 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroMamba: Multi-Perspective Feature Interaction with Visual Mamba for Neuron Segmentation
Jan 22, 2026Neuron segmentation is the cornerstone of reconstructing comprehensive neuronal connectomes, which is essential for deciphering the functional organization of the brain. The irregular morphology and densely intertwined structures of neurons make this task particularly challenging. Prevailing CNN-based methods often fail to resolve ambiguous boundaries due to the lack of long-range context, whereas Transformer-based methods suffer from boundary imprecision caused by the loss of voxel-level details during patch partitioning. To address these limitations, we propose NeuroMamba, a multi-perspective framework that exploits the linear complexity of Mamba to enable patch-free global modeling and synergizes this with complementary local feature modeling, thereby efficiently capturing long-range dependencies while meticulously preserving fine-grained voxel details. Specifically, we design a channel-gated Boundary Discriminative Feature Extractor (BDFE) to enhance local morphological cues. Complementing this, we introduce the Spatial Continuous Feature Extractor (SCFE), which integrates a resolution-aware scanning mechanism into the Visual Mamba architecture to adaptively model global dependencies across varying data resolutions. Finally, a cross-modulation mechanism synergistically fuses these multi-perspective features. Our method demonstrates state-of-the-art performance across four public EM datasets, validating its exceptional adaptability to both anisotropic and isotropic resolutions. The source code will be made publicly available.
Taking Notes Brings Focus? Towards Multi-Turn Multimodal Dialogue Learning
Mar 10, 2025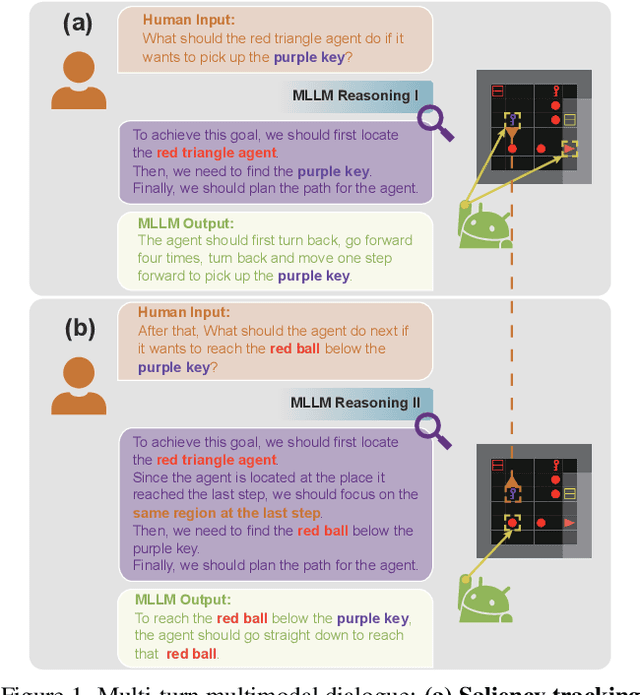

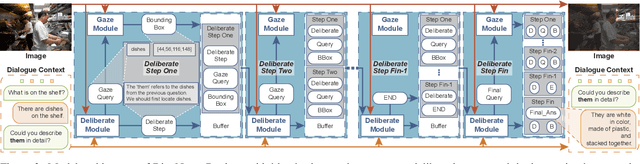
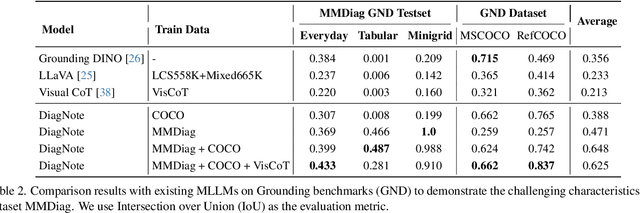
Multimodal large language models (MLLMs), built on large-scale pre-trained vision towers and language models, have shown great capabilities in multimodal understanding. However, most existing MLLMs are trained on single-turn vision question-answering tasks, which do not accurately reflect real-world human conversations. In this paper, we introduce MMDiag, a multi-turn multimodal dialogue dataset. This dataset is collaboratively generated through deliberately designed rules and GPT assistance, featuring strong correlations between questions, between questions and images, and among different image regions; thus aligning more closely with real-world scenarios. MMDiag serves as a strong benchmark for multi-turn multimodal dialogue learning and brings more challenges to the grounding and reasoning capabilities of MLLMs. Further, inspired by human vision processing, we present DiagNote, an MLLM equipped with multimodal grounding and reasoning capabilities. DiagNote consists of two modules (Deliberate and Gaze) interacting with each other to perform Chain-of-Thought and annotations respectively, throughout multi-turn dialogues. We empirically demonstrate the advantages of DiagNote in both grounding and jointly processing and reasoning with vision and language information over existing MLLMs.
Steve-Eye: Equipping LLM-based Embodied Agents with Visual Perception in Open Worlds
Oct 20, 2023



Recent studies have presented compelling evidence that large language models (LLMs) can equip embodied agents with the self-driven capability to interact with the world, which marks an initial step toward versatile robotics. However, these efforts tend to overlook the visual richness of open worlds, rendering the entire interactive process akin to "a blindfolded text-based game." Consequently, LLM-based agents frequently encounter challenges in intuitively comprehending their surroundings and producing responses that are easy to understand. In this paper, we propose Steve-Eye, an end-to-end trained large multimodal model designed to address this limitation. Steve-Eye integrates the LLM with a visual encoder which enables it to process visual-text inputs and generate multimodal feedback. In addition, we use a semi-automatic strategy to collect an extensive dataset comprising 850K open-world instruction pairs, empowering our model to encompass three essential functions for an agent: multimodal perception, foundational knowledge base, and skill prediction and planning. Lastly, we develop three open-world evaluation benchmarks, then carry out extensive experiments from a wide range of perspectives to validate our model's capability to strategically act and plan. Codes and datasets will be released.
LLaMA Rider: Spurring Large Language Models to Explore the Open World
Oct 13, 2023



Recently, various studies have leveraged Large Language Models (LLMs) to help decision-making and planning in environments, and try to align the LLMs' knowledge with the world conditions. Nonetheless, the capacity of LLMs to continuously acquire environmental knowledge and adapt in an open world remains uncertain. In this paper, we propose an approach to spur LLMs to explore the open world, gather experiences, and learn to improve their task-solving capabilities. In this approach, a multi-round feedback-revision mechanism is utilized to encourage LLMs to actively select appropriate revision actions guided by feedback information from the environment. This facilitates exploration and enhances the model's performance. Besides, we integrate sub-task relabeling to assist LLMs in maintaining consistency in sub-task planning and help the model learn the combinatorial nature between tasks, enabling it to complete a wider range of tasks through training based on the acquired exploration experiences. By evaluation in Minecraft, an open-ended sandbox world, we demonstrate that our approach LLaMA-Rider enhances the efficiency of the LLM in exploring the environment, and effectively improves the LLM's ability to accomplish more tasks through fine-tuning with merely 1.3k instances of collected data, showing minimal training costs compared to the baseline using reinforcement learning.
Blind2Sound: Self-Supervised Image Denoising without Residual Noise
Mar 14, 2023



Self-supervised blind denoising for Poisson-Gaussian noise remains a challenging task. Pseudo-supervised pairs constructed from single noisy images re-corrupt the signal and degrade the performance. The visible blindspots solve the information loss in masked inputs. However, without explicitly noise sensing, mean square error as an objective function cannot adjust denoising intensities for dynamic noise levels, leading to noticeable residual noise. In this paper, we propose Blind2Sound, a simple yet effective approach to overcome residual noise in denoised images. The proposed adaptive re-visible loss senses noise levels and performs personalized denoising without noise residues while retaining the signal lossless. The theoretical analysis of intermediate medium gradients guarantees stable training, while the Cramer Gaussian loss acts as a regularization to facilitate the accurate perception of noise levels and improve the performance of the denoiser. Experiments on synthetic and real-world datasets show the superior performance of our method, especially for single-channel images.
Blind2Unblind: Self-Supervised Image Denoising with Visible Blind Spots
Mar 15, 2022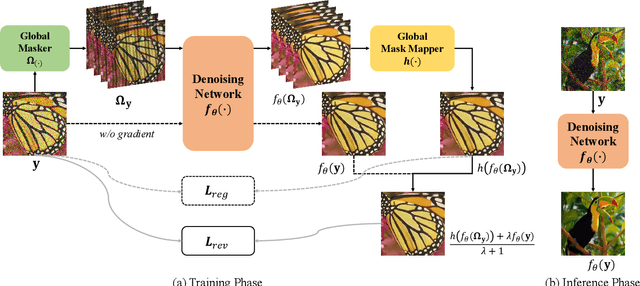
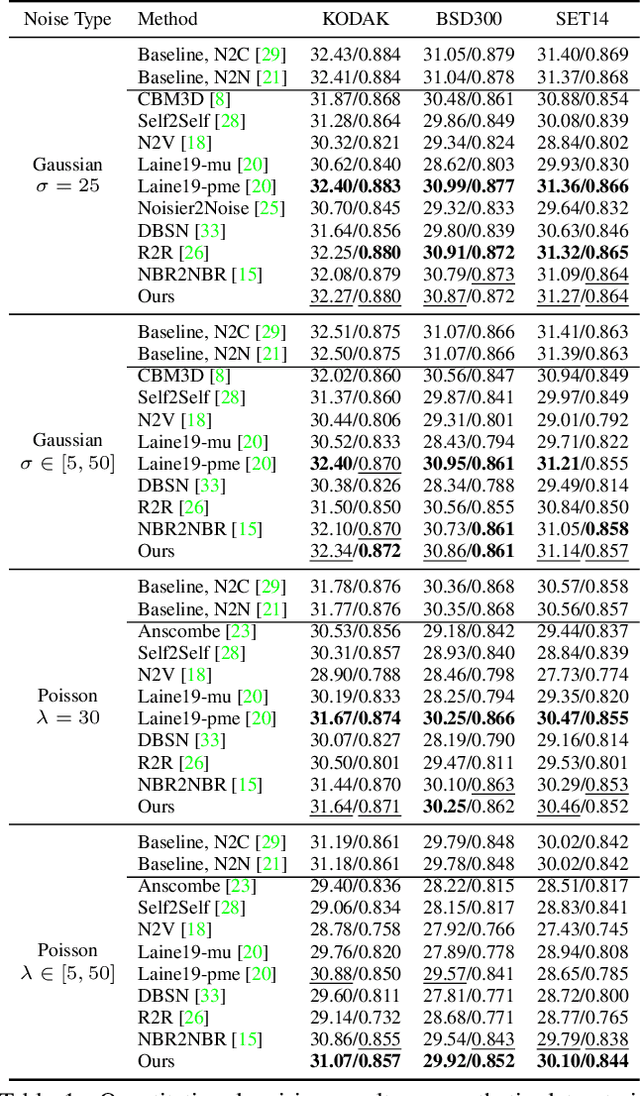
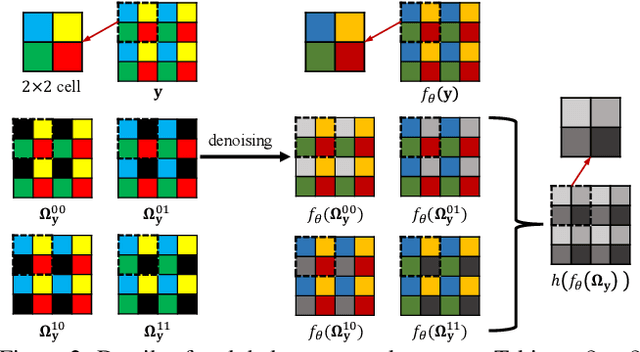
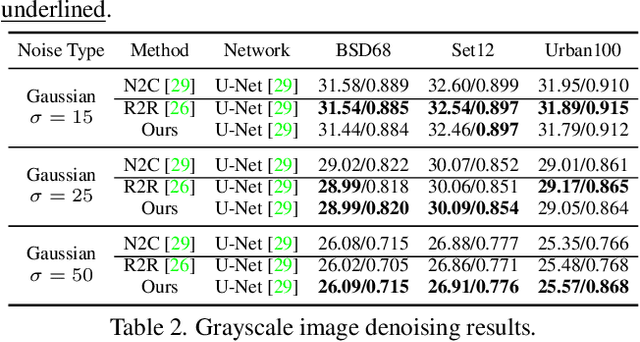
Real noisy-clean pairs on a large scale are costly and difficult to obtain. Meanwhile, supervised denoisers trained on synthetic data perform poorly in practice. Self-supervised denoisers, which learn only from single noisy images, solve the data collection problem. However, self-supervised denoising methods, especially blindspot-driven ones, suffer sizable information loss during input or network design. The absence of valuable information dramatically reduces the upper bound of denoising performance. In this paper, we propose a simple yet efficient approach called Blind2Unblind to overcome the information loss in blindspot-driven denoising methods. First, we introduce a global-aware mask mapper that enables global perception and accelerates training. The mask mapper samples all pixels at blind spots on denoised volumes and maps them to the same channel, allowing the loss function to optimize all blind spots at once. Second, we propose a re-visible loss to train the denoising network and make blind spots visible. The denoiser can learn directly from raw noise images without losing information or being trapped in identity mapping. We also theoretically analyze the convergence of the re-visible loss. Extensive experiments on synthetic and real-world datasets demonstrate the superior performance of our approach compared to previous work. Code is available at https://github.com/demonsjin/Blind2Unblind.