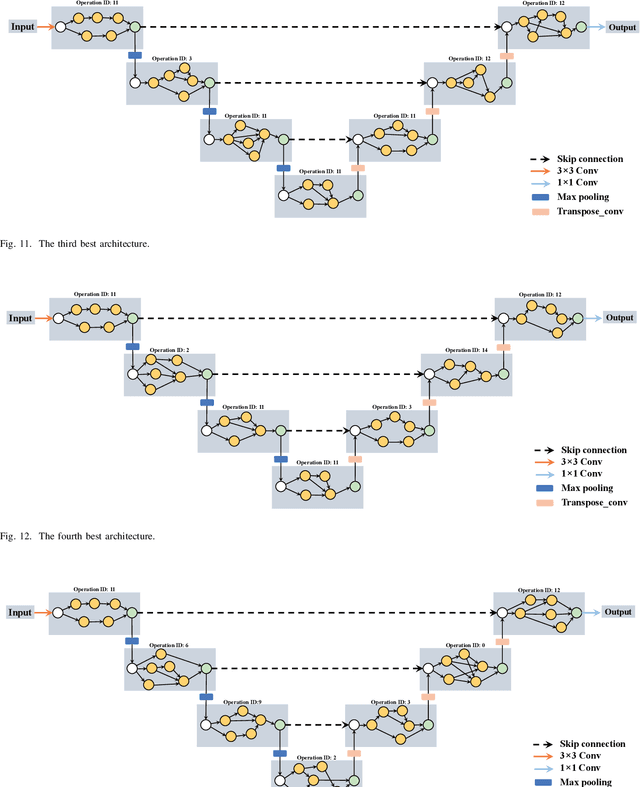
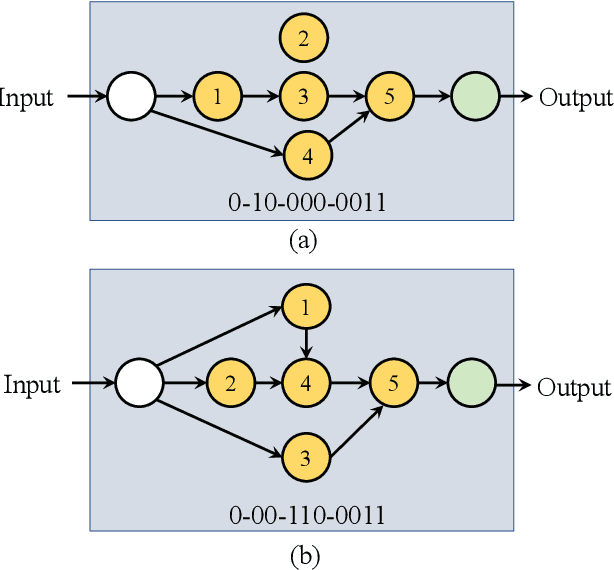
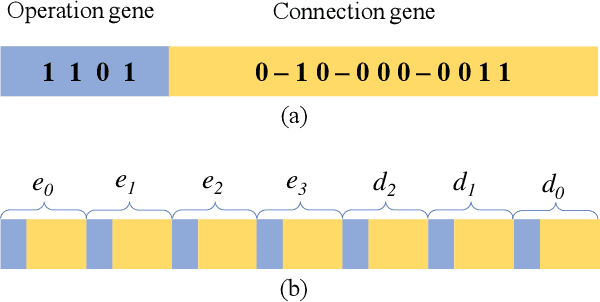
Many previous works based on deep learning for retinal vessel segmentation have achieved promising performance by manually designing U-shaped convolutional neural networks (CNNs). However, the manual design of these CNNs is time-consuming and requires extensive empirical knowledge. To address this problem, we propose a novel method using genetic algorithms (GAs) to automatically design a lightweight U-shaped CNN for retinal vessel segmentation, called Genetic U-Net. Here we first design a special search space containing the structure of U-Net and its corresponding operations, and then use genetic algorithm to search for superior architectures in this search space. Experimental results show that the proposed method outperforms the existing methods on three public datasets, DRIVE, CHASE\_DB1 and STARE. In addition, the architectures obtained by the proposed method are more lightweight but accurate than the state-of-the-art models.