 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-Driven Lightweight Foundation Model for Instance Segmentation-Based Fault Detection in Freight Trains
Mar 13, 2026Accurate visual fault detection in freight trains remains a critical challenge for intelligent transportation system maintenance, due to complex operational environments, structurally repetitive components, and frequent occlusions or contaminations in safety-critical regions. Conventional instance segmentation methods based on convolutional neural networks and Transformers often suffer from poor generalization and limited boundary accuracy under such conditions. To address these challenges, we propose a lightweight self-prompted instance segmentation framework tailored for freight train fault detection. Our method leverages the Segment Anything Model by introducing a self-prompt generation module that automatically produces task-specific prompts, enabling effective knowledge transfer from foundation models to domain-specific inspection tasks. In addition, we adopt a Tiny Vision Transformer backbone to reduce computational cost, making the framework suitable for real-time deployment on edge devices in railway monitoring systems. We construct a domain-specific dataset collected from real-world freight inspection stations and conduct extensive evaluations. Experimental results show that our method achieves 74.6 $AP^{\text{box}}$ and 74.2 $AP^{\text{mask}}$ on the dataset, outperforming existing state-of-the-art methods in both accuracy and robustness while maintaining low computational overhead. This work offers a deployable and efficient vision solution for automated freight train inspection, demonstrating the potential of foundation model adaptation in industrial-scale fault diagnosis scenarios. Project page: https://github.com/MVME-HBUT/SAM_FTI-FDet.git
Efficient RGB-D Scene Understanding via Multi-task Adaptive Learning and Cross-dimensional Feature Guidance
Mar 08, 2026Scene understanding plays a critical role in enabling intelligence and autonomy in robotic systems. Traditional approaches often face challenges, including occlusions, ambiguous boundaries, and the inability to adapt attention based on task-specific requirements and sample variations. To address these limitations, this paper presents an efficient RGB-D scene understanding model that performs a range of tasks, including semantic segmentation, instance segmentation, orientation estimation, panoptic segmentation, and scene classification. The proposed model incorporates an enhanced fusion encoder, which effectively leverages redundant information from both RGB and depth inputs. For semantic segmentation, we introduce normalized focus channel layers and a context feature interaction layer, designed to mitigate issues such as shallow feature misguidance and insufficient local-global feature representation. The instance segmentation task benefits from a non-bottleneck 1D structure, which achieves superior contour representation with fewer parameters. Additionally, we propose a multi-task adaptive loss function that dynamically adjusts the learning strategy for different tasks based on scene variations. Extensive experiments on the NYUv2, SUN RGB-D, and Cityscapes datasets demonstrate that our approach outperforms existing methods in both segmentation accuracy and processing speed.
WLTCL: Wide Field-of-View 3-D LiDAR Truck Compartment Automatic Localization System
Apr 26, 2025As an essential component of logistics automation, the automated loading system is becoming a critical technology for enhancing operational efficiency and safety. Precise automatic positioning of the truck compartment, which serves as the loading area, is the primary step in automated loading. However, existing methods have difficulty adapting to truck compartments of various sizes, do not establish a unified coordinate system for LiDAR and mobile manipulators, and often exhibit reliability issues in cluttered environments. To address these limitations, our study focuses on achieving precise automatic positioning of key points in large, medium, and small fence-style truck compartments in cluttered scenarios. We propose an innovative wide field-of-view 3-D LiDAR vehicle compartment automatic localization system. For vehicles of various sizes, this system leverages the LiDAR to generate high-density point clouds within an extensive field-of-view range. By incorporating parking area constraints, our vehicle point cloud segmentation method more effectively segments vehicle point clouds within the scene. Our compartment key point positioning algorithm utilizes the geometric features of the compartments to accurately locate the corner points, providing stackable spatial regions. Extensive experiments on our collected data and public datasets demonstrate that this system offers reliable positioning accuracy and reduced computational resource consumption, leading to its application and promotion in relevant fields.
Probabilistic Prior Driven Attention Mechanism Based on Diffusion Model for Imaging Through Atmospheric Turbulence
Nov 15, 2024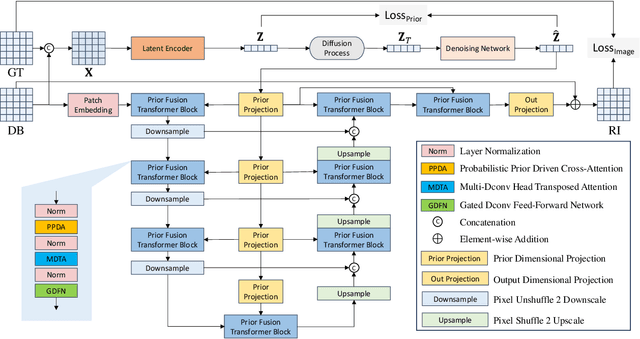
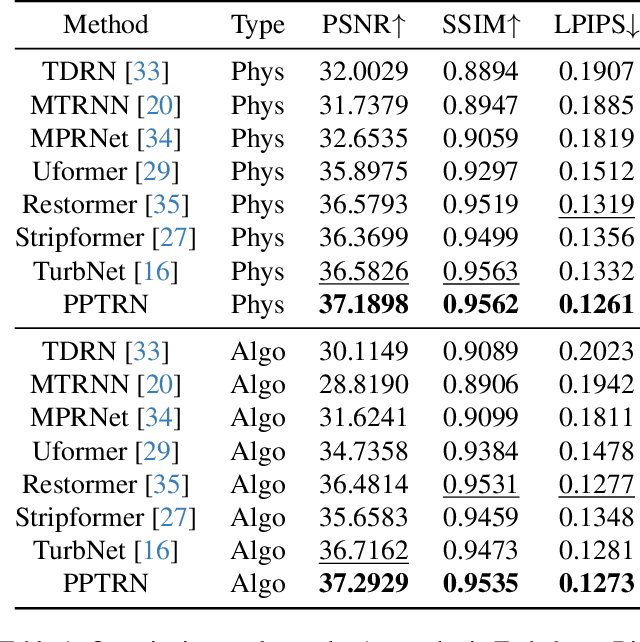
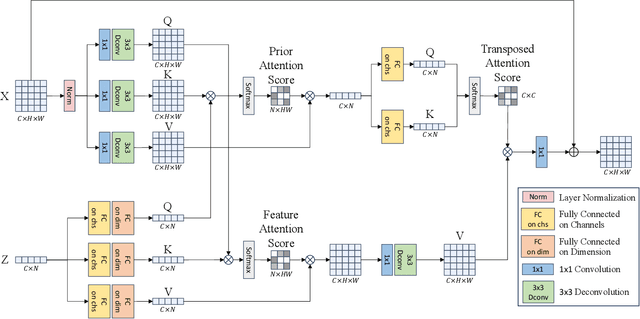

Atmospheric turbulence introduces severe spatial and geometric distortions, challenging traditional image restoration methods. We propose the Probabilistic Prior Turbulence Removal Network (PPTRN), which combines probabilistic diffusion-based prior modeling with Transformer-driven feature extraction to address this issue. PPTRN employs a two-stage approach: first, a latent encoder and Transformer are jointly trained on clear images to establish robust feature representations. Then, a Denoising Diffusion Probabilistic Model (DDPM) models prior distributions over latent vectors, guiding the Transformer in capturing diverse feature variations essential for restoration. A key innovation in PPTRN is the Probabilistic Prior Driven Cross Attention mechanism, which integrates the DDPM-generated prior with feature embeddings to reduce artifacts and enhance spatial coherence. Extensive experiments validate that PPTRN significantly improves restoration quality on turbulence-degraded images, setting a new benchmark in clarity and structural fidelity.
Multiple Prior Representation Learning for Self-Supervised Monocular Depth Estimation via Hybrid Transformer
Jun 13, 2024



Self-supervised monocular depth estimation aims to infer depth information without relying on labeled data. However, the lack of labeled information poses a significant challenge to the model's representation, limiting its ability to capture the intricate details of the scene accurately. Prior information can potentially mitigate this issue, enhancing the model's understanding of scene structure and texture. Nevertheless, solely relying on a single type of prior information often falls short when dealing with complex scenes, necessitating improvements in generalization performance. To address these challenges, we introduce a novel self-supervised monocular depth estimation model that leverages multiple priors to bolster representation capabilities across spatial, context, and semantic dimensions. Specifically, we employ a hybrid transformer and a lightweight pose network to obtain long-range spatial priors in the spatial dimension. Then, the context prior attention is designed to improve generalization, particularly in complex structures or untextured areas. In addition, semantic priors are introduced by leveraging semantic boundary loss, and semantic prior attention is supplemented, further refining the semantic features extracted by the decoder. Experiments on three diverse datasets demonstrate the effectiveness of the proposed model. It integrates multiple priors to comprehensively enhance the representation ability, improving the accuracy and reliability of depth estimation. Codes are available at: \url{https://github.com/MVME-HBUT/MPRLNet}
Scheduling Drone and Mobile Charger via Hybrid-Action Deep Reinforcement Learning
Mar 16, 2024Recently there has been a growing interest in industry and academia, regarding the use of wireless chargers to prolong the operational longevity of unmanned aerial vehicles (commonly knowns as drones). In this paper we consider a charger-assisted drone application: a drone is deployed to observe a set points of interest, while a charger can move to recharge the drone's battery. We focus on the route and charging schedule of the drone and the mobile charger, to obtain high observation utility with the shortest possible time, while ensuring the drone remains operational during task execution. Essentially, this proposed drone-charger scheduling problem is a multi-stage decision-making process, in which the drone and the mobile charger act as two agents who cooperate to finish a task. The discrete-continuous hybrid action space of the two agents poses a significant challenge in our problem. To address this issue, we present a hybrid-action deep reinforcement learning framework, called HaDMC, which uses a standard policy learning algorithm to generate latent continuous actions. Motivated by representation learning, we specifically design and train an action decoder. It involves two pipelines to convert the latent continuous actions into original discrete and continuous actions, by which the drone and the charger can directly interact with environment. We embed a mutual learning scheme in model training, emphasizing the collaborative rather than individual actions. We conduct extensive numerical experiments to evaluate HaDMC and compare it with state-of-the-art deep reinforcement learning approaches. The experimental results show the effectiveness and efficiency of our solution.
An Efficient MLP-based Point-guided Segmentation Network for Ore Images with Ambiguous Boundary
Feb 27, 2024



The precise segmentation of ore images is critical to the successful execution of the beneficiation process. Due to the homogeneous appearance of the ores, which leads to low contrast and unclear boundaries, accurate segmentation becomes challenging, and recognition becomes problematic. This paper proposes a lightweight framework based on Multi-Layer Perceptron (MLP), which focuses on solving the problem of edge burring. Specifically, we introduce a lightweight backbone better suited for efficiently extracting low-level features. Besides, we design a feature pyramid network consisting of two MLP structures that balance local and global information thus enhancing detection accuracy. Furthermore, we propose a novel loss function that guides the prediction points to match the instance edge points to achieve clear object boundaries. We have conducted extensive experiments to validate the efficacy of our proposed method. Our approach achieves a remarkable processing speed of over 27 frames per second (FPS) with a model size of only 73 MB. Moreover, our method delivers a consistently high level of accuracy, with impressive performance scores of 60.4 and 48.9 in~$AP_{50}^{box}$ and~$AP_{50}^{mask}$ respectively, as compared to the currently available state-of-the-art techniques, when tested on the ore image dataset. The source code will be released at \url{https://github.com/MVME-HBUT/ORENEXT}.
Efficient Segmentation with Texture in Ore Images Based on Box-supervised Approach
Nov 10, 2023



Image segmentation methods have been utilized to determine the particle size distribution of crushed ores. Due to the complex working environment, high-powered computing equipment is difficult to deploy. At the same time, the ore distribution is stacked, and it is difficult to identify the complete features. To address this issue, an effective box-supervised technique with texture features is provided for ore image segmentation that can identify complete and independent ores. Firstly, a ghost feature pyramid network (Ghost-FPN) is proposed to process the features obtained from the backbone to reduce redundant semantic information and computation generated by complex networks. Then, an optimized detection head is proposed to obtain the feature to maintain accuracy. Finally, Lab color space (Lab) and local binary patterns (LBP) texture features are combined to form a fusion feature similarity-based loss function to improve accuracy while incurring no loss. Experiments on MS COCO have shown that the proposed fusion features are also worth studying on other types of datasets. Extensive experimental results demonstrate the effectiveness of the proposed method, which achieves over 50 frames per second with a small model size of 21.6 MB. Meanwhile, the method maintains a high level of accuracy compared with the state-of-the-art approaches on ore image dataset. The source code is available at \url{https://github.com/MVME-HBUT/OREINST}.
Spatial-information Guided Adaptive Context-aware Network for Efficient RGB-D Semantic Segmentation
Aug 11, 2023



Efficient RGB-D semantic segmentation has received considerable attention in mobile robots, which plays a vital role in analyzing and recognizing environmental information. According to previous studies, depth information can provide corresponding geometric relationships for objects and scenes, but actual depth data usually exist as noise. To avoid unfavorable effects on segmentation accuracy and computation, it is necessary to design an efficient framework to leverage cross-modal correlations and complementary cues. In this paper, we propose an efficient lightweight encoder-decoder network that reduces the computational parameters and guarantees the robustness of the algorithm. Working with channel and spatial fusion attention modules, our network effectively captures multi-level RGB-D features. A globally guided local affinity context module is proposed to obtain sufficient high-level context information. The decoder utilizes a lightweight residual unit that combines short- and long-distance information with a few redundant computations. Experimental results on NYUv2, SUN RGB-D, and Cityscapes datasets show that our method achieves a better trade-off among segmentation accuracy, inference time, and parameters than the state-of-the-art methods. The source code will be at https://github.com/MVME-HBUT/SGACNet
Efficient Visual Fault Detection for Freight Train Braking System via Heterogeneous Self Distillation in the Wild
Jul 03, 2023



Efficient visual fault detection of freight trains is a critical part of ensuring the safe operation of railways under the restricted hardware environment. Although deep learning-based approaches have excelled in object detection, the efficiency of freight train fault detection is still insufficient to apply in real-world engineering. This paper proposes a heterogeneous self-distillation framework to ensure detection accuracy and speed while satisfying low resource requirements. The privileged information in the output feature knowledge can be transferred from the teacher to the student model through distillation to boost performance. We first adopt a lightweight backbone to extract features and generate a new heterogeneous knowledge neck. Such neck models positional information and long-range dependencies among channels through parallel encoding to optimize feature extraction capabilities. Then, we utilize the general distribution to obtain more credible and accurate bounding box estimates. Finally, we employ a novel loss function that makes the network easily concentrate on values near the label to improve learning efficiency. Experiments on four fault datasets reveal that our framework can achieve over 37 frames per second and maintain the highest accuracy in comparison with traditional distillation approaches. Moreover, compared to state-of-the-art methods, our framework demonstrates more competitive performance with lower memory usage and the smallest model size.