 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAROS: Robust Federated Learning with Adaptive Scaling against Backdoor Attacks
Jan 05, 2026Federated Learning (FL) enables multiple clients to collaboratively train a shared model without exposing local data. However, backdoor attacks pose a significant threat to FL. These attacks aim to implant a stealthy trigger into the global model, causing it to mislead on inputs that possess a specific trigger while functioning normally on benign data. Although pre-aggregation detection is a main defense direction, existing state-of-the-art defenses often rely on fixed defense parameters. This reliance makes them vulnerable to single-point-of-failure risks, rendering them less effective against sophisticated attackers. To address these limitations, we propose FAROS, an enhanced FL framework that incorporates Adaptive Differential Scaling (ADS) and Robust Core-set Computing (RCC). The ADS mechanism adjusts the defense's sensitivity dynamically, based on the dispersion of uploaded gradients by clients in each round. This allows it to counter attackers who strategically shift between stealthiness and effectiveness. Furthermore, the RCC effectively mitigates the risk of single-point failure by computing the centroid of a core set comprising clients with the highest confidence. We conducted extensive experiments across various datasets, models, and attack scenarios. The results demonstrate that our method outperforms current defenses in both attack success rate and main task accuracy.
Graph Contextual Reinforcement Learning for Efficient Directed Controller Synthesis
Dec 17, 2025Controller synthesis is a formal method approach for automatically generating Labeled Transition System (LTS) controllers that satisfy specified properties. The efficiency of the synthesis process, however, is critically dependent on exploration policies. These policies often rely on fixed rules or strategies learned through reinforcement learning (RL) that consider only a limited set of current features. To address this limitation, this paper introduces GCRL, an approach that enhances RL-based methods by integrating Graph Neural Networks (GNNs). GCRL encodes the history of LTS exploration into a graph structure, allowing it to capture a broader, non-current-based context. In a comparative experiment against state-of-the-art methods, GCRL exhibited superior learning efficiency and generalization across four out of five benchmark domains, except one particular domain characterized by high symmetry and strictly local interactions.
Synergizing Code Coverage and Gameplay Intent: Coverage-Aware Game Playtesting with LLM-Guided Reinforcement Learning
Dec 14, 2025The widespread adoption of the "Games as a Service" model necessitates frequent content updates, placing immense pressure on quality assurance. In response, automated game testing has been viewed as a promising solution to cope with this demanding release cadence. However, existing automated testing approaches typically create a dichotomy: code-centric methods focus on structural coverage without understanding gameplay context, while player-centric agents validate high-level intent but often fail to cover specific underlying code changes. To bridge this gap, we propose SMART (Structural Mapping for Augmented Reinforcement Testing), a novel framework that synergizes structural verification and functional validation for game update testing. SMART leverages large language models (LLMs) to interpret abstract syntax tree (AST) differences and extract functional intent, constructing a context-aware hybrid reward mechanism. This mechanism guides reinforcement learning agents to sequentially fulfill gameplay goals while adaptively exploring modified code branches. We evaluate SMART on two environments, Overcooked and Minecraft. The results demonstrate that SMART significantly outperforms state-of-the-art baselines; it achieves over 94% branch coverage of modified code, nearly double that of traditional reinforcement learning methods, while maintaining a 98% task completion rate, effectively balancing structural comprehensiveness with functional correctness.
Simulation of Language Evolution under Regulated Social Media Platforms: A Synergistic Approach of Large Language Models and Genetic Algorithms
Feb 26, 2025Social media platforms frequently impose restrictive policies to moderate user content, prompting the emergence of creative evasion language strategies. This paper presents a multi-agent framework based on Large Language Models (LLMs) to simulate the iterative evolution of language strategies under regulatory constraints. In this framework, participant agents, as social media users, continuously evolve their language expression, while supervisory agents emulate platform-level regulation by assessing policy violations. To achieve a more faithful simulation, we employ a dual design of language strategies (constraint and expression) to differentiate conflicting goals and utilize an LLM-driven GA (Genetic Algorithm) for the selection, mutation, and crossover of language strategies. The framework is evaluated using two distinct scenarios: an abstract password game and a realistic simulated illegal pet trade scenario. Experimental results demonstrate that as the number of dialogue rounds increases, both the number of uninterrupted dialogue turns and the accuracy of information transmission improve significantly. Furthermore, a user study with 40 participants validates the real-world relevance of the generated dialogues and strategies. Moreover, ablation studies validate the importance of the GA, emphasizing its contribution to long-term adaptability and improved overall results.
BiPC: Bidirectional Probability Calibration for Unsupervised Domain Adaption
Sep 29, 2024Unsupervised Domain Adaptation (UDA) leverages a labeled source domain to solve tasks in an unlabeled target domain. While Transformer-based methods have shown promise in UDA, their application is limited to plain Transformers, excluding Convolutional Neural Networks (CNNs) and hierarchical Transformers. To address this issues, we propose Bidirectional Probability Calibration (BiPC) from a probability space perspective. We demonstrate that the probability outputs from a pre-trained head, after extensive pre-training, are robust against domain gaps and can adjust the probability distribution of the task head. Moreover, the task head can enhance the pre-trained head during adaptation training, improving model performance through bidirectional complementation. Technically, we introduce Calibrated Probability Alignment (CPA) to adjust the pre-trained head's probabilities, such as those from an ImageNet-1k pre-trained classifier. Additionally, we design a Calibrated Gini Impurity (CGI) loss to refine the task head, with calibrated coefficients learned from the pre-trained classifier. BiPC is a simple yet effective method applicable to various networks, including CNNs and Transformers. Experimental results demonstrate its remarkable performance across multiple UDA tasks. Our code will be available at: https://github.com/Wenlve-Zhou/BiPC.
Language Evolution for Evading Social Media Regulation via LLM-based Multi-agent Simulation
May 05, 2024



Social media platforms such as Twitter, Reddit, and Sina Weibo play a crucial role in global communication but often encounter strict regulations in geopolitically sensitive regions. This situation has prompted users to ingeniously modify their way of communicating, frequently resorting to coded language in these regulated social media environments. This shift in communication is not merely a strategy to counteract regulation, but a vivid manifestation of language evolution, demonstrating how language naturally evolves under societal and technological pressures. Studying the evolution of language in regulated social media contexts is of significant importance for ensuring freedom of speech, optimizing content moderation, and advancing linguistic research. This paper proposes a multi-agent simulation framework using Large Language Models (LLMs) to explore the evolution of user language in regulated social media environments. The framework employs LLM-driven agents: supervisory agent who enforce dialogue supervision and participant agents who evolve their language strategies while engaging in conversation, simulating the evolution of communication styles under strict regulations aimed at evading social media regulation. The study evaluates the framework's effectiveness through a range of scenarios from abstract scenarios to real-world situations. Key findings indicate that LLMs are capable of simulating nuanced language dynamics and interactions in constrained settings, showing improvement in both evading supervision and information accuracy as evolution progresses. Furthermore, it was found that LLM agents adopt different strategies for different scenarios.
Graph Federated Learning Based on the Decentralized Framework
Jul 19, 2023



Graph learning has a wide range of applications in many scenarios, which require more need for data privacy. Federated learning is an emerging distributed machine learning approach that leverages data from individual devices or data centers to improve the accuracy and generalization of the model, while also protecting the privacy of user data. Graph-federated learning is mainly based on the classical federated learning framework i.e., the Client-Server framework. However, the Client-Server framework faces problems such as a single point of failure of the central server and poor scalability of network topology. First, we introduce the decentralized framework to graph-federated learning. Second, determine the confidence among nodes based on the similarity of data among nodes, subsequently, the gradient information is then aggregated by linear weighting based on confidence. Finally, the proposed method is compared with FedAvg, Fedprox, GCFL, and GCFL+ to verify the effectiveness of the proposed method. Experiments demonstrate that the proposed method outperforms other methods.
Value Iteration Networks with Gated Summarization Module
May 16, 2023



In this paper, we address the challenges faced by Value Iteration Networks (VIN) in handling larger input maps and mitigating the impact of accumulated errors caused by increased iterations. We propose a novel approach, Value Iteration Networks with Gated Summarization Module (GS-VIN), which incorporates two main improvements: (1) employing an Adaptive Iteration Strategy in the Value Iteration module to reduce the number of iterations, and (2) introducing a Gated Summarization module to summarize the iterative process. The adaptive iteration strategy uses larger convolution kernels with fewer iteration times, reducing network depth and increasing training stability while maintaining the accuracy of the planning process. The gated summarization module enables the network to emphasize the entire planning process, rather than solely relying on the final global planning outcome, by temporally and spatially resampling the entire planning process within the VI module. We conduct experiments on 2D grid world path-finding problems and the Atari Mr. Pac-man environment, demonstrating that GS-VIN outperforms the baseline in terms of single-step accuracy, planning success rate, and overall performance across different map sizes. Additionally, we provide an analysis of the relationship between input size, kernel size, and the number of iterations in VI-based models, which is applicable to a majority of VI-based models and offers valuable insights for researchers and industrial deployment.
A Meta Reinforcement Learning-based Approach for Self-Adaptive System
May 11, 2021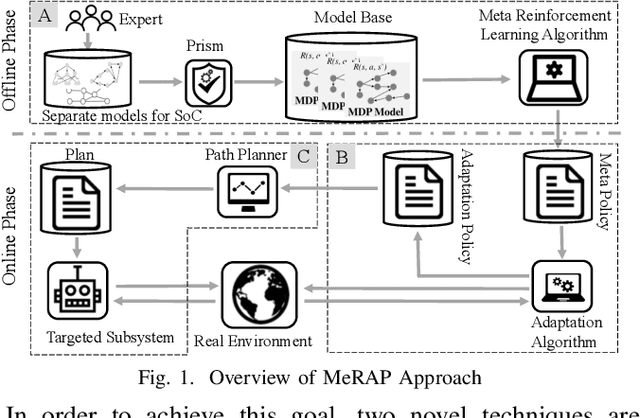
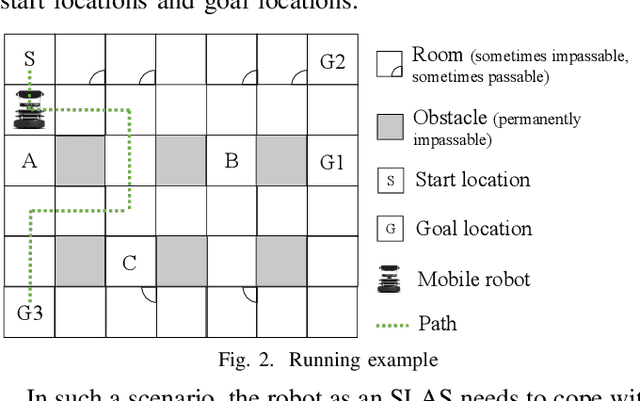


A self-learning adaptive system (SLAS) uses machine learning to enable and enhance its adaptability. Such systems are expected to perform well in dynamic situations. For learning high-performance adaptation policy, some assumptions must be made on the environment-system dynamics when information about the real situation is incomplete. However, these assumptions cannot be expected to be always correct, and yet it is difficult to enumerate all possible assumptions. This leads to the problem of incomplete-information learning. We consider this problem as multiple model problem in terms of finding the adaptation policy that can cope with multiple models of environment-system dynamics. This paper proposes a novel approach to engineering the online adaptation of SLAS. It separates three concerns that are related to the adaptation policy and presents the modeling and synthesis process, with the goal of achieving higher model construction efficiency. In addition, it designs a meta-reinforcement learning algorithm for learning the meta policy over the multiple models, so that the meta policy can quickly adapt to the real environment-system dynamics. At last, it reports the case study on a robotic system to evaluate the adaptability of the approach.
System Component-Level Self-Adaptations for Security via Bayesian Games
Mar 12, 2021
Security attacks present unique challenges to self-adaptive system design due to the adversarial nature of the environment. However, modeling the system as a single player, as done in prior works in security domain, is insufficient for the system under partial compromise and for the design of fine-grained defensive strategies where the rest of the system with autonomy can cooperate to mitigate the impact of attacks. To deal with such issues, we propose a new self-adaptive framework incorporating Bayesian game and model the defender (i.e., the system) at the granularity of components in system architecture. The system architecture model is translated into a Bayesian multi-player game, where each component is modeled as an independent player while security attacks are encoded as variant types for the components. The defensive strategy for the system is dynamically computed by solving the pure equilibrium to achieve the best possible system utility, improving the resiliency of the system against security attacks.