 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbstainGNN: Teaching Graph Neural Networks to Abstain for Graph Classification
May 29, 2026Graph classification is a core task in graph data mining with widespread real-world applications. Recent advances in graph neural networks (GNNs) have led to substantial performance improvements for graph classification. However, existing GNNs are typically forced to make predictions even under high uncertainty or unknown conditions, resulting in unreliable decisions that can severely impact downstream tasks, particularly in safety-critical scenarios. To address this critical limitation, we propose AbstainGNN, a novel and theory-driven framework for graph classification with abstention, which enables GNNs to reject uncertain predictions instead of producing incorrect decisions. Specifically, AbstainGNN explicitly models both the predictive function and the abstention function, allowing for effective utilization of graph structural information. Moreover, unlike existing heuristic abstention methods, we theoretically characterize the trade-off between classification errors and rejection costs from a PAC-Bayesian generalization perspective, and derive a unified learning objective for model optimization. Guided by this theoretical insight, we further develop an efficient two-stage training strategy consisting of predictive function warm-start and abstention function calibration. Extensive experiments on five benchmark datasets show that AbstainGNN outperforms existing abstention methods, achieving superior classification performance under the same rejection rates.
Hypergraph Neural Diffusion: A PDE-Inspired Framework for Hypergraph Message Passing
Apr 13, 2026Hypergraph neural networks (HGNNs) have shown remarkable potential in modeling high-order relationships that naturally arise in many real-world data domains. However, existing HGNNs often suffer from shallow propagation, oversmoothing, and limited adaptability to complex hypergraph structures. In this paper, we propose Hypergraph Neural Diffusion (HND), a novel framework that unifies nonlinear diffusion equations with neural message passing on hypergraphs. HND is grounded in a continuous-time hypergraph diffusion equation, formulated via hypergraph gradient and divergence operators, and modulated by a learnable, structure-aware coefficient matrix over hyperedge-node pairs. This partial differential equation (PDE) based formulation provides a physically interpretable view of hypergraph learning, where feature propagation is understood as an anisotropic diffusion process governed by local inconsistency and adaptive diffusion coefficient. From this perspective, neural message passing becomes a discretized gradient flow that progressively minimizes a diffusion energy functional. We derive rigorous theoretical guarantees, including energy dissipation, solution boundedness via a discrete maximum principle, and stability under explicit and implicit numerical schemes. The HND framework supports a variety of integration strategies such as non-adaptive-step (like Runge-Kutta) and adaptive-step solvers, enabling the construction of deep, stable, and interpretable architectures. Extensive experiments on benchmark datasets demonstrate that HND achieves competitive performance. Our results highlight the power of PDE-inspired design in enhancing the stability, expressivity, and interpretability of hypergraph learning.
Tackling Over-smoothing on Hypergraphs: A Ricci Flow-guided Neural Diffusion Approach
Mar 16, 2026Hypergraph neural networks (HGNNs) have demonstrated strong capabilities in modeling complex higher-order relationships. However, existing HGNNs often suffer from over-smoothing as the number of layers increases and lack effective control over message passing among nodes. Inspired by the theory of Ricci flow in differential geometry, we theoretically establish that introducing discrete Ricci flow into hypergraph structures can effectively regulate node feature evolution and thereby alleviate over-smoothing. Building on this insight, we propose Ricci Flow-guided Hypergraph Neural Diffusion(RFHND), a novel message passing paradigm for hypergraphs guided by discrete Ricci flow. Specifically, RFHND is based on a PDE system that describes the continuous evolution of node features on hypergraphs and adaptively regulates the rate of information diffusion at the geometric level, preventing feature homogenization and producing high-quality node representations. Experimental results show that RFHND significantly outperforms existing methods across multiple benchmark datasets and demonstrates strong robustness, while also effectively mitigating over-smoothing.
Pano360: Perspective to Panoramic Vision with Geometric Consistency
Mar 12, 2026Prior panorama stitching approaches heavily rely on pairwise feature correspondences and are unable to leverage geometric consistency across multiple views. This leads to severe distortion and misalignment, especially in challenging scenes with weak textures, large parallax, and repetitive patterns. Given that multi-view geometric correspondences can be directly constructed in 3D space, making them more accurate and globally consistent, we extend the 2D alignment task to the 3D photogrammetric space. We adopt a novel transformer-based architecture to achieve 3D awareness and aggregate global information across all views. It directly utilizes camera poses to guide image warping for global alignment in 3D space and employs a multi-feature joint optimization strategy to compute the seams. Additionally, to establish an evaluation benchmark and train our network, we constructed a large-scale dataset of real-world scenes. Extensive experiments show that our method significantly outperforms existing alternatives in alignment accuracy and perceptual quality.
Consistency-Regularized GAN for Few-Shot SAR Target Recognition
Jan 22, 2026Few-shot recognition in synthetic aperture radar (SAR) imagery remains a critical bottleneck for real-world applications due to extreme data scarcity. A promising strategy involves synthesizing a large dataset with a generative adversarial network (GAN), pre-training a model via self-supervised learning (SSL), and then fine-tuning on the few labeled samples. However, this approach faces a fundamental paradox: conventional GANs themselves require abundant data for stable training, contradicting the premise of few-shot learning. To resolve this, we propose the consistency-regularized generative adversarial network (Cr-GAN), a novel framework designed to synthesize diverse, high-fidelity samples even when trained under these severe data limitations. Cr-GAN introduces a dual-branch discriminator that decouples adversarial training from representation learning. This architecture enables a channel-wise feature interpolation strategy to create novel latent features, complemented by a dual-domain cycle consistency mechanism that ensures semantic integrity. Our Cr-GAN framework is adaptable to various GAN architectures, and its synthesized data effectively boosts multiple SSL algorithms. Extensive experiments on the MSTAR and SRSDD datasets validate our approach, with Cr-GAN achieving a highly competitive accuracy of 71.21% and 51.64%, respectively, in the 8-shot setting, significantly outperforming leading baselines, while requiring only ~5 of the parameters of state-of-the-art diffusion models. Code is available at: https://github.com/yikuizhai/Cr-GAN.
Beyond Weight Adaptation: Feature-Space Domain Injection for Cross-Modal Ship Re-Identification
Dec 24, 2025

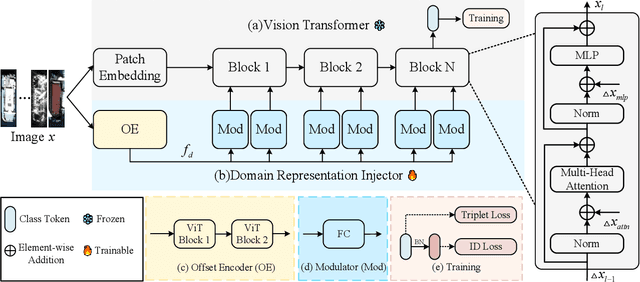

Cross-Modality Ship Re-Identification (CMS Re-ID) is critical for achieving all-day and all-weather maritime target tracking, yet it is fundamentally challenged by significant modality discrepancies. Mainstream solutions typically rely on explicit modality alignment strategies; however, this paradigm heavily depends on constructing large-scale paired datasets for pre-training. To address this, grounded in the Platonic Representation Hypothesis, we explore the potential of Vision Foundation Models (VFMs) in bridging modality gaps. Recognizing the suboptimal performance of existing generic Parameter-Efficient Fine-Tuning (PEFT) methods that operate within the weight space, particularly on limited-capacity models, we shift the optimization perspective to the feature space and propose a novel PEFT strategy termed Domain Representation Injection (DRI). Specifically, while keeping the VFM fully frozen to maximize the preservation of general knowledge, we design a lightweight, learnable Offset Encoder to extract domain-specific representations rich in modality and identity attributes from raw inputs. Guided by the contextual information of intermediate features at different layers, a Modulator adaptively transforms these representations. Subsequently, they are injected into the intermediate layers via additive fusion, dynamically reshaping the feature distribution to adapt to the downstream task without altering the VFM's pre-trained weights. Extensive experimental results demonstrate the superiority of our method, achieving State-of-the-Art (SOTA) performance with minimal trainable parameters. For instance, on the HOSS-ReID dataset, we attain 57.9\% and 60.5\% mAP using only 1.54M and 7.05M parameters, respectively. The code is available at https://github.com/TingfengXian/DRI.
CLIP-FTI: Fine-Grained Face Template Inversion via CLIP-Driven Attribute Conditioning
Dec 17, 2025
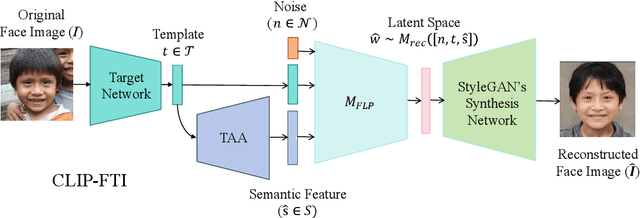
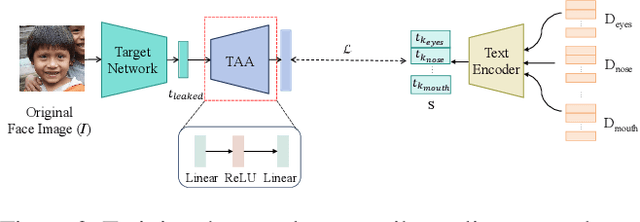
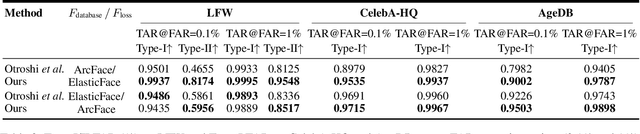
Face recognition systems store face templates for efficient matching. Once leaked, these templates pose a threat: inverting them can yield photorealistic surrogates that compromise privacy and enable impersonation. Although existing research has achieved relatively realistic face template inversion, the reconstructed facial images exhibit over-smoothed facial-part attributes (eyes, nose, mouth) and limited transferability. To address this problem, we present CLIP-FTI, a CLIP-driven fine-grained attribute conditioning framework for face template inversion. Our core idea is to use the CLIP model to obtain the semantic embeddings of facial features, in order to realize the reconstruction of specific facial feature attributes. Specifically, facial feature attribute embeddings extracted from CLIP are fused with the leaked template via a cross-modal feature interaction network and projected into the intermediate latent space of a pretrained StyleGAN. The StyleGAN generator then synthesizes face images with the same identity as the templates but with more fine-grained facial feature attributes. Experiments across multiple face recognition backbones and datasets show that our reconstructions (i) achieve higher identification accuracy and attribute similarity, (ii) recover sharper component-level attribute semantics, and (iii) improve cross-model attack transferability compared to prior reconstruction attacks. To the best of our knowledge, ours is the first method to use additional information besides the face template attack to realize face template inversion and obtains SOTA results.
DEPF: A UAV Multispectral Object Detector with Dual-Domain Enhancement and Priority-Guided Mamba Fusion
Sep 09, 2025Multispectral remote sensing object detection is one of the important application of unmanned aerial vehicle (UAV). However, it faces three challenges. Firstly, the low-light remote sensing images reduce the complementarity during multi-modality fusion. Secondly, the local small target modeling is interfered with redundant information in the fusion stage easily. Thirdly, due to the quadratic computational complexity, it is hard to apply the transformer-based methods on the UAV platform. To address these limitations, motivated by Mamba with linear complexity, a UAV multispectral object detector with dual-domain enhancement and priority-guided mamba fusion (DEPF) is proposed. Firstly, to enhance low-light remote sensing images, Dual-Domain Enhancement Module (DDE) is designed, which contains Cross-Scale Wavelet Mamba (CSWM) and Fourier Details Recovery block (FDR). CSWM applies cross-scale mamba scanning for the low-frequency components to enhance the global brightness of images, while FDR constructs spectrum recovery network to enhance the frequency spectra features for recovering the texture-details. Secondly, to enhance local target modeling and reduce the impact of redundant information during fusion, Priority-Guided Mamba Fusion Module (PGMF) is designed. PGMF introduces the concept of priority scanning, which starts from local targets features according to the priority scores obtained from modality difference. Experiments on DroneVehicle dataset and VEDAI dataset reports that, DEPF performs well on object detection, comparing with state-of-the-art methods. Our code is available in the supplementary material.
Multimodal Feature Fusion Network with Text Difference Enhancement for Remote Sensing Change Detection
Sep 04, 2025Although deep learning has advanced remote sensing change detection (RSCD), most methods rely solely on image modality, limiting feature representation, change pattern modeling, and generalization especially under illumination and noise disturbances. To address this, we propose MMChange, a multimodal RSCD method that combines image and text modalities to enhance accuracy and robustness. An Image Feature Refinement (IFR) module is introduced to highlight key regions and suppress environmental noise. To overcome the semantic limitations of image features, we employ a vision language model (VLM) to generate semantic descriptions of bitemporal images. A Textual Difference Enhancement (TDE) module then captures fine grained semantic shifts, guiding the model toward meaningful changes. To bridge the heterogeneity between modalities, we design an Image Text Feature Fusion (ITFF) module that enables deep cross modal integration. Extensive experiments on LEVIRCD, WHUCD, and SYSUCD demonstrate that MMChange consistently surpasses state of the art methods across multiple metrics, validating its effectiveness for multimodal RSCD. Code is available at: https://github.com/yikuizhai/MMChange.
Evidential Spectrum-Aware Contrastive Learning for OOD Detection in Dynamic Graphs
Jun 09, 2025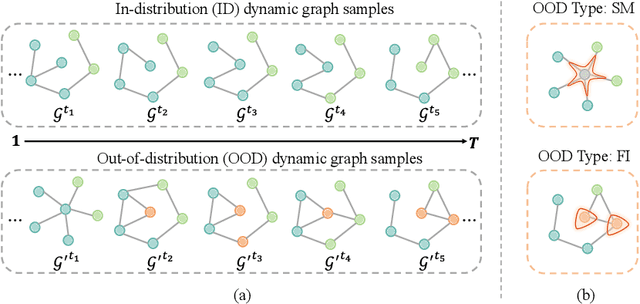
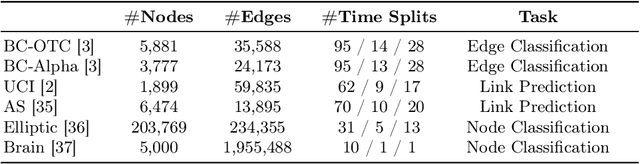
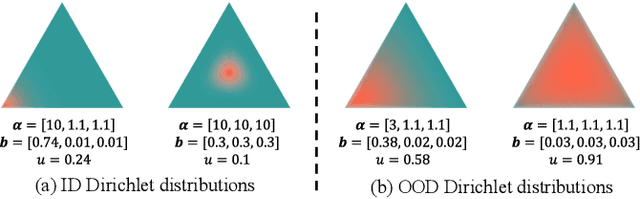
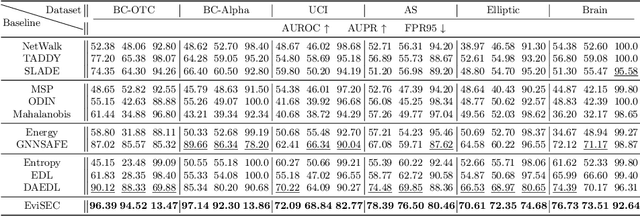
Recently, Out-of-distribution (OOD) detection in dynamic graphs, which aims to identify whether incoming data deviates from the distribution of the in-distribution (ID) training set, has garnered considerable attention in security-sensitive fields. Current OOD detection paradigms primarily focus on static graphs and confront two critical challenges: i) high bias and high variance caused by single-point estimation, which makes the predictions sensitive to randomness in the data; ii) score homogenization resulting from the lack of OOD training data, where the model only learns ID-specific patterns, resulting in overall low OOD scores and a narrow score gap between ID and OOD data. To tackle these issues, we first investigate OOD detection in dynamic graphs through the lens of Evidential Deep Learning (EDL). Specifically, we propose EviSEC, an innovative and effective OOD detector via Evidential Spectrum-awarE Contrastive Learning. We design an evidential neural network to redefine the output as the posterior Dirichlet distribution, explaining the randomness of inputs through the uncertainty of distribution, which is overlooked by single-point estimation. Moreover, spectrum-aware augmentation module generates OOD approximations to identify patterns with high OOD scores, thereby widening the score gap between ID and OOD data and mitigating score homogenization. Extensive experiments on real-world datasets demonstrate that EviSAC effectively detects OOD samples in dynamic graphs.