 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCovo-Audio Technical Report
Feb 10, 2026In this work, we present Covo-Audio, a 7B-parameter end-to-end LALM that directly processes continuous audio inputs and generates audio outputs within a single unified architecture. Through large-scale curated pretraining and targeted post-training, Covo-Audio achieves state-of-the-art or competitive performance among models of comparable scale across a broad spectrum of tasks, including speech-text modeling, spoken dialogue, speech understanding, audio understanding, and full-duplex voice interaction. Extensive evaluations demonstrate that the pretrained foundation model exhibits strong speech-text comprehension and semantic reasoning capabilities on multiple benchmarks, outperforming representative open-source models of comparable scale. Furthermore, Covo-Audio-Chat, the dialogue-oriented variant, demonstrates strong spoken conversational abilities, including understanding, contextual reasoning, instruction following, and generating contextually appropriate and empathetic responses, validating its applicability to real-world conversational assistant scenarios. Covo-Audio-Chat-FD, the evolved full-duplex model, achieves substantially superior performance on both spoken dialogue capabilities and full-duplex interaction behaviors, demonstrating its competence in practical robustness. To mitigate the high cost of deploying end-to-end LALMs for natural conversational systems, we propose an intelligence-speaker decoupling strategy that separates dialogue intelligence from voice rendering, enabling flexible voice customization with minimal text-to-speech (TTS) data while preserving dialogue performance. Overall, our results highlight the strong potential of 7B-scale models to integrate sophisticated audio intelligence with high-level semantic reasoning, and suggest a scalable path toward more capable and versatile LALMs.
MagiC: Evaluating Multimodal Cognition Toward Grounded Visual Reasoning
Jul 09, 2025Recent advances in large vision-language models have led to impressive performance in visual question answering and multimodal reasoning. However, it remains unclear whether these models genuinely perform grounded visual reasoning or rely on superficial patterns and dataset biases. In this work, we introduce MagiC, a comprehensive benchmark designed to evaluate grounded multimodal cognition, assessing not only answer accuracy but also the quality of step-by-step reasoning and its alignment with relevant visual evidence. Our benchmark includes approximately 5,500 weakly supervised QA examples generated from strong model outputs and 900 human-curated examples with fine-grained annotations, including answers, rationales, and bounding box groundings. We evaluate 15 vision-language models ranging from 7B to 70B parameters across four dimensions: final answer correctness, reasoning validity, grounding fidelity, and self-correction ability. MagiC further includes diagnostic settings to probe model robustness under adversarial visual cues and assess their capacity for introspective error correction. We introduce new metrics such as MagiScore and StepSense, and provide comprehensive analyses that reveal key limitations and opportunities in current approaches to grounded visual reasoning.
Probabilistic Prior Driven Attention Mechanism Based on Diffusion Model for Imaging Through Atmospheric Turbulence
Nov 15, 2024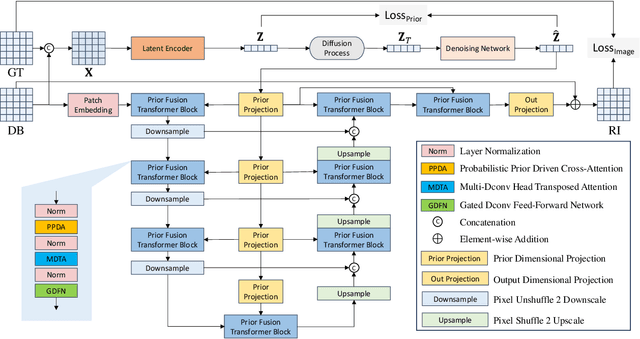
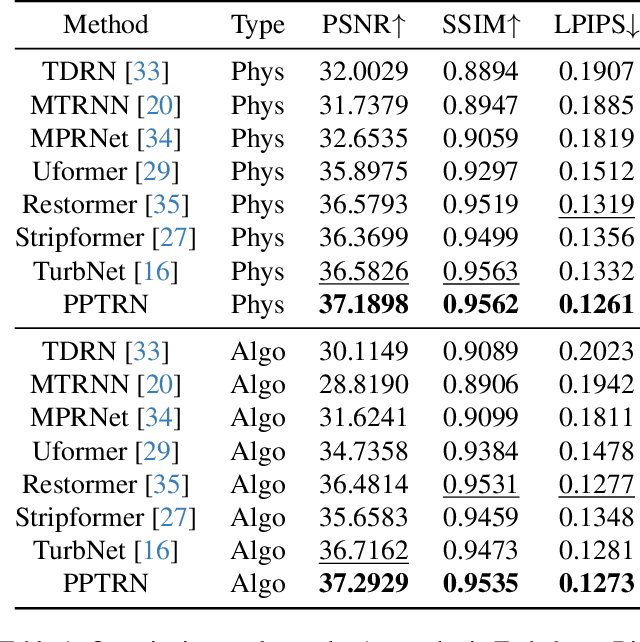
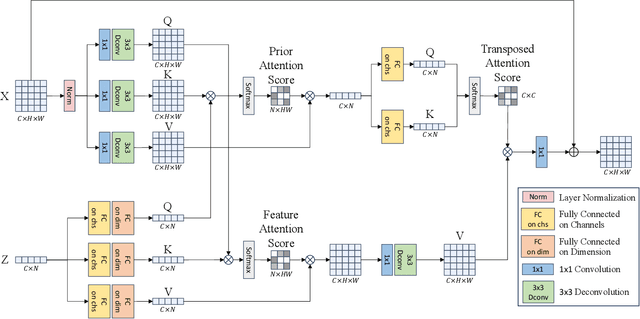

Atmospheric turbulence introduces severe spatial and geometric distortions, challenging traditional image restoration methods. We propose the Probabilistic Prior Turbulence Removal Network (PPTRN), which combines probabilistic diffusion-based prior modeling with Transformer-driven feature extraction to address this issue. PPTRN employs a two-stage approach: first, a latent encoder and Transformer are jointly trained on clear images to establish robust feature representations. Then, a Denoising Diffusion Probabilistic Model (DDPM) models prior distributions over latent vectors, guiding the Transformer in capturing diverse feature variations essential for restoration. A key innovation in PPTRN is the Probabilistic Prior Driven Cross Attention mechanism, which integrates the DDPM-generated prior with feature embeddings to reduce artifacts and enhance spatial coherence. Extensive experiments validate that PPTRN significantly improves restoration quality on turbulence-degraded images, setting a new benchmark in clarity and structural fidelity.
Slender Object Scene Segmentation in Remote Sensing Image Based on Learnable Morphological Skeleton with Segment Anything Model
Nov 13, 2024



Morphological methods play a crucial role in remote sensing image processing, due to their ability to capture and preserve small structural details. However, most of the existing deep learning models for semantic segmentation are based on the encoder-decoder architecture including U-net and Segment Anything Model (SAM), where the downsampling process tends to discard fine details. In this paper, we propose a new approach that integrates learnable morphological skeleton prior into deep neural networks using the variational method. To address the difficulty in backpropagation in neural networks caused by the non-differentiability presented in classical morphological operations, we provide a smooth representation of the morphological skeleton and design a variational segmentation model integrating morphological skeleton prior by employing operator splitting and dual methods. Then, we integrate this model into the network architecture of SAM, which is achieved by adding a token to mask decoder and modifying the final sigmoid layer, ensuring the final segmentation results preserve the skeleton structure as much as possible. Experimental results on remote sensing datasets, including buildings and roads, demonstrate that our method outperforms the original SAM on slender object segmentation and exhibits better generalization capability.
Cycle-YOLO: A Efficient and Robust Framework for Pavement Damage Detection
May 28, 2024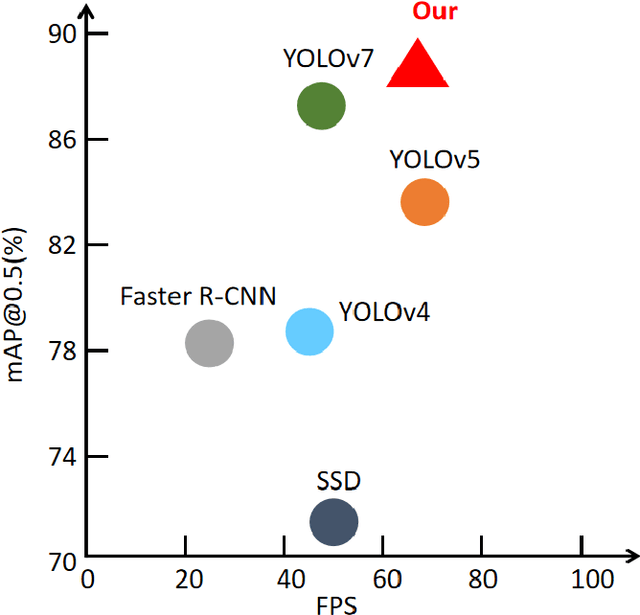
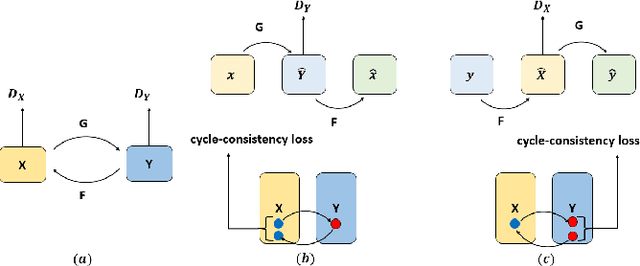

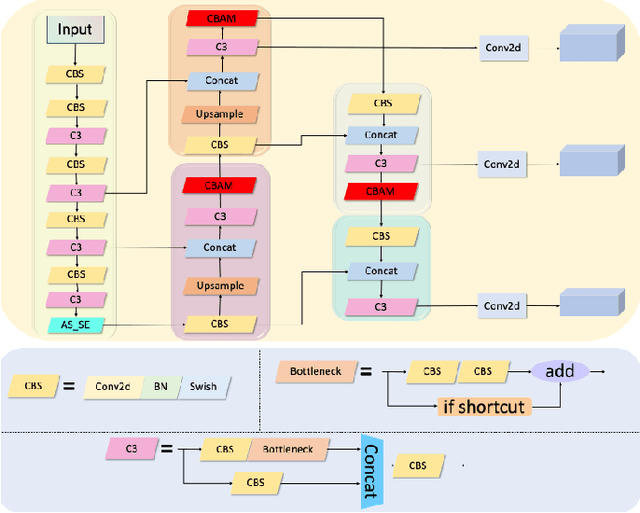
With the development of modern society, traffic volume continues to increase in most countries worldwide, leading to an increase in the rate of pavement damage Therefore, the real-time and highly accurate pavement damage detection and maintenance have become the current need. In this paper, an enhanced pavement damage detection method with CycleGAN and improved YOLOv5 algorithm is presented. We selected 7644 self-collected images of pavement damage samples as the initial dataset and augmented it by CycleGAN. Due to a substantial difference between the images generated by CycleGAN and real road images, we proposed a data enhancement method based on an improved Scharr filter, CycleGAN, and Laplacian pyramid. To improve the target recognition effect on a complex background and solve the problem that the spatial pyramid pooling-fast module in the YOLOv5 network cannot handle multiscale targets, we introduced the convolutional block attention module attention mechanism and proposed the atrous spatial pyramid pooling with squeeze-and-excitation structure. In addition, we optimized the loss function of YOLOv5 by replacing the CIoU with EIoU. The experimental results showed that our algorithm achieved a precision of 0.872, recall of 0.854, and mean average precision@0.5 of 0.882 in detecting three main types of pavement damage: cracks, potholes, and patching. On the GPU, its frames per second reached 68, meeting the requirements for real-time detection. Its overall performance even exceeded the current more advanced YOLOv7 and achieved good results in practical applications, providing a basis for decision-making in pavement damage detection and prevention.
Fine-Grained Extraction of Road Networks via Joint Learning of Connectivity and Segmentation
Dec 07, 2023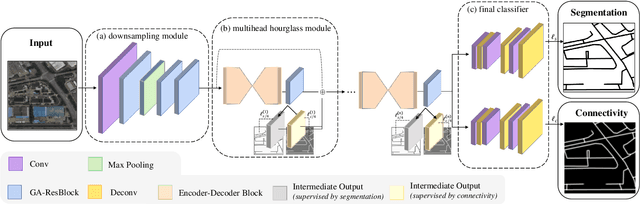

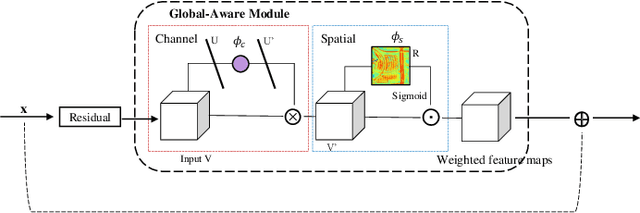
Road network extraction from satellite images is widely applicated in intelligent traffic management and autonomous driving fields. The high-resolution remote sensing images contain complex road areas and distracted background, which make it a challenge for road extraction. In this study, we present a stacked multitask network for end-to-end segmenting roads while preserving connectivity correctness. In the network, a global-aware module is introduced to enhance pixel-level road feature representation and eliminate background distraction from overhead images; a road-direction-related connectivity task is added to ensure that the network preserves the graph-level relationships of the road segments. We also develop a stacked multihead structure to jointly learn and effectively utilize the mutual information between connectivity learning and segmentation learning. We evaluate the performance of the proposed network on three public remote sensing datasets. The experimental results demonstrate that the network outperforms the state-of-the-art methods in terms of road segmentation accuracy and connectivity maintenance.
Deep Learning-based Inertial Odometry for Pedestrian Tracking using Attention Mechanism and Res2Net Module
May 20, 2022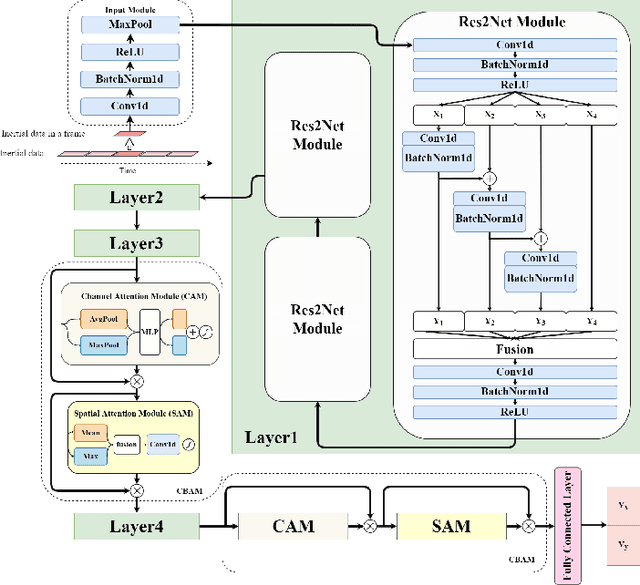
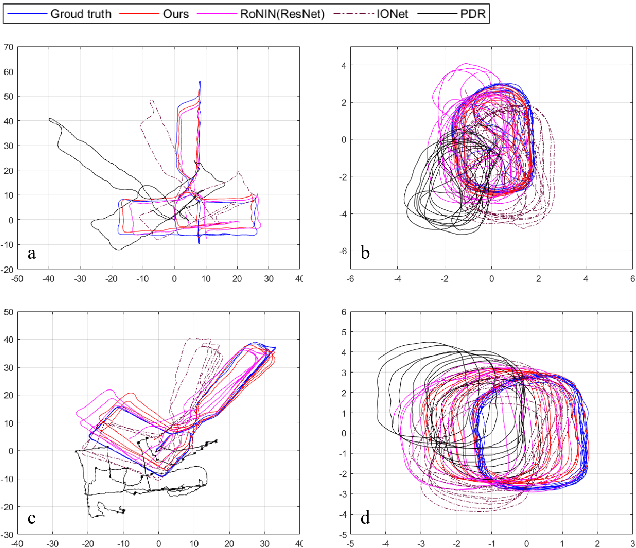
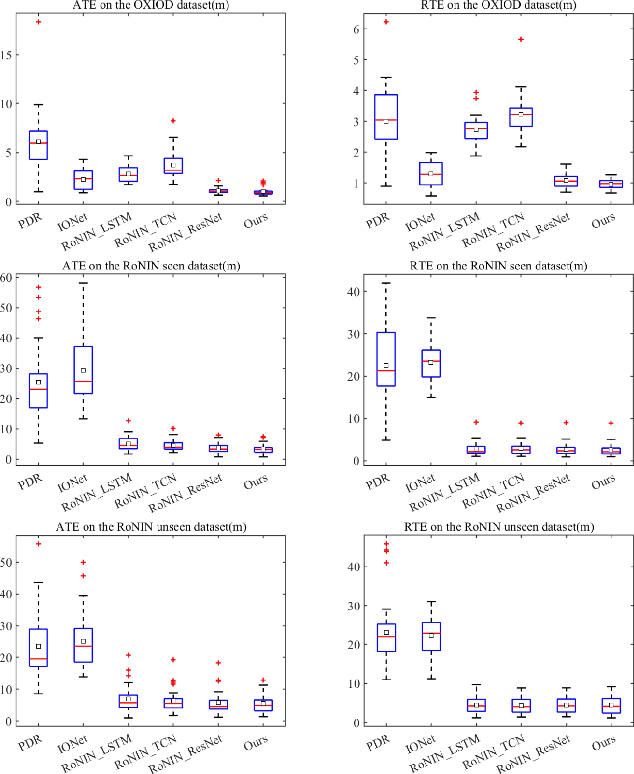
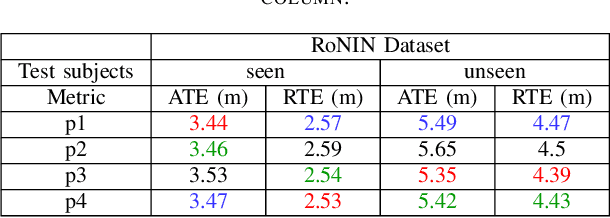
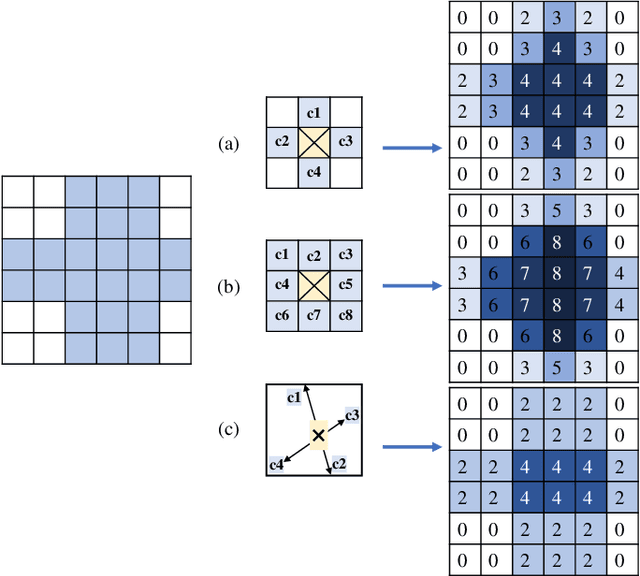
Pedestrian dead reckoning is a challenging task due to the low-cost inertial sensor error accumulation. Recent research has shown that deep learning methods can achieve impressive performance in handling this issue. In this letter, we propose inertial odometry using a deep learning-based velocity estimation method. The deep neural network based on Res2Net modules and two convolutional block attention modules is leveraged to restore the potential connection between the horizontal velocity vector and raw inertial data from a smartphone. Our network is trained using only fifty percent of the public inertial odometry dataset (RoNIN) data. Then, it is validated on the RoNIN testing dataset and another public inertial odometry dataset (OXIOD). Compared with the traditional step-length and heading system-based algorithm, our approach decreases the absolute translation error (ATE) by 76%-86%. In addition, compared with the state-of-the-art deep learning method (RoNIN), our method improves its ATE by 6%-31.4%.
Pedestrian Dead Reckoning System using Quasi-static Magnetic Field Detection
Jan 25, 2022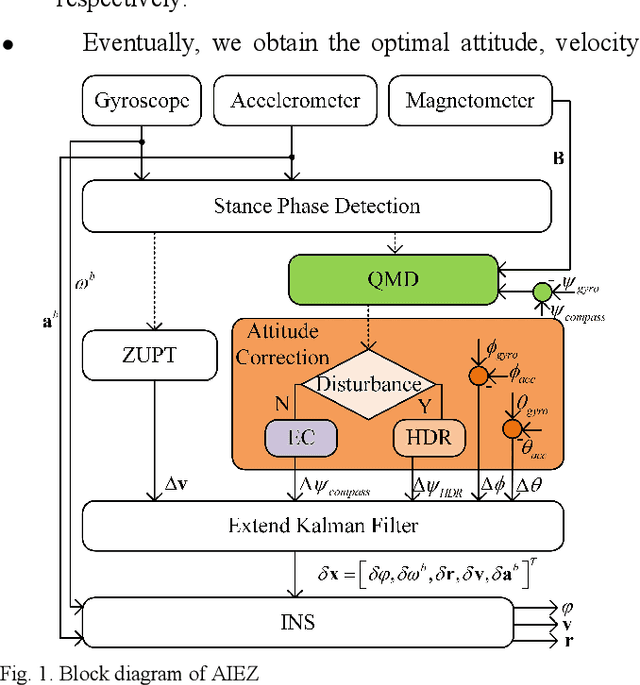
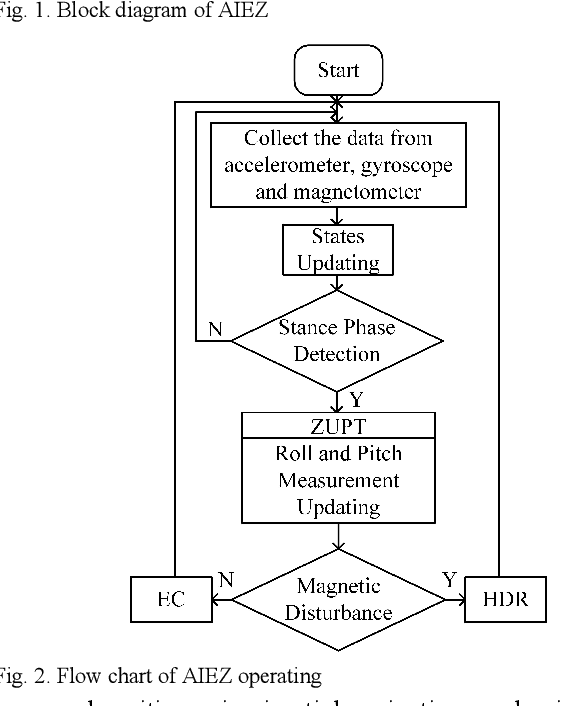
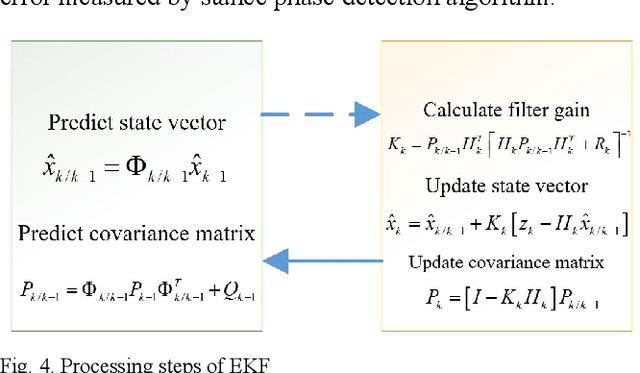

Kalman filter-based Inertial Navigation System (INS) is a reliable and efficient method to estimate the position of a pedestrian indoors. Classical INS-based methodology which is called IEZ (INS-EKF-ZUPT) makes use of an Extended Kalman Filter (EKF), a Zero velocity UPdaTing (ZUPT) to calculate the position and attitude of a person. However, heading error which is a key factor of the whole Pedestrian Dead Reckoning (PDR) system is unobservable for IEZ-based PDR system. To minimize the error, Electronic Com-pass (EC) algorithm becomes a valid method. But magnetic disturbance may have a big negative effect on it. In this paper, the Quasi-static Magnetic field Detection (QMD) method is proposed to detect the pure magnetic field and then selects EC algorithm or Heuristic heading Drift Reduction algorithm (HDR) according to the detection result, which implements the complementation of the two methods. Meanwhile, the QMD, EC, and HDR algorithms are integrated into the IEZ framework to form a new PDR solution which is named Advanced IEZ (AIEZ).
Ghost-dil-NetVLAD: A Lightweight Neural Network for Visual Place Recognition
Dec 22, 2021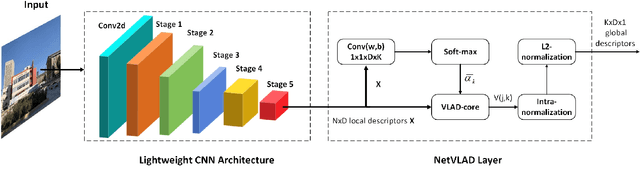
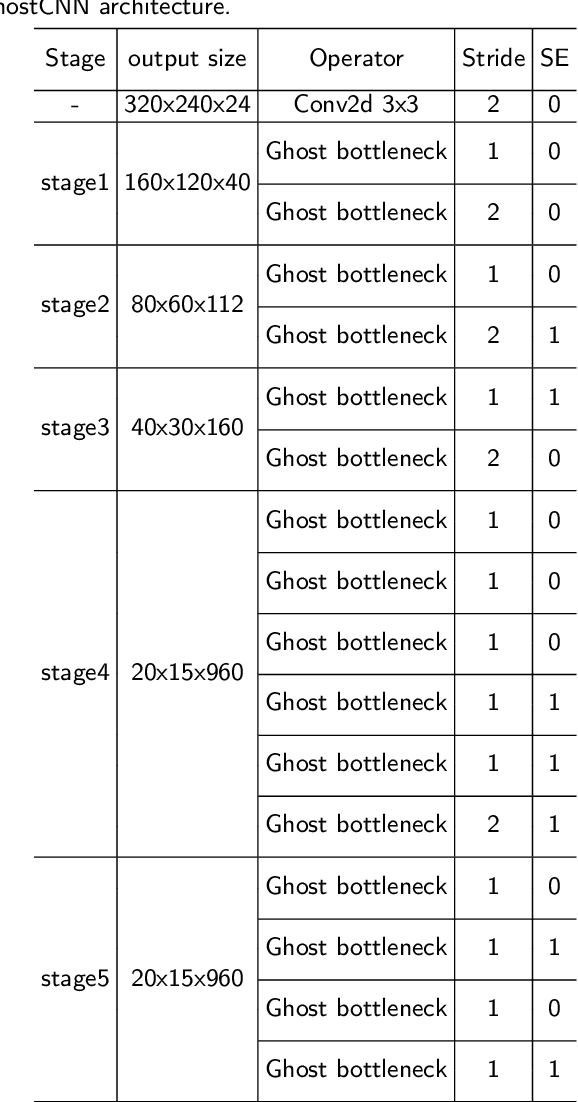
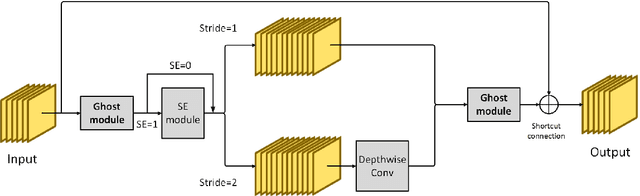
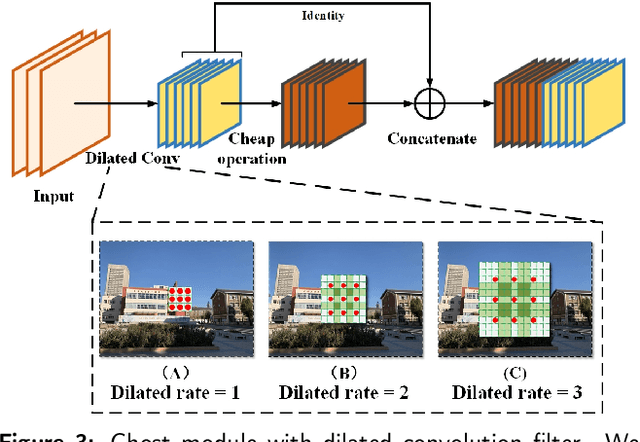
Visual place recognition (VPR) is a challenging task with the unbalance between enormous computational cost and high recognition performance. Thanks to the practical feature extraction ability of the lightweight convolution neural networks (CNNs) and the train-ability of the vector of locally aggregated descriptors (VLAD) layer, we propose a lightweight weakly supervised end-to-end neural network consisting of a front-ended perception model called GhostCNN and a learnable VLAD layer as a back-end. GhostCNN is based on Ghost modules that are lightweight CNN-based architectures. They can generate redundant feature maps using linear operations instead of the traditional convolution process, making a good trade-off between computation resources and recognition accuracy. To enhance our proposed lightweight model further, we add dilated convolutions to the Ghost module to get features containing more spatial semantic information, improving accuracy. Finally, rich experiments conducted on a commonly used public benchmark and our private dataset validate that the proposed neural network reduces the FLOPs and parameters of VGG16-NetVLAD by 99.04% and 80.16%, respectively. Besides, both models achieve similar accuracy.
DML-GANR: Deep Metric Learning With Generative Adversarial Network Regularization for High Spatial Resolution Remote Sensing Image Retrieval
Oct 07, 2020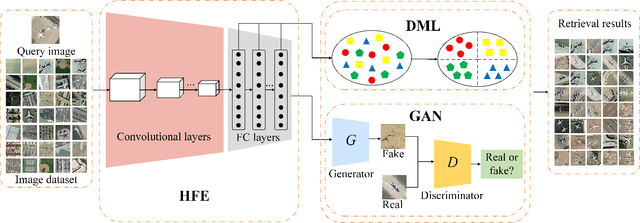


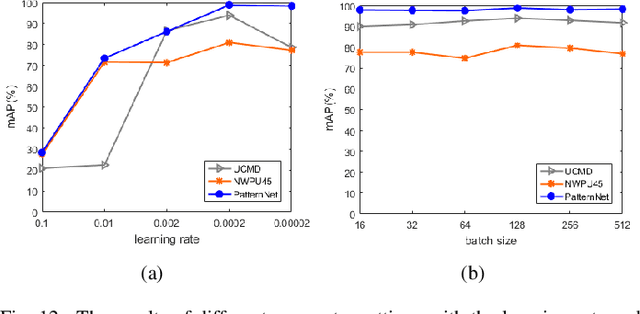
With a small number of labeled samples for training, it can save considerable manpower and material resources, especially when the amount of high spatial resolution remote sensing images (HSR-RSIs) increases considerably. However, many deep models face the problem of overfitting when using a small number of labeled samples. This might degrade HSRRSI retrieval accuracy. Aiming at obtaining more accurate HSR-RSI retrieval performance with small training samples, we develop a deep metric learning approach with generative adversarial network regularization (DML-GANR) for HSR-RSI retrieval. The DML-GANR starts from a high-level feature extraction (HFE) to extract high-level features, which includes convolutional layers and fully connected (FC) layers. Each of the FC layers is constructed by deep metric learning (DML) to maximize the interclass variations and minimize the intraclass variations. The generative adversarial network (GAN) is adopted to mitigate the overfitting problem and validate the qualities of extracted high-level features. DML-GANR is optimized through a customized approach, and the optimal parameters are obtained. The experimental results on the three data sets demonstrate the superior performance of DML-GANR over state-of-the-art techniques in HSR-RSI retrieval.