 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Contrastive Learning via Batch Instance Discrimination and Feature Clustering for Small Sample SAR ATR
Aug 07, 2024In recent years, impressive performance of deep learning technology has been recognized in Synthetic Aperture Radar (SAR) Automatic Target Recognition (ATR). Since a large amount of annotated data is required in this technique, it poses a trenchant challenge to the issue of obtaining a high recognition rate through less labeled data. To overcome this problem, inspired by the contrastive learning, we proposed a novel framework named Batch Instance Discrimination and Feature Clustering (BIDFC). In this framework, different from that of the objective of general contrastive learning methods, embedding distance between samples should be moderate because of the high similarity between samples in the SAR images. Consequently, our flexible framework is equipped with adjustable distance between embedding, which we term as weakly contrastive learning. Technically, instance labels are assigned to the unlabeled data in per batch and random augmentation and training are performed few times on these augmented data. Meanwhile, a novel Dynamic-Weighted Variance loss (DWV loss) function is also posed to cluster the embedding of enhanced versions for each sample. Experimental results on the moving and stationary target acquisition and recognition (MSTAR) database indicate a 91.25% classification accuracy of our method fine-tuned on only 3.13% training data. Even though a linear evaluation is performed on the same training data, the accuracy can still reach 90.13%. We also verified the effectiveness of BIDFC in OpenSarShip database, indicating that our method can be generalized to other datasets. Our code is avaliable at: https://github.com/Wenlve-Zhou/BIDFC-master.
Model-Agnostic Utility-Preserving Biometric Information Anonymization
May 23, 2024The recent rapid advancements in both sensing and machine learning technologies have given rise to the universal collection and utilization of people's biometrics, such as fingerprints, voices, retina/facial scans, or gait/motion/gestures data, enabling a wide range of applications including authentication, health monitoring, or much more sophisticated analytics. While providing better user experiences and deeper business insights, the use of biometrics has raised serious privacy concerns due to their intrinsic sensitive nature and the accompanying high risk of leaking sensitive information such as identity or medical conditions. In this paper, we propose a novel modality-agnostic data transformation framework that is capable of anonymizing biometric data by suppressing its sensitive attributes and retaining features relevant to downstream machine learning-based analyses that are of research and business values. We carried out a thorough experimental evaluation using publicly available facial, voice, and motion datasets. Results show that our proposed framework can achieve a \highlight{high suppression level for sensitive information}, while at the same time retain underlying data utility such that subsequent analyses on the anonymized biometric data could still be carried out to yield satisfactory accuracy.
MaSS: Multi-attribute Selective Suppression
Oct 18, 2022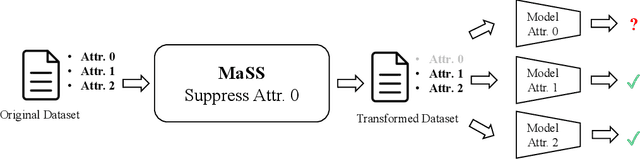

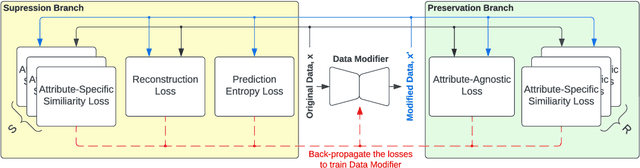
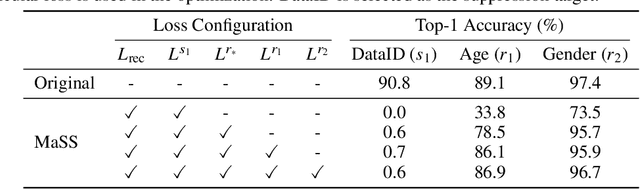
The recent rapid advances in machine learning technologies largely depend on the vast richness of data available today, in terms of both the quantity and the rich content contained within. For example, biometric data such as images and voices could reveal people's attributes like age, gender, sentiment, and origin, whereas location/motion data could be used to infer people's activity levels, transportation modes, and life habits. Along with the new services and applications enabled by such technological advances, various governmental policies are put in place to regulate such data usage and protect people's privacy and rights. As a result, data owners often opt for simple data obfuscation (e.g., blur people's faces in images) or withholding data altogether, which leads to severe data quality degradation and greatly limits the data's potential utility. Aiming for a sophisticated mechanism which gives data owners fine-grained control while retaining the maximal degree of data utility, we propose Multi-attribute Selective Suppression, or MaSS, a general framework for performing precisely targeted data surgery to simultaneously suppress any selected set of attributes while preserving the rest for downstream machine learning tasks. MaSS learns a data modifier through adversarial games between two sets of networks, where one is aimed at suppressing selected attributes, and the other ensures the retention of the rest of the attributes via general contrastive loss as well as explicit classification metrics. We carried out an extensive evaluation of our proposed method using multiple datasets from different domains including facial images, voice audio, and video clips, and obtained promising results in MaSS' generalizability and capability of suppressing targeted attributes without negatively affecting the data's usability in other downstream ML tasks.