 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Few-Shot Image Fusion: Granular Ball Priors Enable General-Purpose Deep Fusion
Apr 17, 2025



In image fusion tasks, the absence of real fused images as priors presents a fundamental challenge. Most deep learning-based fusion methods rely on large-scale paired datasets to extract global weighting features from raw images, thereby generating fused outputs that approximate real fused images. In contrast to previous studies, this paper explores few-shot training of neural networks under the condition of having prior knowledge. We propose a novel fusion framework named GBFF, and a Granular Ball Significant Extraction algorithm specifically designed for the few-shot prior setting. All pixel pairs involved in the fusion process are initially modeled as a Coarse-Grained Granular Ball. At the local level, Fine-Grained Granular Balls are used to slide through the brightness space to extract Non-Salient Pixel Pairs, and perform splitting operations to obtain Salient Pixel Pairs. Pixel-wise weights are then computed to generate a pseudo-supervised image. At the global level, pixel pairs with significant contributions to the fusion process are categorized into the Positive Region, while those whose contributions cannot be accurately determined are assigned to the Boundary Region. The Granular Ball performs modality-aware adaptation based on the proportion of the positive region, thereby adjusting the neural network's loss function and enabling it to complement the information of the boundary region. Extensive experiments demonstrate the effectiveness of both the proposed algorithm and the underlying theory. Compared with state-of-the-art (SOTA) methods, our approach shows strong competitiveness in terms of both fusion time and image expressiveness. Our code is publicly available at:
Rethinking Few-Shot Fusion: Granular Ball Priors Enable General-Purpose Deep Image Fusion
Apr 11, 2025In image fusion tasks, due to the lack of real fused images as priors, most deep learning-based fusion methods obtain global weight features from original images in large-scale data pairs to generate images that approximate real fused images. However, unlike previous studies, this paper utilizes Granular Ball adaptation to extract features in the brightness space as priors for deep networks, enabling the fusion network to converge quickly and complete the fusion task. This leads to few-shot training for a general image fusion network, and based on this, we propose the GBFF fusion method. According to the information expression division of pixel pairs in the original fused image, we classify pixel pairs with significant performance as the positive domain and non-significant pixel pairs as the boundary domain. We perform split inference in the brightness space using Granular Ball adaptation to compute weights for pixels that express information to varying degrees, generating approximate supervision images that provide priors for the neural network in the structural brightness space. Additionally, the extracted global saliency features also adaptively provide priors for setting the loss function weights of each image in the network, guiding the network to converge quickly at both global and pixel levels alongside the supervised images, thereby enhancing the expressiveness of the fused images. Each modality only used 10 pairs of images as the training set, completing the fusion task with a limited number of iterations. Experiments validate the effectiveness of the algorithm and theory, and qualitative and quantitative comparisons with SOTA methods show that this approach is highly competitive in terms of fusion time and image expressiveness.
Blind2Sound: Self-Supervised Image Denoising without Residual Noise
Mar 14, 2023



Self-supervised blind denoising for Poisson-Gaussian noise remains a challenging task. Pseudo-supervised pairs constructed from single noisy images re-corrupt the signal and degrade the performance. The visible blindspots solve the information loss in masked inputs. However, without explicitly noise sensing, mean square error as an objective function cannot adjust denoising intensities for dynamic noise levels, leading to noticeable residual noise. In this paper, we propose Blind2Sound, a simple yet effective approach to overcome residual noise in denoised images. The proposed adaptive re-visible loss senses noise levels and performs personalized denoising without noise residues while retaining the signal lossless. The theoretical analysis of intermediate medium gradients guarantees stable training, while the Cramer Gaussian loss acts as a regularization to facilitate the accurate perception of noise levels and improve the performance of the denoiser. Experiments on synthetic and real-world datasets show the superior performance of our method, especially for single-channel images.
Vision-based Distributed Multi-UAV Collision Avoidance via Deep Reinforcement Learning for Navigation
Mar 05, 2022
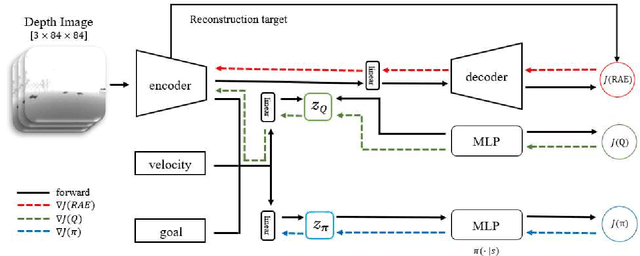
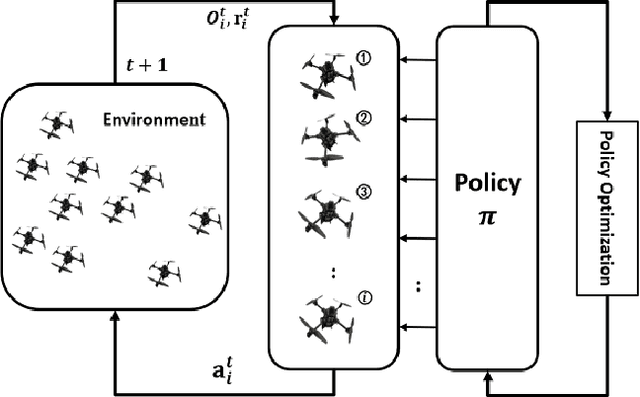
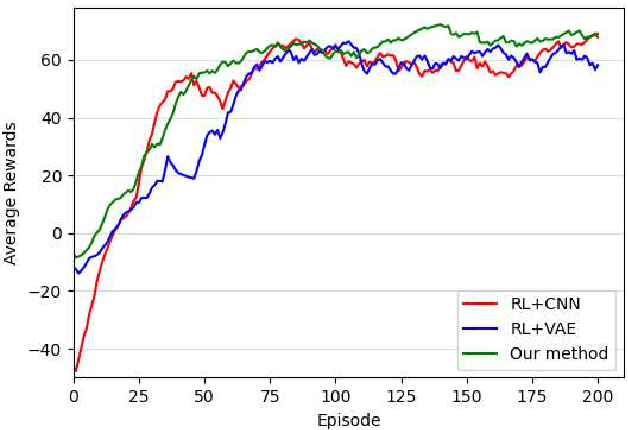
Online path planning for multiple unmanned aerial vehicle (multi-UAV) systems is considered a challenging task. It needs to ensure collision-free path planning in real-time, especially when the multi-UAV systems can become very crowded on certain occasions. In this paper, we presented a vision-based decentralized collision-avoidance policy for multi-UAV systems, which takes depth images and inertial measurements as sensory inputs and outputs UAV's steering commands. The policy is trained together with the latent representation of depth images using a policy gradient-based reinforcement learning algorithm and autoencoder in the multi-UAV threedimensional workspaces. Each UAV follows the same trained policy and acts independently to reach the goal without colliding or communicating with other UAVs. We validate our policy in various simulated scenarios. The experimental results show that our learned policy can guarantee fully autonomous collision-free navigation for multi-UAV in the three-dimensional workspaces with good robustness and scalability.