 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndustrial3D: A Terrestrial LiDAR Point Cloud Dataset and CrossParadigm Benchmark for Industrial Infrastructure
Mar 30, 2026Automated semantic understanding of dense point clouds is a prerequisite for Scan-to-BIM pipelines, digital twin construction, and as-built verification--core tasks in the digital transformation of the construction industry. Yet for industrial mechanical, electrical, and plumbing (MEP) facilities, this challenge remains largely unsolved: TLS acquisitions of water treatment plants, chiller halls, and pumping stations exhibit extreme geometric ambiguity, severe occlusion, and extreme class imbalance that architectural benchmarks (e.g., S3DIS or ScanNet) cannot adequately represent. We present Industrial3D, a terrestrial LiDAR dataset comprising 612 million expertly labelled points at 6 mm resolution from 13 water treatment facilities. At 6.6x the scale of the closest comparable MEP dataset, Industrial3D provides the largest and most demanding testbed for industrial 3D scene understanding to date. We further establish the first industrial cross-paradigm benchmark, evaluating nine representative methods across fully supervised, weakly supervised, unsupervised, and foundation model settings under a unified benchmark protocol. The best supervised method achieves 55.74% mIoU, whereas zero-shot Point-SAM reaches only 15.79%--a 39.95 percentage-point gap that quantifies the unresolved domain-transfer challenge for industrial TLS data. Systematic analysis reveals that this gap originates from a dual crisis: statistical rarity (215:1 imbalance, 3.5x more severe than S3DIS) and geometric ambiguity (tail-class points share cylindrical primitives with head-class pipes) that frequency-based re-weighting alone cannot resolve. Industrial3D, along with benchmark code and pre-trained models, will be publicly available at https://github.com/pointcloudyc/Industrial3D.
Faithful Bi-Directional Model Steering via Distribution Matching and Distributed Interchange Interventions
Feb 05, 2026Intervention-based model steering offers a lightweight and interpretable alternative to prompting and fine-tuning. However, by adapting strong optimization objectives from fine-tuning, current methods are susceptible to overfitting and often underperform, sometimes generating unnatural outputs. We hypothesize that this is because effective steering requires the faithful identification of internal model mechanisms, not the enforcement of external preferences. To this end, we build on the principles of distributed alignment search (DAS), the standard for causal variable localization, to propose a new steering method: Concept DAS (CDAS). While we adopt the core mechanism of DAS, distributed interchange intervention (DII), we introduce a novel distribution matching objective tailored for the steering task by aligning intervened output distributions with counterfactual distributions. CDAS differs from prior work in two main ways: first, it learns interventions via weak-supervised distribution matching rather than probability maximization; second, it uses DIIs that naturally enable bi-directional steering and allow steering factors to be derived from data, reducing the effort required for hyperparameter tuning and resulting in more faithful and stable control. On AxBench, a large-scale model steering benchmark, we show that CDAS does not always outperform preference-optimization methods but may benefit more from increased model scale. In two safety-related case studies, overriding refusal behaviors of safety-aligned models and neutralizing a chain-of-thought backdoor, CDAS achieves systematic steering while maintaining general model utility. These results indicate that CDAS is complementary to preference-optimization approaches and conditionally constitutes a robust approach to intervention-based model steering. Our code is available at https://github.com/colored-dye/concept_das.
Ground What You See: Hallucination-Resistant MLLMs via Caption Feedback, Diversity-Aware Sampling, and Conflict Regularization
Jan 13, 2026While Multimodal Large Language Models (MLLMs) have achieved remarkable success across diverse tasks, their practical deployment is severely hindered by hallucination issues, which become particularly acute during Reinforcement Learning (RL) optimization. This paper systematically analyzes the root causes of hallucinations in MLLMs under RL training, identifying three critical factors: (1) an over-reliance on chained visual reasoning, where inaccurate initial descriptions or redundant information anchor subsequent inferences to incorrect premises; (2) insufficient exploration diversity during policy optimization, leading the model to generate overly confident but erroneous outputs; and (3) destructive conflicts between training samples, where Neural Tangent Kernel (NTK) similarity causes false associations and unstable parameter updates. To address these challenges, we propose a comprehensive framework comprising three core modules. First, we enhance visual localization by introducing dedicated planning and captioning stages before the reasoning phase, employing a quality-based caption reward to ensure accurate initial anchoring. Second, to improve exploration, we categorize samples based on the mean and variance of their reward distributions, prioritizing samples with high variance to focus the model on diverse and informative data. Finally, to mitigate sample interference, we regulate NTK similarity by grouping sample pairs and applying an InfoNCE loss to push overly similar pairs apart and pull dissimilar ones closer, thereby guiding gradient interactions toward a balanced range. Experimental results demonstrate that our proposed method significantly reduces hallucination rates and effectively enhances the inference accuracy of MLLMs.
RAGFort: Dual-Path Defense Against Proprietary Knowledge Base Extraction in Retrieval-Augmented Generation
Nov 13, 2025
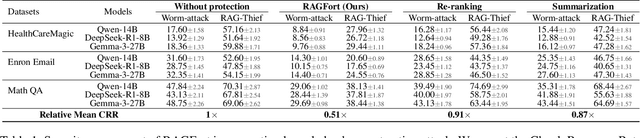
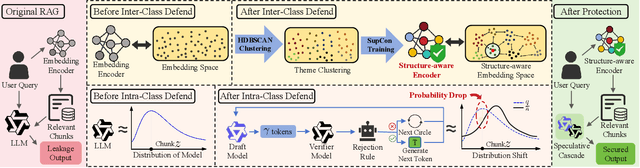
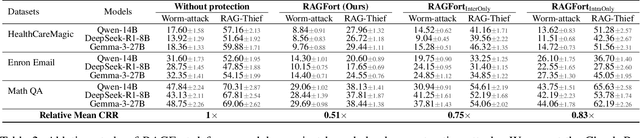
Retrieval-Augmented Generation (RAG) systems deployed over proprietary knowledge bases face growing threats from reconstruction attacks that aggregate model responses to replicate knowledge bases. Such attacks exploit both intra-class and inter-class paths, progressively extracting fine-grained knowledge within topics and diffusing it across semantically related ones, thereby enabling comprehensive extraction of the original knowledge base. However, existing defenses target only one path, leaving the other unprotected. We conduct a systematic exploration to assess the impact of protecting each path independently and find that joint protection is essential for effective defense. Based on this, we propose RAGFort, a structure-aware dual-module defense combining "contrastive reindexing" for inter-class isolation and "constrained cascade generation" for intra-class protection. Experiments across security, performance, and robustness confirm that RAGFort significantly reduces reconstruction success while preserving answer quality, offering comprehensive defense against knowledge base extraction attacks.
Democratic Training Against Universal Adversarial Perturbations
Feb 08, 2025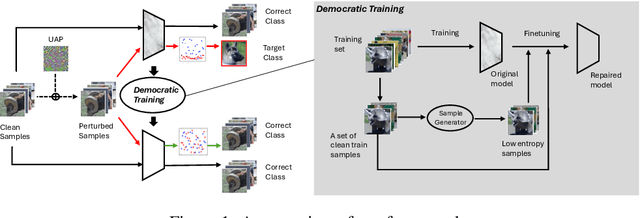
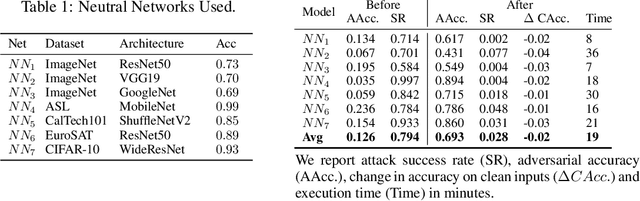

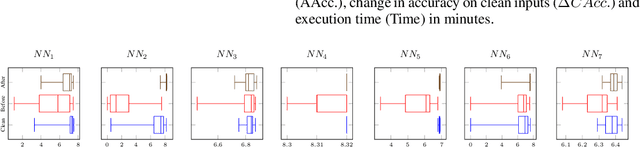
Despite their advances and success, real-world deep neural networks are known to be vulnerable to adversarial attacks. Universal adversarial perturbation, an input-agnostic attack, poses a serious threat for them to be deployed in security-sensitive systems. In this case, a single universal adversarial perturbation deceives the model on a range of clean inputs without requiring input-specific optimization, which makes it particularly threatening. In this work, we observe that universal adversarial perturbations usually lead to abnormal entropy spectrum in hidden layers, which suggests that the prediction is dominated by a small number of ``feature'' in such cases (rather than democratically by many features). Inspired by this, we propose an efficient yet effective defense method for mitigating UAPs called \emph{Democratic Training} by performing entropy-based model enhancement to suppress the effect of the universal adversarial perturbations in a given model. \emph{Democratic Training} is evaluated with 7 neural networks trained on 5 benchmark datasets and 5 types of state-of-the-art universal adversarial attack methods. The results show that it effectively reduces the attack success rate, improves model robustness and preserves the model accuracy on clean samples.
Weakly Contrastive Learning via Batch Instance Discrimination and Feature Clustering for Small Sample SAR ATR
Aug 07, 2024In recent years, impressive performance of deep learning technology has been recognized in Synthetic Aperture Radar (SAR) Automatic Target Recognition (ATR). Since a large amount of annotated data is required in this technique, it poses a trenchant challenge to the issue of obtaining a high recognition rate through less labeled data. To overcome this problem, inspired by the contrastive learning, we proposed a novel framework named Batch Instance Discrimination and Feature Clustering (BIDFC). In this framework, different from that of the objective of general contrastive learning methods, embedding distance between samples should be moderate because of the high similarity between samples in the SAR images. Consequently, our flexible framework is equipped with adjustable distance between embedding, which we term as weakly contrastive learning. Technically, instance labels are assigned to the unlabeled data in per batch and random augmentation and training are performed few times on these augmented data. Meanwhile, a novel Dynamic-Weighted Variance loss (DWV loss) function is also posed to cluster the embedding of enhanced versions for each sample. Experimental results on the moving and stationary target acquisition and recognition (MSTAR) database indicate a 91.25% classification accuracy of our method fine-tuned on only 3.13% training data. Even though a linear evaluation is performed on the same training data, the accuracy can still reach 90.13%. We also verified the effectiveness of BIDFC in OpenSarShip database, indicating that our method can be generalized to other datasets. Our code is avaliable at: https://github.com/Wenlve-Zhou/BIDFC-master.
TESTSGD: Interpretable Testing of Neural Networks Against Subtle Group Discrimination
Aug 24, 2022Discrimination has been shown in many machine learning applications, which calls for sufficient fairness testing before their deployment in ethic-relevant domains such as face recognition, medical diagnosis and criminal sentence. Existing fairness testing approaches are mostly designed for identifying individual discrimination, i.e., discrimination against individuals. Yet, as another widely concerning type of discrimination, testing against group discrimination, mostly hidden, is much less studied. To address the gap, in this work, we propose TESTSGD, an interpretable testing approach which systematically identifies and measures hidden (which we call `subtle' group discrimination} of a neural network characterized by conditions over combinations of the sensitive features. Specifically, given a neural network, TESTSGDfirst automatically generates an interpretable rule set which categorizes the input space into two groups exposing the model's group discrimination. Alongside, TESTSGDalso provides an estimated group fairness score based on sampling the input space to measure the degree of the identified subtle group discrimination, which is guaranteed to be accurate up to an error bound. We evaluate TESTSGDon multiple neural network models trained on popular datasets including both structured data and text data. The experiment results show that TESTSGDis effective and efficient in identifying and measuring such subtle group discrimination that has never been revealed before. Furthermore, we show that the testing results of TESTSGDcan guide generation of new samples to mitigate such discrimination through retraining with negligible accuracy drop.
Causality-based Neural Network Repair
Apr 20, 2022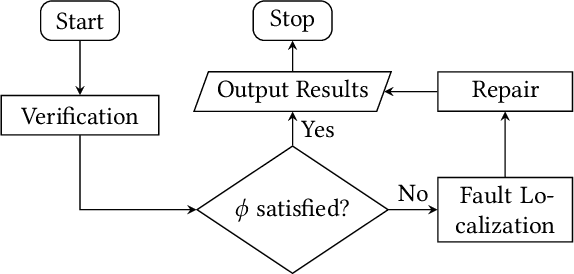
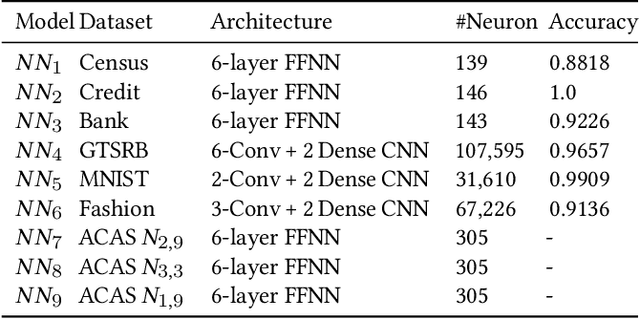
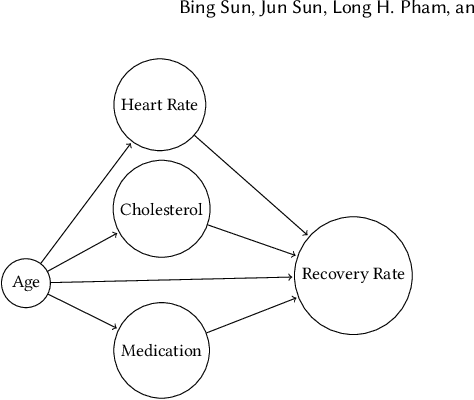
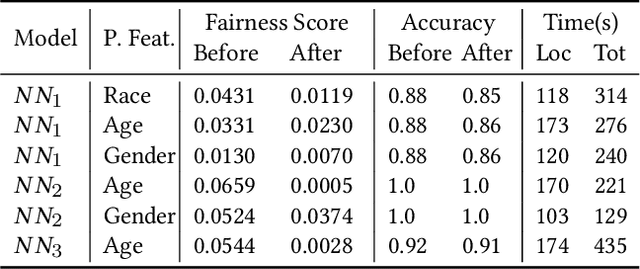
Neural networks have had discernible achievements in a wide range of applications. The wide-spread adoption also raises the concern of their dependability and reliability. Similar to traditional decision-making programs, neural networks can have defects that need to be repaired. The defects may cause unsafe behaviors, raise security concerns or unjust societal impacts. In this work, we address the problem of repairing a neural network for desirable properties such as fairness and the absence of backdoor. The goal is to construct a neural network that satisfies the property by (minimally) adjusting the given neural network's parameters (i.e., weights). Specifically, we propose CARE (\textbf{CA}usality-based \textbf{RE}pair), a causality-based neural network repair technique that 1) performs causality-based fault localization to identify the `guilty' neurons and 2) optimizes the parameters of the identified neurons to reduce the misbehavior. We have empirically evaluated CARE on various tasks such as backdoor removal, neural network repair for fairness and safety properties. Our experiment results show that CARE is able to repair all neural networks efficiently and effectively. For fairness repair tasks, CARE successfully improves fairness by $61.91\%$ on average. For backdoor removal tasks, CARE reduces the attack success rate from over $98\%$ to less than $1\%$. For safety property repair tasks, CARE reduces the property violation rate to less than $1\%$. Results also show that thanks to the causality-based fault localization, CARE's repair focuses on the misbehavior and preserves the accuracy of the neural networks.
Improved Neural Distinguishers with (Related-key) Differentials: Applications in SIMON and SIMECK
Jan 11, 2022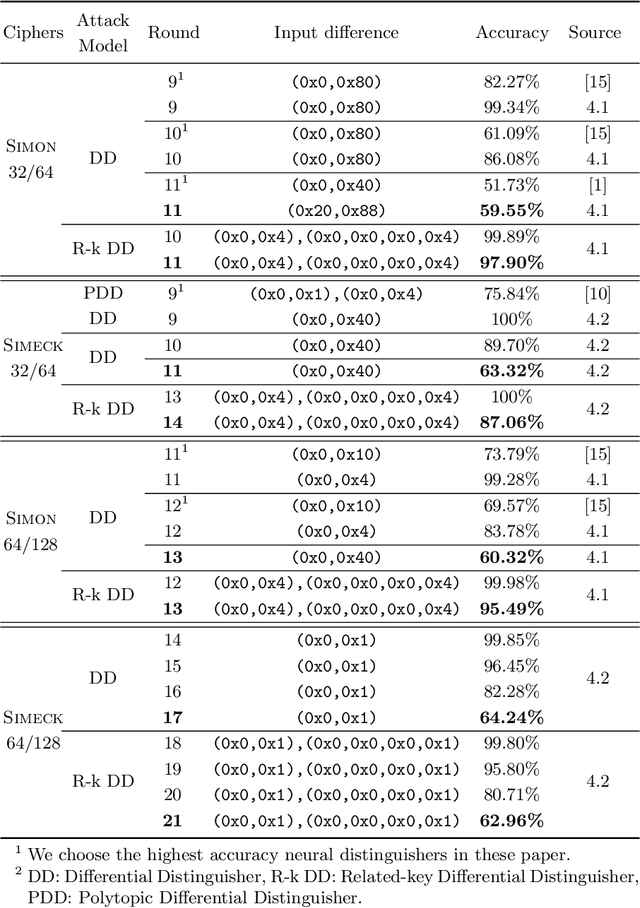
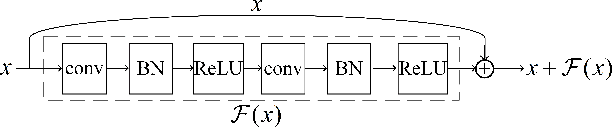

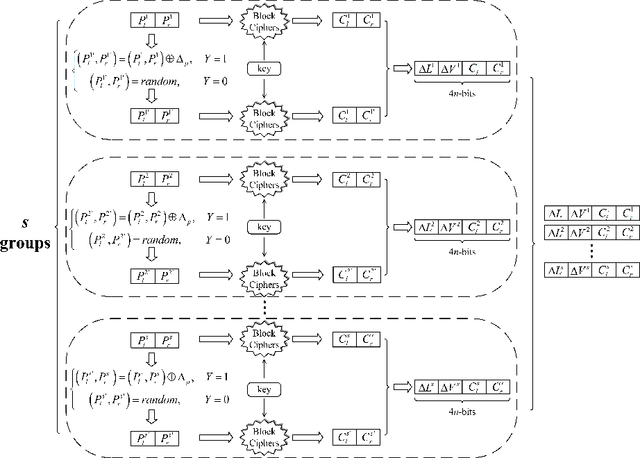
In CRYPTO 2019, Gohr made a pioneering attempt, and successfully applied deep learning to the differential cryptanalysis against NSA block cipher Speck32/64, achieving higher accuracy than the pure differential distinguishers. By its very nature, mining effective features in data plays a crucial role in data-driven deep learning. In this paper, in addition to considering the integrity of the information from the training data of the ciphertext pair, domain knowledge about the structure of differential cryptanalysis is also considered into the training process of deep learning to improve the performance. Besides, based on the SAT/SMT solvers, we find other high probability compatible differential characteristics which effectively improve the performance compared with previous work. We build neural distinguishers (NDs) and related-key neural distinguishers (RKNDs) against Simon and Simeck. The ND and RKND for Simon32/64 reach 11-, 11-round with an accuracy of 59.55% and 97.90%, respectively. For Simon64/128, the ND achieve an accuracy of 60.32% in 13-round, while it is 95.49% for the RKND. For Simeck32/64, ND and RKND of 11-, 14-round are obtained, reaching an accuracy of 63.32% and 87.06%, respectively. And we build 17-round ND and 21-round RKND for Simeck64/128 with an accuracy of 64.24% and 62.96%, respectively. Currently, these are the longest (related-key) neural distinguishers with higher accuracy for Simon32/64, Simon64/128, Simeck32/64 and Simeck64/128.
Probabilistic Verification of Neural Networks Against Group Fairness
Jul 18, 2021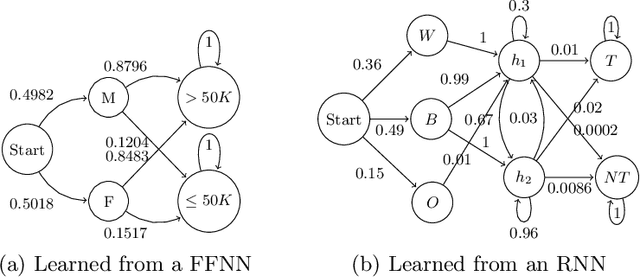
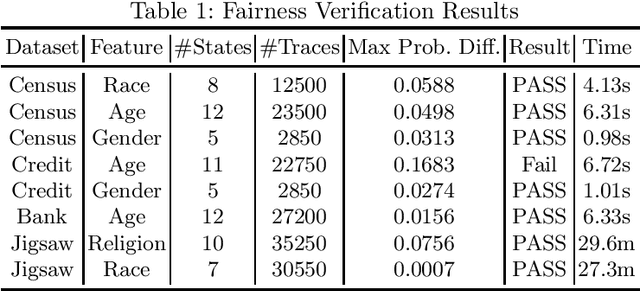

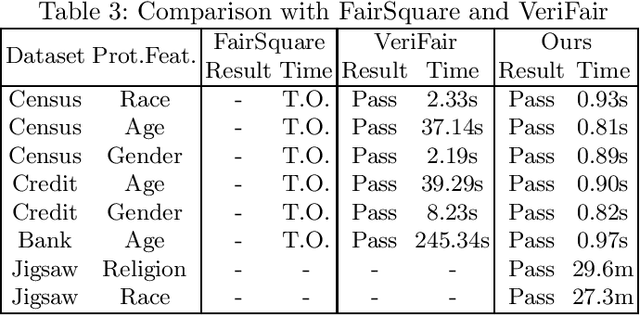
Fairness is crucial for neural networks which are used in applications with important societal implication. Recently, there have been multiple attempts on improving fairness of neural networks, with a focus on fairness testing (e.g., generating individual discriminatory instances) and fairness training (e.g., enhancing fairness through augmented training). In this work, we propose an approach to formally verify neural networks against fairness, with a focus on independence-based fairness such as group fairness. Our method is built upon an approach for learning Markov Chains from a user-provided neural network (i.e., a feed-forward neural network or a recurrent neural network) which is guaranteed to facilitate sound analysis. The learned Markov Chain not only allows us to verify (with Probably Approximate Correctness guarantee) whether the neural network is fair or not, but also facilities sensitivity analysis which helps to understand why fairness is violated. We demonstrate that with our analysis results, the neural weights can be optimized to improve fairness. Our approach has been evaluated with multiple models trained on benchmark datasets and the experiment results show that our approach is effective and efficient.