 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Extraction of Road Networks via Joint Learning of Connectivity and Segmentation
Dec 07, 2023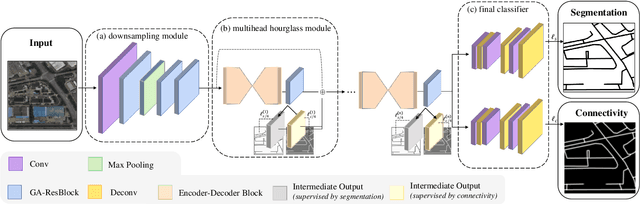

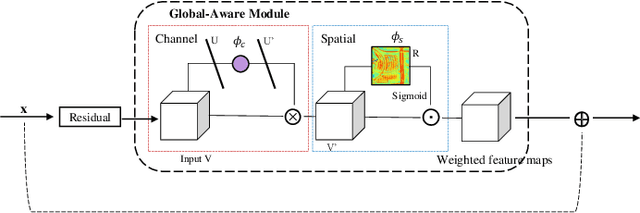
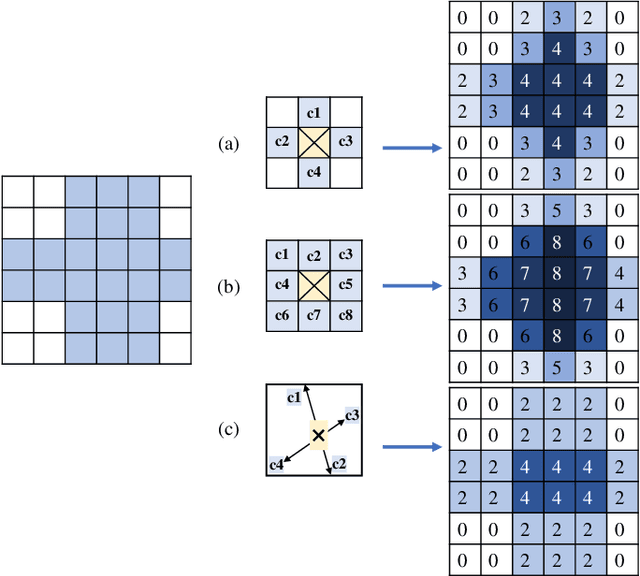
Road network extraction from satellite images is widely applicated in intelligent traffic management and autonomous driving fields. The high-resolution remote sensing images contain complex road areas and distracted background, which make it a challenge for road extraction. In this study, we present a stacked multitask network for end-to-end segmenting roads while preserving connectivity correctness. In the network, a global-aware module is introduced to enhance pixel-level road feature representation and eliminate background distraction from overhead images; a road-direction-related connectivity task is added to ensure that the network preserves the graph-level relationships of the road segments. We also develop a stacked multihead structure to jointly learn and effectively utilize the mutual information between connectivity learning and segmentation learning. We evaluate the performance of the proposed network on three public remote sensing datasets. The experimental results demonstrate that the network outperforms the state-of-the-art methods in terms of road segmentation accuracy and connectivity maintenance.
Efficient divide-and-conquer registration of UAV and ground LiDAR point clouds through canopy shape context
Jan 27, 2022
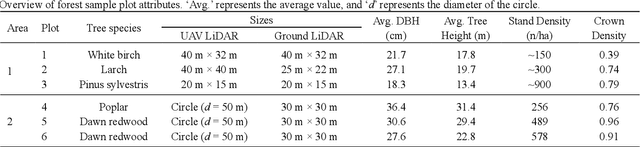
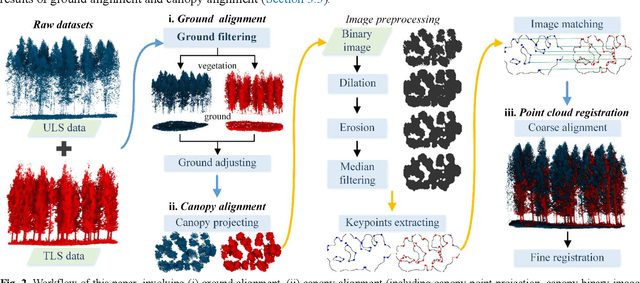
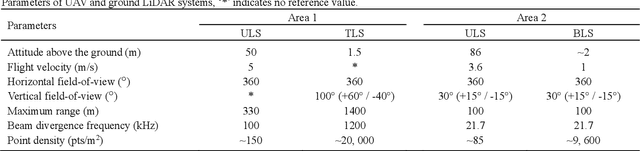
Registration of unmanned aerial vehicle laser scanning (ULS) and ground light detection and ranging (LiDAR) point clouds in forests is critical to create a detailed representation of a forest structure and an accurate inversion of forest parameters. However, forest occlusion poses challenges for marker-based registration methods, and some marker-free automated registration methods have low efficiency due to the process of object (e.g., tree, crown) segmentation. Therefore, we use a divide-and-conquer strategy and propose an automated and efficient method to register ULS and ground LiDAR point clouds in forests. Registration involves coarse alignment and fine registration, where the coarse alignment of point clouds is divided into vertical and horizontal alignment. The vertical alignment is achieved by ground alignment, which is achieved by the transformation relationship between normal vectors of the ground point cloud and the horizontal plane, and the horizontal alignment is achieved by canopy projection image matching. During image matching, vegetation points are first distinguished by the ground filtering algorithm, and then, vegetation points are projected onto the horizontal plane to obtain two binary images. To match the two images, a matching strategy is used based on canopy shape context features, which are described by a two-point congruent set and canopy overlap. Finally, we implement coarse alignment of ULS and ground LiDAR datasets by combining the results of ground alignment and image matching and finish fine registration. Also, the effectiveness, accuracy, and efficiency of the proposed method are demonstrated by field measurements of forest plots. Experimental results show that the ULS and ground LiDAR data in different plots are registered, of which the horizontal alignment errors are less than 0.02 m, and the average runtime of the proposed method is less than 1 second.
Improving Shadow Suppression for Illumination Robust Face Recognition
Oct 13, 2017
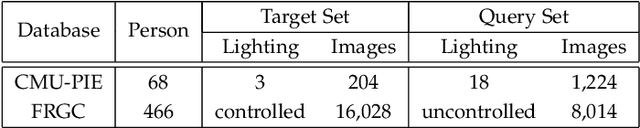
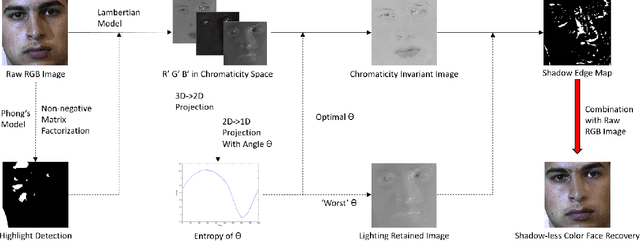
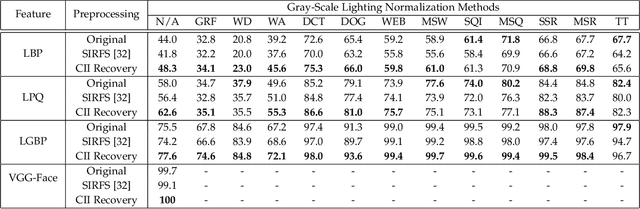
2D face analysis techniques, such as face landmarking, face recognition and face verification, are reasonably dependent on illumination conditions which are usually uncontrolled and unpredictable in the real world. An illumination robust preprocessing method thus remains a significant challenge in reliable face analysis. In this paper we propose a novel approach for improving lighting normalization through building the underlying reflectance model which characterizes interactions between skin surface, lighting source and camera sensor, and elaborates the formation of face color appearance. Specifically, the proposed illumination processing pipeline enables the generation of Chromaticity Intrinsic Image (CII) in a log chromaticity space which is robust to illumination variations. Moreover, as an advantage over most prevailing methods, a photo-realistic color face image is subsequently reconstructed which eliminates a wide variety of shadows whilst retaining the color information and identity details. Experimental results under different scenarios and using various face databases show the effectiveness of the proposed approach to deal with lighting variations, including both soft and hard shadows, in face recognition.
Improving Heterogeneous Face Recognition with Conditional Adversarial Networks
Sep 13, 2017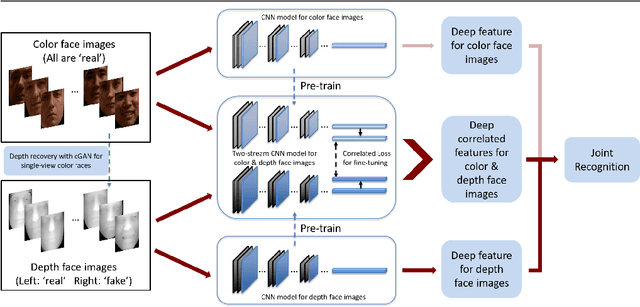

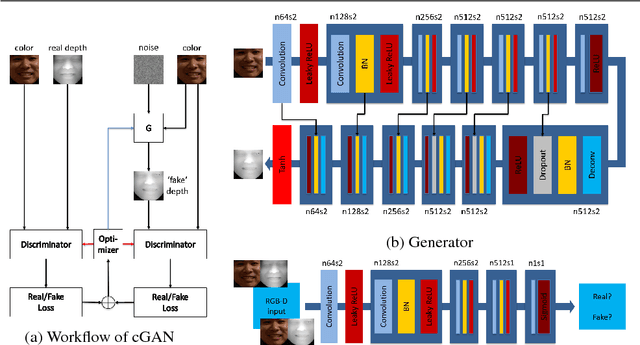
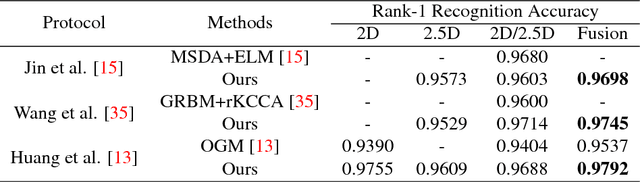
Heterogeneous face recognition between color image and depth image is a much desired capacity for real world applications where shape information is looked upon as merely involved in gallery. In this paper, we propose a cross-modal deep learning method as an effective and efficient workaround for this challenge. Specifically, we begin with learning two convolutional neural networks (CNNs) to extract 2D and 2.5D face features individually. Once trained, they can serve as pre-trained models for another two-way CNN which explores the correlated part between color and depth for heterogeneous matching. Compared with most conventional cross-modal approaches, our method additionally conducts accurate depth image reconstruction from single color image with Conditional Generative Adversarial Nets (cGAN), and further enhances the recognition performance by fusing multi-modal matching results. Through both qualitative and quantitative experiments on benchmark FRGC 2D/3D face database, we demonstrate that the proposed pipeline outperforms state-of-the-art performance on heterogeneous face recognition and ensures a drastically efficient on-line stage.