 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommCP: Efficient Multi-Agent Coordination via LLM-Based Communication with Conformal Prediction
Feb 05, 2026To complete assignments provided by humans in natural language, robots must interpret commands, generate and answer relevant questions for scene understanding, and manipulate target objects. Real-world deployments often require multiple heterogeneous robots with different manipulation capabilities to handle different assignments cooperatively. Beyond the need for specialized manipulation skills, effective information gathering is important in completing these assignments. To address this component of the problem, we formalize the information-gathering process in a fully cooperative setting as an underexplored multi-agent multi-task Embodied Question Answering (MM-EQA) problem, which is a novel extension of canonical Embodied Question Answering (EQA), where effective communication is crucial for coordinating efforts without redundancy. To address this problem, we propose CommCP, a novel LLM-based decentralized communication framework designed for MM-EQA. Our framework employs conformal prediction to calibrate the generated messages, thereby minimizing receiver distractions and enhancing communication reliability. To evaluate our framework, we introduce an MM-EQA benchmark featuring diverse, photo-realistic household scenarios with embodied questions. Experimental results demonstrate that CommCP significantly enhances the task success rate and exploration efficiency over baselines. The experiment videos, code, and dataset are available on our project website: https://comm-cp.github.io.
Towards Generalizable Safety in Crowd Navigation via Conformal Uncertainty Handling
Aug 07, 2025Mobile robots navigating in crowds trained using reinforcement learning are known to suffer performance degradation when faced with out-of-distribution scenarios. We propose that by properly accounting for the uncertainties of pedestrians, a robot can learn safe navigation policies that are robust to distribution shifts. Our method augments agent observations with prediction uncertainty estimates generated by adaptive conformal inference, and it uses these estimates to guide the agent's behavior through constrained reinforcement learning. The system helps regulate the agent's actions and enables it to adapt to distribution shifts. In the in-distribution setting, our approach achieves a 96.93% success rate, which is over 8.80% higher than the previous state-of-the-art baselines with over 3.72 times fewer collisions and 2.43 times fewer intrusions into ground-truth human future trajectories. In three out-of-distribution scenarios, our method shows much stronger robustness when facing distribution shifts in velocity variations, policy changes, and transitions from individual to group dynamics. We deploy our method on a real robot, and experiments show that the robot makes safe and robust decisions when interacting with both sparse and dense crowds. Our code and videos are available on https://gen-safe-nav.github.io/.
SoNIC: Safe Social Navigation with Adaptive Conformal Inference and Constrained Reinforcement Learning
Jul 24, 2024Reinforcement Learning (RL) has enabled social robots to generate trajectories without human-designed rules or interventions, which makes it more effective than hard-coded systems for generalizing to complex real-world scenarios. However, social navigation is a safety-critical task that requires robots to avoid collisions with pedestrians while previous RL-based solutions fall short in safety performance in complex environments. To enhance the safety of RL policies, to the best of our knowledge, we propose the first algorithm, SoNIC, that integrates adaptive conformal inference (ACI) with constrained reinforcement learning (CRL) to learn safe policies for social navigation. More specifically, our method augments RL observations with ACI-generated nonconformity scores and provides explicit guidance for agents to leverage the uncertainty metrics to avoid safety-critical areas by incorporating safety constraints with spatial relaxation. Our method outperforms state-of-the-art baselines in terms of both safety and adherence to social norms by a large margin and demonstrates much stronger robustness to out-of-distribution scenarios. Our code and video demos are available on our project website: https://sonic-social-nav.github.io/.
Enhancing RAW-to-sRGB with Decoupled Style Structure in Fourier Domain
Jan 04, 2024


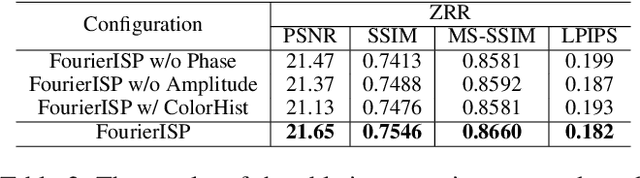
RAW to sRGB mapping, which aims to convert RAW images from smartphones into RGB form equivalent to that of Digital Single-Lens Reflex (DSLR) cameras, has become an important area of research. However, current methods often ignore the difference between cell phone RAW images and DSLR camera RGB images, a difference that goes beyond the color matrix and extends to spatial structure due to resolution variations. Recent methods directly rebuild color mapping and spatial structure via shared deep representation, limiting optimal performance. Inspired by Image Signal Processing (ISP) pipeline, which distinguishes image restoration and enhancement, we present a novel Neural ISP framework, named FourierISP. This approach breaks the image down into style and structure within the frequency domain, allowing for independent optimization. FourierISP is comprised of three subnetworks: Phase Enhance Subnet for structural refinement, Amplitude Refine Subnet for color learning, and Color Adaptation Subnet for blending them in a smooth manner. This approach sharpens both color and structure, and extensive evaluations across varied datasets confirm that our approach realizes state-of-the-art results. Code will be available at ~\url{https://github.com/alexhe101/FourierISP}.
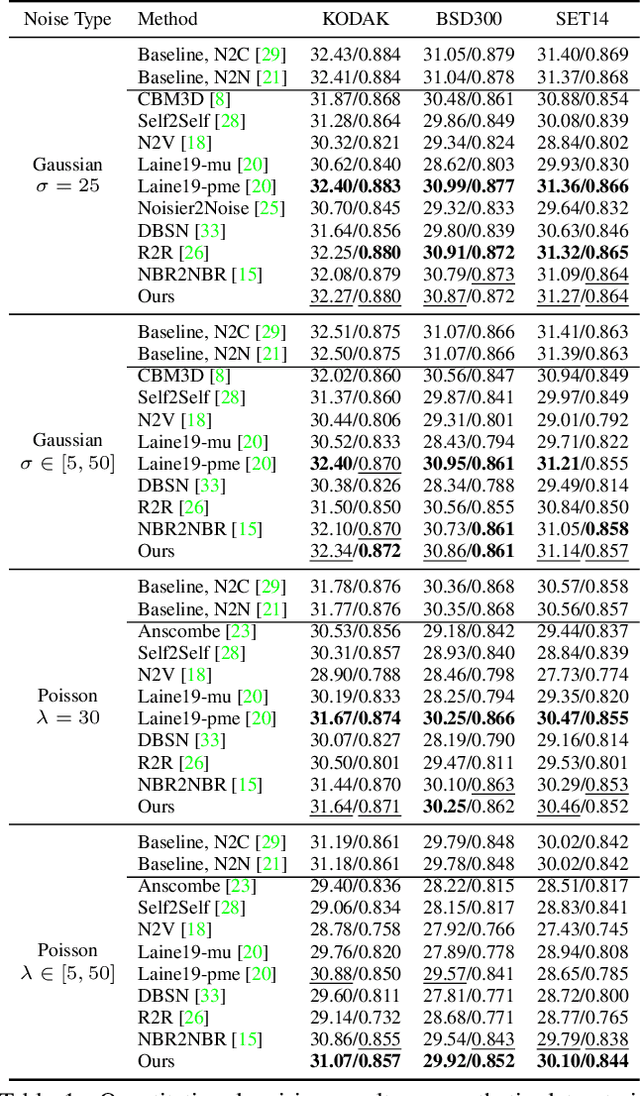
Blind2Sound: Self-Supervised Image Denoising without Residual Noise
Mar 14, 2023



Self-supervised blind denoising for Poisson-Gaussian noise remains a challenging task. Pseudo-supervised pairs constructed from single noisy images re-corrupt the signal and degrade the performance. The visible blindspots solve the information loss in masked inputs. However, without explicitly noise sensing, mean square error as an objective function cannot adjust denoising intensities for dynamic noise levels, leading to noticeable residual noise. In this paper, we propose Blind2Sound, a simple yet effective approach to overcome residual noise in denoised images. The proposed adaptive re-visible loss senses noise levels and performs personalized denoising without noise residues while retaining the signal lossless. The theoretical analysis of intermediate medium gradients guarantees stable training, while the Cramer Gaussian loss acts as a regularization to facilitate the accurate perception of noise levels and improve the performance of the denoiser. Experiments on synthetic and real-world datasets show the superior performance of our method, especially for single-channel images.
Blind2Unblind: Self-Supervised Image Denoising with Visible Blind Spots
Mar 15, 2022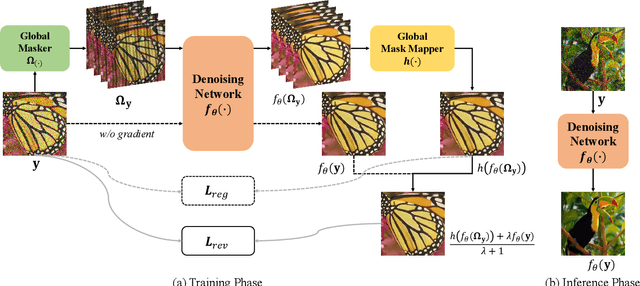
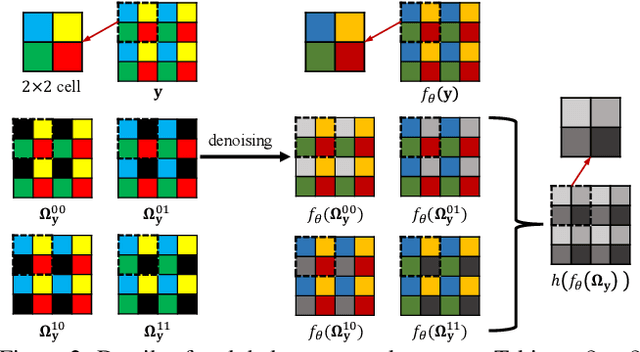
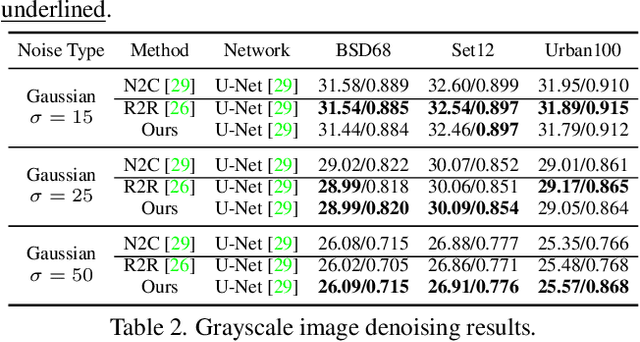
Real noisy-clean pairs on a large scale are costly and difficult to obtain. Meanwhile, supervised denoisers trained on synthetic data perform poorly in practice. Self-supervised denoisers, which learn only from single noisy images, solve the data collection problem. However, self-supervised denoising methods, especially blindspot-driven ones, suffer sizable information loss during input or network design. The absence of valuable information dramatically reduces the upper bound of denoising performance. In this paper, we propose a simple yet efficient approach called Blind2Unblind to overcome the information loss in blindspot-driven denoising methods. First, we introduce a global-aware mask mapper that enables global perception and accelerates training. The mask mapper samples all pixels at blind spots on denoised volumes and maps them to the same channel, allowing the loss function to optimize all blind spots at once. Second, we propose a re-visible loss to train the denoising network and make blind spots visible. The denoiser can learn directly from raw noise images without losing information or being trapped in identity mapping. We also theoretically analyze the convergence of the re-visible loss. Extensive experiments on synthetic and real-world datasets demonstrate the superior performance of our approach compared to previous work. Code is available at https://github.com/demonsjin/Blind2Unblind.
Temporal Spatial-Adaptive Interpolation with Deformable Refinement for Electron Microscopic Images
Jan 17, 2021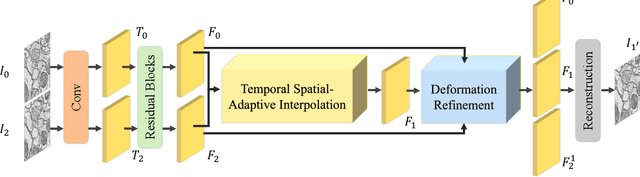

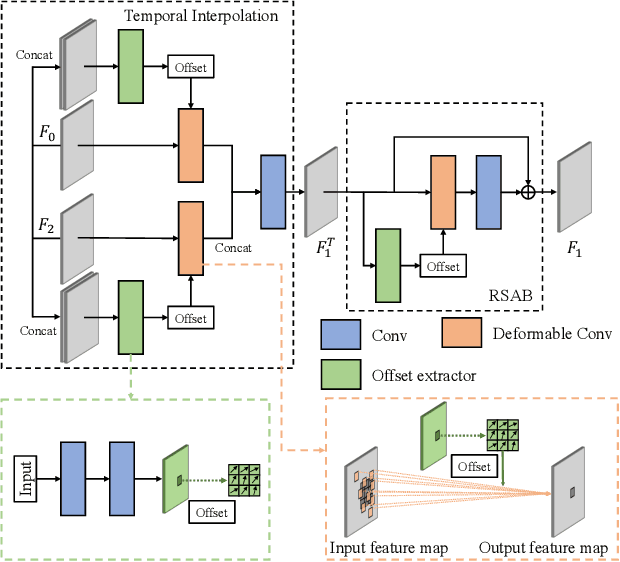
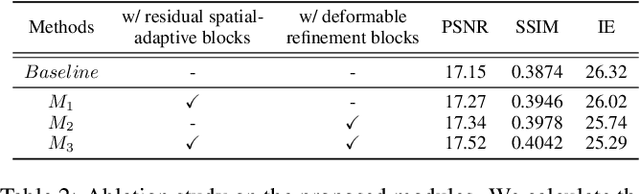
Recently, flow-based methods have achieved promising success in video frame interpolation. However, electron microscopic (EM) images suffer from unstable image quality, low PSNR, and disorderly deformation. Existing flow-based interpolation methods cannot precisely compute optical flow for EM images since only predicting each position's unique offset. To overcome these problems, we propose a novel interpolation framework for EM images that progressively synthesizes interpolated features in a coarse-to-fine manner. First, we extract missing intermediate features by the proposed temporal spatial-adaptive (TSA) interpolation module. The TSA interpolation module aggregates temporal contexts and then adaptively samples the spatial-related features with the proposed residual spatial adaptive block. Second, we introduce a stacked deformable refinement block (SDRB) further enhance the reconstruction quality, which is aware of the matching positions and relevant features from input frames with the feedback mechanism. Experimental results demonstrate the superior performance of our approach compared to previous works, both quantitatively and qualitatively.
DAN: A Deformation-Aware Network for Consecutive Biomedical Image Interpolation
Apr 23, 2020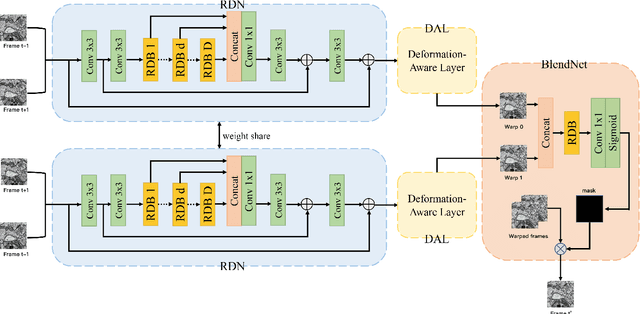
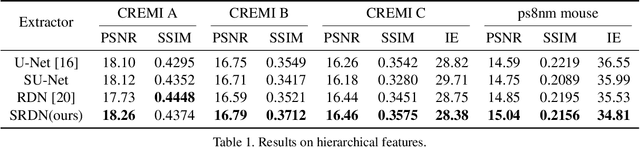
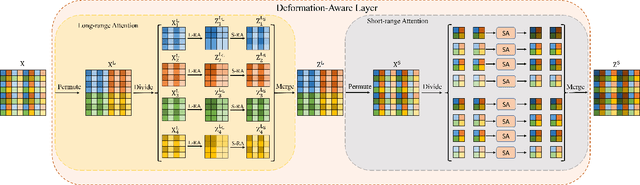
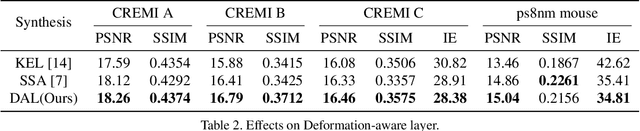
The continuity of biological tissue between consecutive biomedical images makes it possible for the video interpolation algorithm, to recover large area defects and tears that are common in biomedical images. However, noise and blur differences, large deformation, and drift between biomedical images, make the task challenging. To address the problem, this paper introduces a deformation-aware network to synthesize each pixel in accordance with the continuity of biological tissue. First, we develop a deformation-aware layer for consecutive biomedical images interpolation that implicitly adopting global perceptual deformation. Second, we present an adaptive style-balance loss to take the style differences of consecutive biomedical images such as blur and noise into consideration. Guided by the deformation-aware module, we synthesize each pixel from a global domain adaptively which further improves the performance of pixel synthesis. Quantitative and qualitative experiments on the benchmark dataset show that the proposed method is superior to the state-of-the-art approaches.