 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegMoTE: Token-Level Mixture of Experts for Medical Image Segmentation
Feb 22, 2026Medical image segmentation is vital for clinical diagnosis and quantitative analysis, yet remains challenging due to the heterogeneity of imaging modalities and the high cost of pixel-level annotations. Although general interactive segmentation models like SAM have achieved remarkable progress, their transfer to medical imaging still faces two key bottlenecks: (i) the lack of adaptive mechanisms for modality- and anatomy-specific tasks, which limits generalization in out-of-distribution medical scenarios; and (ii) current medical adaptation methods fine-tune on large, heterogeneous datasets without selection, leading to noisy supervision, higher cost, and negative transfer. To address these issues, we propose SegMoTE, an efficient and adaptive framework for medical image segmentation. SegMoTE preserves SAM's original prompt interface, efficient inference, and zero-shot generalization while introducing only a small number of learnable parameters to dynamically adapt across modalities and tasks. In addition, we design a progressive prompt tokenization mechanism that enables fully automatic segmentation, significantly reducing annotation dependence. Trained on MedSeg-HQ, a curated dataset less than 1% of existing large-scale datasets, SegMoTE achieves SOTA performance across diverse imaging modalities and anatomical tasks. It represents the first efficient, robust, and scalable adaptation of general segmentation models to the medical domain under extremely low annotation cost, advancing the practical deployment of foundation vision models in clinical applications.
Voila: Voice-Language Foundation Models for Real-Time Autonomous Interaction and Voice Role-Play
May 05, 2025A voice AI agent that blends seamlessly into daily life would interact with humans in an autonomous, real-time, and emotionally expressive manner. Rather than merely reacting to commands, it would continuously listen, reason, and respond proactively, fostering fluid, dynamic, and emotionally resonant interactions. We introduce Voila, a family of large voice-language foundation models that make a step towards this vision. Voila moves beyond traditional pipeline systems by adopting a new end-to-end architecture that enables full-duplex, low-latency conversations while preserving rich vocal nuances such as tone, rhythm, and emotion. It achieves a response latency of just 195 milliseconds, surpassing the average human response time. Its hierarchical multi-scale Transformer integrates the reasoning capabilities of large language models (LLMs) with powerful acoustic modeling, enabling natural, persona-aware voice generation -- where users can simply write text instructions to define the speaker's identity, tone, and other characteristics. Moreover, Voila supports over one million pre-built voices and efficient customization of new ones from brief audio samples as short as 10 seconds. Beyond spoken dialogue, Voila is designed as a unified model for a wide range of voice-based applications, including automatic speech recognition (ASR), Text-to-Speech (TTS), and, with minimal adaptation, multilingual speech translation. Voila is fully open-sourced to support open research and accelerate progress toward next-generation human-machine interactions.
SoFar: Language-Grounded Orientation Bridges Spatial Reasoning and Object Manipulation
Feb 18, 2025


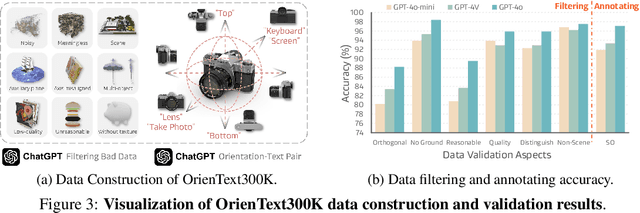
Spatial intelligence is a critical component of embodied AI, promoting robots to understand and interact with their environments. While recent advances have enhanced the ability of VLMs to perceive object locations and positional relationships, they still lack the capability to precisely understand object orientations-a key requirement for tasks involving fine-grained manipulations. Addressing this limitation not only requires geometric reasoning but also an expressive and intuitive way to represent orientation. In this context, we propose that natural language offers a more flexible representation space than canonical frames, making it particularly suitable for instruction-following robotic systems. In this paper, we introduce the concept of semantic orientation, which defines object orientations using natural language in a reference-frame-free manner (e.g., the ''plug-in'' direction of a USB or the ''handle'' direction of a knife). To support this, we construct OrienText300K, a large-scale dataset of 3D models annotated with semantic orientations that link geometric understanding to functional semantics. By integrating semantic orientation into a VLM system, we enable robots to generate manipulation actions with both positional and orientational constraints. Extensive experiments in simulation and real world demonstrate that our approach significantly enhances robotic manipulation capabilities, e.g., 48.7% accuracy on Open6DOR and 74.9% accuracy on SIMPLER.
InternLM-XComposer2.5-OmniLive: A Comprehensive Multimodal System for Long-term Streaming Video and Audio Interactions
Dec 12, 2024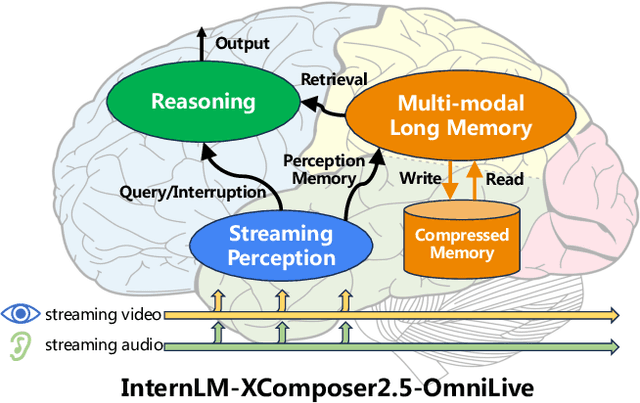
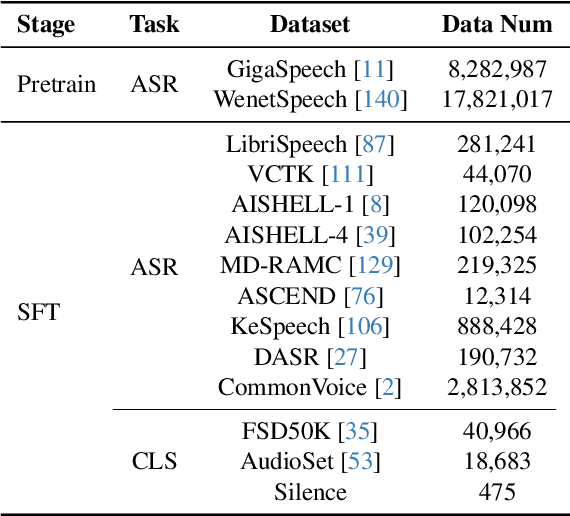
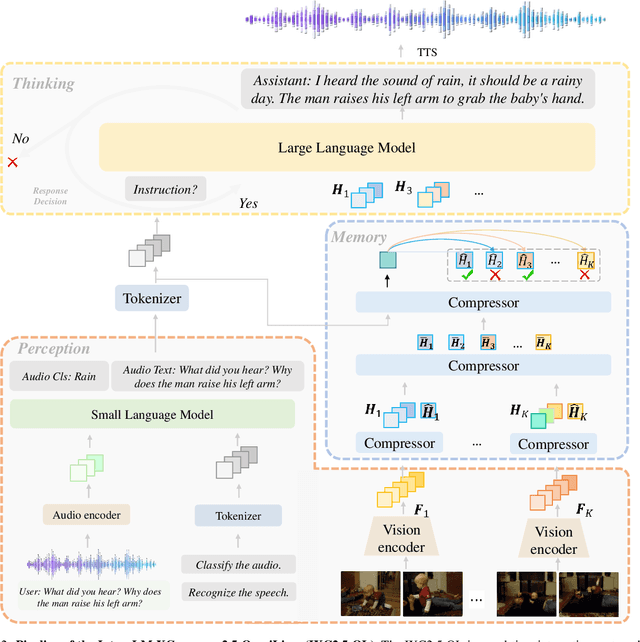

Creating AI systems that can interact with environments over long periods, similar to human cognition, has been a longstanding research goal. Recent advancements in multimodal large language models (MLLMs) have made significant strides in open-world understanding. However, the challenge of continuous and simultaneous streaming perception, memory, and reasoning remains largely unexplored. Current MLLMs are constrained by their sequence-to-sequence architecture, which limits their ability to process inputs and generate responses simultaneously, akin to being unable to think while perceiving. Furthermore, relying on long contexts to store historical data is impractical for long-term interactions, as retaining all information becomes costly and inefficient. Therefore, rather than relying on a single foundation model to perform all functions, this project draws inspiration from the concept of the Specialized Generalist AI and introduces disentangled streaming perception, reasoning, and memory mechanisms, enabling real-time interaction with streaming video and audio input. The proposed framework InternLM-XComposer2.5-OmniLive (IXC2.5-OL) consists of three key modules: (1) Streaming Perception Module: Processes multimodal information in real-time, storing key details in memory and triggering reasoning in response to user queries. (2) Multi-modal Long Memory Module: Integrates short-term and long-term memory, compressing short-term memories into long-term ones for efficient retrieval and improved accuracy. (3) Reasoning Module: Responds to queries and executes reasoning tasks, coordinating with the perception and memory modules. This project simulates human-like cognition, enabling multimodal large language models to provide continuous and adaptive service over time.
Weakly Contrastive Learning via Batch Instance Discrimination and Feature Clustering for Small Sample SAR ATR
Aug 07, 2024In recent years, impressive performance of deep learning technology has been recognized in Synthetic Aperture Radar (SAR) Automatic Target Recognition (ATR). Since a large amount of annotated data is required in this technique, it poses a trenchant challenge to the issue of obtaining a high recognition rate through less labeled data. To overcome this problem, inspired by the contrastive learning, we proposed a novel framework named Batch Instance Discrimination and Feature Clustering (BIDFC). In this framework, different from that of the objective of general contrastive learning methods, embedding distance between samples should be moderate because of the high similarity between samples in the SAR images. Consequently, our flexible framework is equipped with adjustable distance between embedding, which we term as weakly contrastive learning. Technically, instance labels are assigned to the unlabeled data in per batch and random augmentation and training are performed few times on these augmented data. Meanwhile, a novel Dynamic-Weighted Variance loss (DWV loss) function is also posed to cluster the embedding of enhanced versions for each sample. Experimental results on the moving and stationary target acquisition and recognition (MSTAR) database indicate a 91.25% classification accuracy of our method fine-tuned on only 3.13% training data. Even though a linear evaluation is performed on the same training data, the accuracy can still reach 90.13%. We also verified the effectiveness of BIDFC in OpenSarShip database, indicating that our method can be generalized to other datasets. Our code is avaliable at: https://github.com/Wenlve-Zhou/BIDFC-master.
InternLM-XComposer-2.5: A Versatile Large Vision Language Model Supporting Long-Contextual Input and Output
Jul 03, 2024



We present InternLM-XComposer-2.5 (IXC-2.5), a versatile large-vision language model that supports long-contextual input and output. IXC-2.5 excels in various text-image comprehension and composition applications, achieving GPT-4V level capabilities with merely 7B LLM backend. Trained with 24K interleaved image-text contexts, it can seamlessly extend to 96K long contexts via RoPE extrapolation. This long-context capability allows IXC-2.5 to excel in tasks requiring extensive input and output contexts. Compared to its previous 2.0 version, InternLM-XComposer-2.5 features three major upgrades in vision-language comprehension: (1) Ultra-High Resolution Understanding, (2) Fine-Grained Video Understanding, and (3) Multi-Turn Multi-Image Dialogue. In addition to comprehension, IXC-2.5 extends to two compelling applications using extra LoRA parameters for text-image composition: (1) Crafting Webpages and (2) Composing High-Quality Text-Image Articles. IXC-2.5 has been evaluated on 28 benchmarks, outperforming existing open-source state-of-the-art models on 16 benchmarks. It also surpasses or competes closely with GPT-4V and Gemini Pro on 16 key tasks. The InternLM-XComposer-2.5 is publicly available at https://github.com/InternLM/InternLM-XComposer.
InternLM-XComposer2-4KHD: A Pioneering Large Vision-Language Model Handling Resolutions from 336 Pixels to 4K HD
Apr 09, 2024



The Large Vision-Language Model (LVLM) field has seen significant advancements, yet its progression has been hindered by challenges in comprehending fine-grained visual content due to limited resolution. Recent efforts have aimed to enhance the high-resolution understanding capabilities of LVLMs, yet they remain capped at approximately 1500 x 1500 pixels and constrained to a relatively narrow resolution range. This paper represents InternLM-XComposer2-4KHD, a groundbreaking exploration into elevating LVLM resolution capabilities up to 4K HD (3840 x 1600) and beyond. Concurrently, considering the ultra-high resolution may not be necessary in all scenarios, it supports a wide range of diverse resolutions from 336 pixels to 4K standard, significantly broadening its scope of applicability. Specifically, this research advances the patch division paradigm by introducing a novel extension: dynamic resolution with automatic patch configuration. It maintains the training image aspect ratios while automatically varying patch counts and configuring layouts based on a pre-trained Vision Transformer (ViT) (336 x 336), leading to dynamic training resolution from 336 pixels to 4K standard. Our research demonstrates that scaling training resolution up to 4K HD leads to consistent performance enhancements without hitting the ceiling of potential improvements. InternLM-XComposer2-4KHD shows superb capability that matches or even surpasses GPT-4V and Gemini Pro in 10 of the 16 benchmarks. The InternLM-XComposer2-4KHD model series with 7B parameters are publicly available at https://github.com/InternLM/InternLM-XComposer.
InternLM2 Technical Report
Mar 26, 2024



The evolution of Large Language Models (LLMs) like ChatGPT and GPT-4 has sparked discussions on the advent of Artificial General Intelligence (AGI). However, replicating such advancements in open-source models has been challenging. This paper introduces InternLM2, an open-source LLM that outperforms its predecessors in comprehensive evaluations across 6 dimensions and 30 benchmarks, long-context modeling, and open-ended subjective evaluations through innovative pre-training and optimization techniques. The pre-training process of InternLM2 is meticulously detailed, highlighting the preparation of diverse data types including text, code, and long-context data. InternLM2 efficiently captures long-term dependencies, initially trained on 4k tokens before advancing to 32k tokens in pre-training and fine-tuning stages, exhibiting remarkable performance on the 200k ``Needle-in-a-Haystack" test. InternLM2 is further aligned using Supervised Fine-Tuning (SFT) and a novel Conditional Online Reinforcement Learning from Human Feedback (COOL RLHF) strategy that addresses conflicting human preferences and reward hacking. By releasing InternLM2 models in different training stages and model sizes, we provide the community with insights into the model's evolution.
InternLM-XComposer2: Mastering Free-form Text-Image Composition and Comprehension in Vision-Language Large Model
Jan 29, 2024
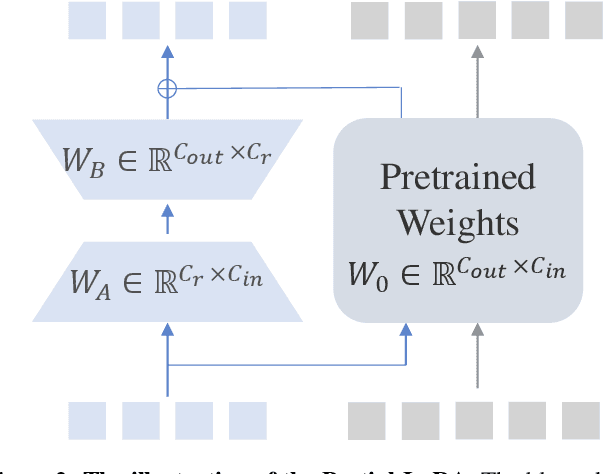

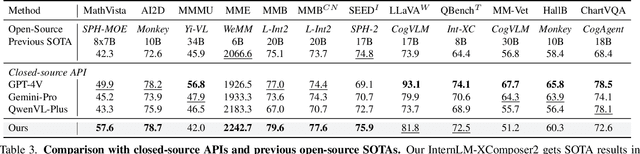
We introduce InternLM-XComposer2, a cutting-edge vision-language model excelling in free-form text-image composition and comprehension. This model goes beyond conventional vision-language understanding, adeptly crafting interleaved text-image content from diverse inputs like outlines, detailed textual specifications, and reference images, enabling highly customizable content creation. InternLM-XComposer2 proposes a Partial LoRA (PLoRA) approach that applies additional LoRA parameters exclusively to image tokens to preserve the integrity of pre-trained language knowledge, striking a balance between precise vision understanding and text composition with literary talent. Experimental results demonstrate the superiority of InternLM-XComposer2 based on InternLM2-7B in producing high-quality long-text multi-modal content and its exceptional vision-language understanding performance across various benchmarks, where it not only significantly outperforms existing multimodal models but also matches or even surpasses GPT-4V and Gemini Pro in certain assessments. This highlights its remarkable proficiency in the realm of multimodal understanding. The InternLM-XComposer2 model series with 7B parameters are publicly available at https://github.com/InternLM/InternLM-XComposer.
Fine-Grained Extraction of Road Networks via Joint Learning of Connectivity and Segmentation
Dec 07, 2023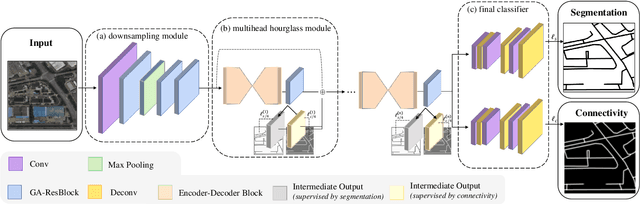

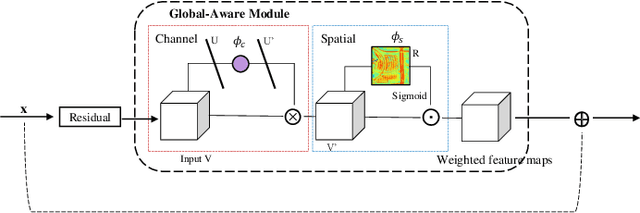
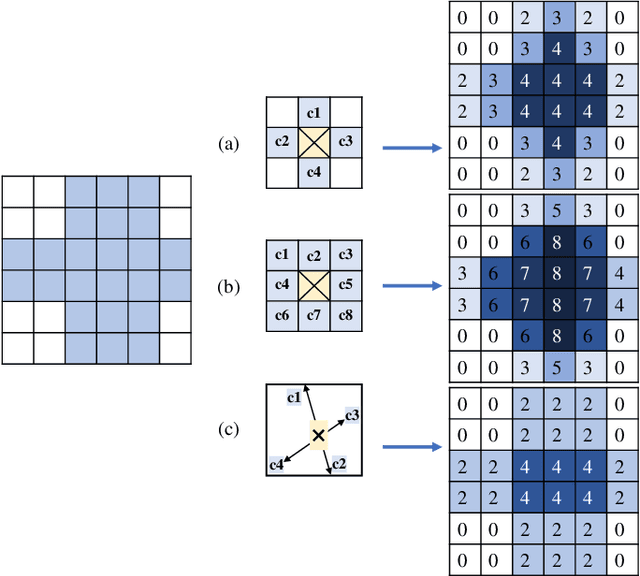
Road network extraction from satellite images is widely applicated in intelligent traffic management and autonomous driving fields. The high-resolution remote sensing images contain complex road areas and distracted background, which make it a challenge for road extraction. In this study, we present a stacked multitask network for end-to-end segmenting roads while preserving connectivity correctness. In the network, a global-aware module is introduced to enhance pixel-level road feature representation and eliminate background distraction from overhead images; a road-direction-related connectivity task is added to ensure that the network preserves the graph-level relationships of the road segments. We also develop a stacked multihead structure to jointly learn and effectively utilize the mutual information between connectivity learning and segmentation learning. We evaluate the performance of the proposed network on three public remote sensing datasets. The experimental results demonstrate that the network outperforms the state-of-the-art methods in terms of road segmentation accuracy and connectivity maintenance.