 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysDrift: Bridging the Embodiment Gap in Humanoid Co-Speech Motion Generation
Jun 18, 2026Humanoid robots require co-speech motions that are not only expressive and speech-aligned, but also physically executable under embodiment constraints. Existing co-speech generation pipelines are predominantly human-centric: motions are first generated in human-body representations such as SMPL-X and subsequently retargeted to humanoid robots. In this work, we identify a fundamental embodiment gap in this paradigm, where the mismatch between human motion manifolds and humanoid embodiment constraints disrupts embodiment consistency during motion transfer and physical execution. Through extensive analysis, we show that although retargeting can preserve coarse motion semantics, it significantly compresses motion diversity and weakens prosody-motion synchronization, limiting expressive humanoid behaviors. To address this problem, we first propose IK-EER, a prosody-preserving humanoid motion curation framework that jointly optimizes kinematic feasibility and speech-motion temporal alignment during retargeting. Building upon the curated robot-native motion dataset, we further introduce PhysDrift, an embodiment-aware co-speech motion generation framework that directly predicts executable humanoid joint trajectories from speech without relying on intermediate human-body representations. Unlike conventional human-centric pipelines, PhysDrift maintains embodiment consistency throughout both training and inference while incorporating physical regularization to stabilize robot motion dynamics. Extensive experiments and real-world humanoid deployment demonstrate that embodiment-aware robot-native generation substantially improves speech-motion alignment, physical plausibility, motion smoothness, inference efficiency, and real-time interaction capability.
Dexterity-BEV: Aligning 3D World and Actions for Generalizable Robot Policies Learning
Jun 01, 2026End-to-end manipulation policies, combined with web-scale pretrained Vision-Language Models (VLMs), show the promise for generalizable and dexterous robotic manipulation. However, they inherit two key limitations from 2D foundation models: 1) the reliance on 2D RGB inputs that ignores the intrinsically 3D nature of manipulation; and 2) the lack of spatial 3D alignment between input-output spaces as well as across diverse robot embodiments, camera setups, and trajectory datasets. In this paper, we present a series of contributions to address these issues. First, we introduce aligned vertex map and vertex spectrum -- a pixel-wise 3D representation that elevates 2D visual inputs to 3D, using camera calibration and optional depth. This novel input representation marries 3D awareness with the generalization of 2D large VLMs. Then, we propose to align the inputs and outputs of manipulation policies by expressing per-pixel 3D information of each camera view and robot actions to a shared coordinate. Based on this, we designate a canonical Bird's-Eye-View (BEV) alignment frame and innovatively propose to construct BEV images, producing a view-invariant representation robust to camera pose variations. To enable training and evaluation at scale, we develop a comprehensive data processing pipeline to perform such alignments; we also introduce a novel temporal alignment scheme for trajectories across diverse robots, human operators, and datasets. These contributions collectively mitigate input and output spatial-temporal misalignments, improving the consistency and generalization for real-world manipulation. Pretrained checkpoint, source code and data processing pipeline are available in https://hnuzhy.github.io/projects/Dex-BEV.
Pano360: Perspective to Panoramic Vision with Geometric Consistency
Mar 12, 2026Prior panorama stitching approaches heavily rely on pairwise feature correspondences and are unable to leverage geometric consistency across multiple views. This leads to severe distortion and misalignment, especially in challenging scenes with weak textures, large parallax, and repetitive patterns. Given that multi-view geometric correspondences can be directly constructed in 3D space, making them more accurate and globally consistent, we extend the 2D alignment task to the 3D photogrammetric space. We adopt a novel transformer-based architecture to achieve 3D awareness and aggregate global information across all views. It directly utilizes camera poses to guide image warping for global alignment in 3D space and employs a multi-feature joint optimization strategy to compute the seams. Additionally, to establish an evaluation benchmark and train our network, we constructed a large-scale dataset of real-world scenes. Extensive experiments show that our method significantly outperforms existing alternatives in alignment accuracy and perceptual quality.
Consistency-Regularized GAN for Few-Shot SAR Target Recognition
Jan 22, 2026Few-shot recognition in synthetic aperture radar (SAR) imagery remains a critical bottleneck for real-world applications due to extreme data scarcity. A promising strategy involves synthesizing a large dataset with a generative adversarial network (GAN), pre-training a model via self-supervised learning (SSL), and then fine-tuning on the few labeled samples. However, this approach faces a fundamental paradox: conventional GANs themselves require abundant data for stable training, contradicting the premise of few-shot learning. To resolve this, we propose the consistency-regularized generative adversarial network (Cr-GAN), a novel framework designed to synthesize diverse, high-fidelity samples even when trained under these severe data limitations. Cr-GAN introduces a dual-branch discriminator that decouples adversarial training from representation learning. This architecture enables a channel-wise feature interpolation strategy to create novel latent features, complemented by a dual-domain cycle consistency mechanism that ensures semantic integrity. Our Cr-GAN framework is adaptable to various GAN architectures, and its synthesized data effectively boosts multiple SSL algorithms. Extensive experiments on the MSTAR and SRSDD datasets validate our approach, with Cr-GAN achieving a highly competitive accuracy of 71.21% and 51.64%, respectively, in the 8-shot setting, significantly outperforming leading baselines, while requiring only ~5 of the parameters of state-of-the-art diffusion models. Code is available at: https://github.com/yikuizhai/Cr-GAN.
Beyond Weight Adaptation: Feature-Space Domain Injection for Cross-Modal Ship Re-Identification
Dec 24, 2025

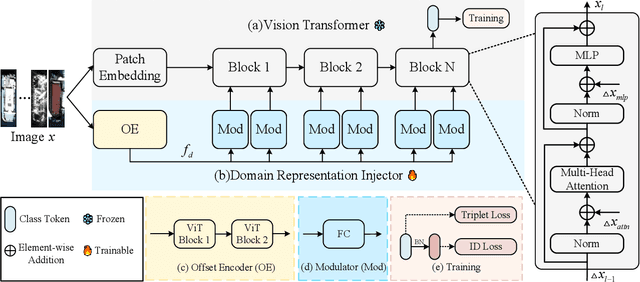

Cross-Modality Ship Re-Identification (CMS Re-ID) is critical for achieving all-day and all-weather maritime target tracking, yet it is fundamentally challenged by significant modality discrepancies. Mainstream solutions typically rely on explicit modality alignment strategies; however, this paradigm heavily depends on constructing large-scale paired datasets for pre-training. To address this, grounded in the Platonic Representation Hypothesis, we explore the potential of Vision Foundation Models (VFMs) in bridging modality gaps. Recognizing the suboptimal performance of existing generic Parameter-Efficient Fine-Tuning (PEFT) methods that operate within the weight space, particularly on limited-capacity models, we shift the optimization perspective to the feature space and propose a novel PEFT strategy termed Domain Representation Injection (DRI). Specifically, while keeping the VFM fully frozen to maximize the preservation of general knowledge, we design a lightweight, learnable Offset Encoder to extract domain-specific representations rich in modality and identity attributes from raw inputs. Guided by the contextual information of intermediate features at different layers, a Modulator adaptively transforms these representations. Subsequently, they are injected into the intermediate layers via additive fusion, dynamically reshaping the feature distribution to adapt to the downstream task without altering the VFM's pre-trained weights. Extensive experimental results demonstrate the superiority of our method, achieving State-of-the-Art (SOTA) performance with minimal trainable parameters. For instance, on the HOSS-ReID dataset, we attain 57.9\% and 60.5\% mAP using only 1.54M and 7.05M parameters, respectively. The code is available at https://github.com/TingfengXian/DRI.
Multimodal Feature Fusion Network with Text Difference Enhancement for Remote Sensing Change Detection
Sep 04, 2025Although deep learning has advanced remote sensing change detection (RSCD), most methods rely solely on image modality, limiting feature representation, change pattern modeling, and generalization especially under illumination and noise disturbances. To address this, we propose MMChange, a multimodal RSCD method that combines image and text modalities to enhance accuracy and robustness. An Image Feature Refinement (IFR) module is introduced to highlight key regions and suppress environmental noise. To overcome the semantic limitations of image features, we employ a vision language model (VLM) to generate semantic descriptions of bitemporal images. A Textual Difference Enhancement (TDE) module then captures fine grained semantic shifts, guiding the model toward meaningful changes. To bridge the heterogeneity between modalities, we design an Image Text Feature Fusion (ITFF) module that enables deep cross modal integration. Extensive experiments on LEVIRCD, WHUCD, and SYSUCD demonstrate that MMChange consistently surpasses state of the art methods across multiple metrics, validating its effectiveness for multimodal RSCD. Code is available at: https://github.com/yikuizhai/MMChange.
BiPC: Bidirectional Probability Calibration for Unsupervised Domain Adaption
Sep 29, 2024Unsupervised Domain Adaptation (UDA) leverages a labeled source domain to solve tasks in an unlabeled target domain. While Transformer-based methods have shown promise in UDA, their application is limited to plain Transformers, excluding Convolutional Neural Networks (CNNs) and hierarchical Transformers. To address this issues, we propose Bidirectional Probability Calibration (BiPC) from a probability space perspective. We demonstrate that the probability outputs from a pre-trained head, after extensive pre-training, are robust against domain gaps and can adjust the probability distribution of the task head. Moreover, the task head can enhance the pre-trained head during adaptation training, improving model performance through bidirectional complementation. Technically, we introduce Calibrated Probability Alignment (CPA) to adjust the pre-trained head's probabilities, such as those from an ImageNet-1k pre-trained classifier. Additionally, we design a Calibrated Gini Impurity (CGI) loss to refine the task head, with calibrated coefficients learned from the pre-trained classifier. BiPC is a simple yet effective method applicable to various networks, including CNNs and Transformers. Experimental results demonstrate its remarkable performance across multiple UDA tasks. Our code will be available at: https://github.com/Wenlve-Zhou/BiPC.
Weakly Contrastive Learning via Batch Instance Discrimination and Feature Clustering for Small Sample SAR ATR
Aug 07, 2024In recent years, impressive performance of deep learning technology has been recognized in Synthetic Aperture Radar (SAR) Automatic Target Recognition (ATR). Since a large amount of annotated data is required in this technique, it poses a trenchant challenge to the issue of obtaining a high recognition rate through less labeled data. To overcome this problem, inspired by the contrastive learning, we proposed a novel framework named Batch Instance Discrimination and Feature Clustering (BIDFC). In this framework, different from that of the objective of general contrastive learning methods, embedding distance between samples should be moderate because of the high similarity between samples in the SAR images. Consequently, our flexible framework is equipped with adjustable distance between embedding, which we term as weakly contrastive learning. Technically, instance labels are assigned to the unlabeled data in per batch and random augmentation and training are performed few times on these augmented data. Meanwhile, a novel Dynamic-Weighted Variance loss (DWV loss) function is also posed to cluster the embedding of enhanced versions for each sample. Experimental results on the moving and stationary target acquisition and recognition (MSTAR) database indicate a 91.25% classification accuracy of our method fine-tuned on only 3.13% training data. Even though a linear evaluation is performed on the same training data, the accuracy can still reach 90.13%. We also verified the effectiveness of BIDFC in OpenSarShip database, indicating that our method can be generalized to other datasets. Our code is avaliable at: https://github.com/Wenlve-Zhou/BIDFC-master.
Unsupervised Domain Adaption Harnessing Vision-Language Pre-training
Aug 05, 2024



This paper addresses two vital challenges in Unsupervised Domain Adaptation (UDA) with a focus on harnessing the power of Vision-Language Pre-training (VLP) models. Firstly, UDA has primarily relied on ImageNet pre-trained models. However, the potential of VLP models in UDA remains largely unexplored. The rich representation of VLP models holds significant promise for enhancing UDA tasks. To address this, we propose a novel method called Cross-Modal Knowledge Distillation (CMKD), leveraging VLP models as teacher models to guide the learning process in the target domain, resulting in state-of-the-art performance. Secondly, current UDA paradigms involve training separate models for each task, leading to significant storage overhead and impractical model deployment as the number of transfer tasks grows. To overcome this challenge, we introduce Residual Sparse Training (RST) exploiting the benefits conferred by VLP's extensive pre-training, a technique that requires minimal adjustment (approximately 0.1\%$\sim$0.5\%) of VLP model parameters to achieve performance comparable to fine-tuning. Combining CMKD and RST, we present a comprehensive solution that effectively leverages VLP models for UDA tasks while reducing storage overhead for model deployment. Furthermore, CMKD can serve as a baseline in conjunction with other methods like FixMatch, enhancing the performance of UDA. Our proposed method outperforms existing techniques on standard benchmarks. Our code will be available at: https://github.com/Wenlve-Zhou/VLP-UDA.
Improve Cross-domain Mixed Sampling with Guidance Training for Adaptive Segmentation
Mar 22, 2024Unsupervised Domain Adaptation (UDA) endeavors to adjust models trained on a source domain to perform well on a target domain without requiring additional annotations. In the context of domain adaptive semantic segmentation, which tackles UDA for dense prediction, the goal is to circumvent the need for costly pixel-level annotations. Typically, various prevailing methods baseline rely on constructing intermediate domains via cross-domain mixed sampling techniques to mitigate the performance decline caused by domain gaps. However, such approaches generate synthetic data that diverge from real-world distributions, potentially leading the model astray from the true target distribution. To address this challenge, we propose a novel auxiliary task called Guidance Training. This task facilitates the effective utilization of cross-domain mixed sampling techniques while mitigating distribution shifts from the real world. Specifically, Guidance Training guides the model to extract and reconstruct the target-domain feature distribution from mixed data, followed by decoding the reconstructed target-domain features to make pseudo-label predictions. Importantly, integrating Guidance Training incurs minimal training overhead and imposes no additional inference burden. We demonstrate the efficacy of our approach by integrating it with existing methods, consistently improving performance. The implementation will be available at https://github.com/Wenlve-Zhou/Guidance-Training.