 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConSA: Controllable Sparsity in Hybrid Attention via Learnable Allocation
Jun 16, 2026Hybrid architectures combining full attention (FA) and sliding-window attention (SWA) are a promising paradigm for efficient LLM inference. However, existing methods typically rely on hand-crafted rules or simple post-hoc heuristics for FA/SWA allocation and offer limited analysis of the attention behaviors underlying these designs. We propose Controllable Sparsity in Hybrid Attention (ConSA), a framework that learns optimal FA/SWA assignment under a user-specified sparsity target. ConSA employs L0 regularization to learn binary masks selecting between FA and SWA for each attention unit, while an augmented Lagrangian constraint enforces the target sparsity at either layer or KV-head granularity. We evaluate ConSA on two LLMs at the 0.6B and 1.7B scales. Learned allocations consistently outperform rule-based baselines, with KV-head-wise allocation yielding clear gains over layer-wise allocation. The learned patterns place SWA in the bottom layers and concentrate FA into contiguous middle-layer blocks, diverging from evenly interleaved patterns in rule-based methods. This structure persists across model scales, sparsity levels, and allocation granularities, revealing a fine-grained spectrum of intrinsic attention behaviors that underlies the learned allocation.
Sparse Growing Transformer: Training-Time Sparse Depth Allocation via Progressive Attention Looping
Mar 25, 2026Existing approaches to increasing the effective depth of Transformers predominantly rely on parameter reuse, extending computation through recursive execution. Under this paradigm, the network structure remains static along the training timeline, and additional computational depth is uniformly assigned to entire blocks at the parameter level. This rigidity across training time and parameter space leads to substantial computational redundancy during training. In contrast, we argue that depth allocation during training should not be a static preset, but rather a progressively growing structural process. Our systematic analysis reveals a deep-to-shallow maturation trajectory across layers, where high-entropy attention heads play a crucial role in semantic integration. Motivated by this observation, we introduce the Sparse Growing Transformer (SGT). SGT is a training-time sparse depth allocation framework that progressively extends recurrence from deeper to shallower layers via targeted attention looping on informative heads. This mechanism induces structural sparsity by selectively increasing depth only for a small subset of parameters as training evolves. Extensive experiments across multiple parameter scales demonstrate that SGT consistently outperforms training-time static block-level looping baselines under comparable settings, while reducing the additional training FLOPs overhead from approximately 16--20% to only 1--3% relative to a standard Transformer backbone.
Mixture of Universal Experts: Scaling Virtual Width via Depth-Width Transformation
Mar 05, 2026Mixture-of-Experts (MoE) decouples model capacity from per-token computation, yet their scalability remains limited by the physical dimensions of depth and width. To overcome this, we propose Mixture of Universal Experts (MOUE),a MoE generalization introducing a novel scaling dimension: Virtual Width. In general, MoUE aims to reuse a universal layer-agnostic expert pool across layers, converting depth into virtual width under a fixed per-token activation budget. However, two challenges remain: a routing path explosion from recursive expert reuse, and a mismatch between the exposure induced by reuse and the conventional load-balancing objectives. We address these with three core components: a Staggered Rotational Topology for structured expert sharing, a Universal Expert Load Balance for depth-aware exposure correction, and a Universal Router with lightweight trajectory state for coherent multi-step routing. Empirically, MoUE consistently outperforms matched MoE baselines by up to 1.3% across scaling regimes, enables progressive conversion of existing MoE checkpoints with up to 4.2% gains, and reveals a new scaling dimension for MoE architectures.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
VideoAR: Autoregressive Video Generation via Next-Frame & Scale Prediction
Jan 09, 2026Recent advances in video generation have been dominated by diffusion and flow-matching models, which produce high-quality results but remain computationally intensive and difficult to scale. In this work, we introduce VideoAR, the first large-scale Visual Autoregressive (VAR) framework for video generation that combines multi-scale next-frame prediction with autoregressive modeling. VideoAR disentangles spatial and temporal dependencies by integrating intra-frame VAR modeling with causal next-frame prediction, supported by a 3D multi-scale tokenizer that efficiently encodes spatio-temporal dynamics. To improve long-term consistency, we propose Multi-scale Temporal RoPE, Cross-Frame Error Correction, and Random Frame Mask, which collectively mitigate error propagation and stabilize temporal coherence. Our multi-stage pretraining pipeline progressively aligns spatial and temporal learning across increasing resolutions and durations. Empirically, VideoAR achieves new state-of-the-art results among autoregressive models, improving FVD on UCF-101 from 99.5 to 88.6 while reducing inference steps by over 10x, and reaching a VBench score of 81.74-competitive with diffusion-based models an order of magnitude larger. These results demonstrate that VideoAR narrows the performance gap between autoregressive and diffusion paradigms, offering a scalable, efficient, and temporally consistent foundation for future video generation research.
Inner Thinking Transformer: Leveraging Dynamic Depth Scaling to Foster Adaptive Internal Thinking
Feb 19, 2025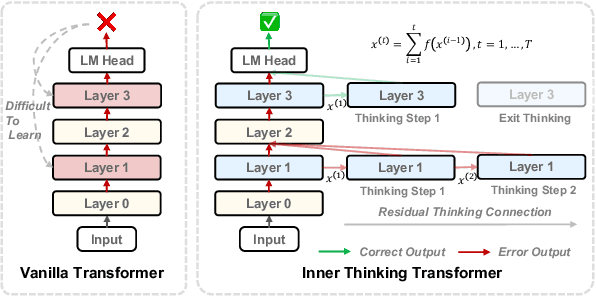
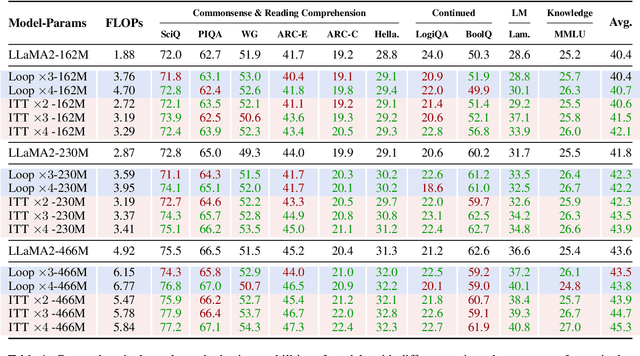
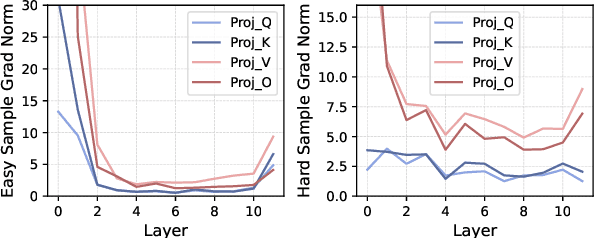
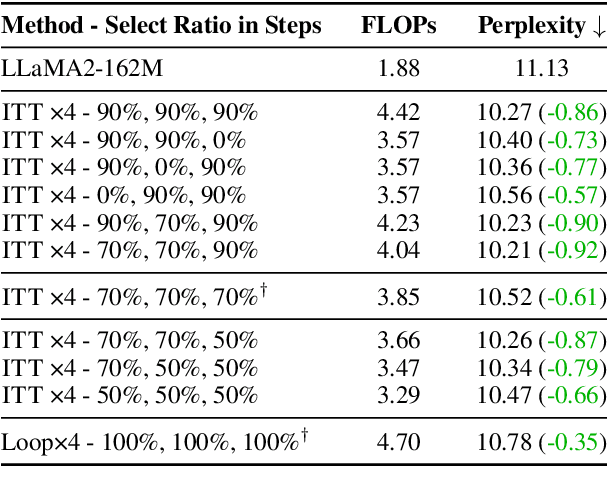
Large language models (LLMs) face inherent performance bottlenecks under parameter constraints, particularly in processing critical tokens that demand complex reasoning. Empirical analysis reveals challenging tokens induce abrupt gradient spikes across layers, exposing architectural stress points in standard Transformers. Building on this insight, we propose Inner Thinking Transformer (ITT), which reimagines layer computations as implicit thinking steps. ITT dynamically allocates computation through Adaptive Token Routing, iteratively refines representations via Residual Thinking Connections, and distinguishes reasoning phases using Thinking Step Encoding. ITT enables deeper processing of critical tokens without parameter expansion. Evaluations across 162M-466M parameter models show ITT achieves 96.5\% performance of a 466M Transformer using only 162M parameters, reduces training data by 43.2\%, and outperforms Transformer/Loop variants in 11 benchmarks. By enabling elastic computation allocation during inference, ITT balances performance and efficiency through architecture-aware optimization of implicit thinking pathways.
Mixture of Hidden-Dimensions Transformer
Dec 10, 2024



Transformer models encounter challenges in scaling hidden dimensions efficiently, as uniformly increasing them inflates computational and memory costs while failing to emphasize the most relevant features for each token. For further understanding, we study hidden dimension sparsity and observe that trained Transformers utilize only a small fraction of token dimensions, revealing an "activation flow" pattern. Notably, there are shared sub-dimensions with sustained activation across multiple consecutive tokens and specialized sub-dimensions uniquely activated for each token. To better model token-relevant sub-dimensions, we propose MoHD (Mixture of Hidden Dimensions), a sparse conditional activation architecture. Particularly, MoHD employs shared sub-dimensions for common token features and a routing mechanism to dynamically activate specialized sub-dimensions. To mitigate potential information loss from sparsity, we design activation scaling and group fusion mechanisms to preserve activation flow. In this way, MoHD expands hidden dimensions with negligible increases in computation or parameters, efficient training and inference while maintaining performance. Evaluations across 10 NLP tasks show that MoHD surpasses Vanilla Transformers in parameter efficiency and task performance. It achieves 1.7% higher performance with 50% fewer activation parameters and 3.7% higher performance with a 3x parameter expansion at constant activation cost. MOHD offers a new perspective for scaling the model, showcasing the potential of hidden dimension sparsity to boost efficiency
MoR: Mixture of Ranks for Low-Rank Adaptation Tuning
Oct 17, 2024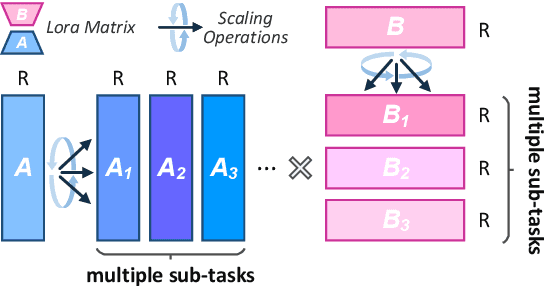
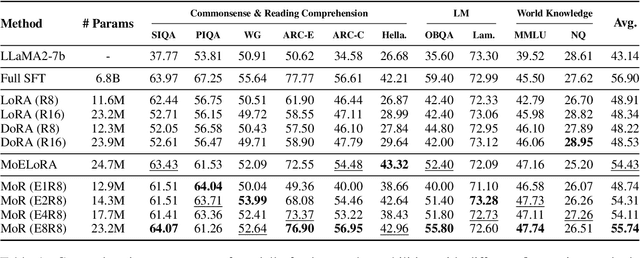
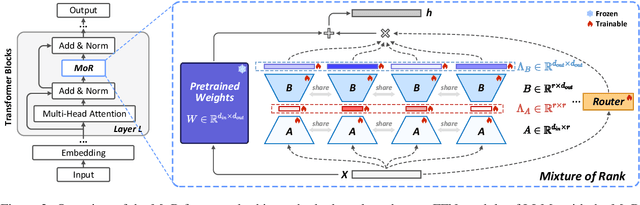

Low-Rank Adaptation (LoRA) drives research to align its performance with full fine-tuning. However, significant challenges remain: (1) Simply increasing the rank size of LoRA does not effectively capture high-rank information, which leads to a performance bottleneck.(2) MoE-style LoRA methods substantially increase parameters and inference latency, contradicting the goals of efficient fine-tuning and ease of application. To address these challenges, we introduce Mixture of Ranks (MoR), which learns rank-specific information for different tasks based on input and efficiently integrates multi-rank information. We firstly propose a new framework that equates the integration of multiple LoRAs to expanding the rank of LoRA. Moreover, we hypothesize that low-rank LoRA already captures sufficient intrinsic information, and MoR can derive high-rank information through mathematical transformations of the low-rank components. Thus, MoR can reduces the learning difficulty of LoRA and enhances its multi-task capabilities. MoR achieves impressive results, with MoR delivering a 1.31\% performance improvement while using only 93.93\% of the parameters compared to baseline methods.
BiPC: Bidirectional Probability Calibration for Unsupervised Domain Adaption
Sep 29, 2024Unsupervised Domain Adaptation (UDA) leverages a labeled source domain to solve tasks in an unlabeled target domain. While Transformer-based methods have shown promise in UDA, their application is limited to plain Transformers, excluding Convolutional Neural Networks (CNNs) and hierarchical Transformers. To address this issues, we propose Bidirectional Probability Calibration (BiPC) from a probability space perspective. We demonstrate that the probability outputs from a pre-trained head, after extensive pre-training, are robust against domain gaps and can adjust the probability distribution of the task head. Moreover, the task head can enhance the pre-trained head during adaptation training, improving model performance through bidirectional complementation. Technically, we introduce Calibrated Probability Alignment (CPA) to adjust the pre-trained head's probabilities, such as those from an ImageNet-1k pre-trained classifier. Additionally, we design a Calibrated Gini Impurity (CGI) loss to refine the task head, with calibrated coefficients learned from the pre-trained classifier. BiPC is a simple yet effective method applicable to various networks, including CNNs and Transformers. Experimental results demonstrate its remarkable performance across multiple UDA tasks. Our code will be available at: https://github.com/Wenlve-Zhou/BiPC.
NACL: A General and Effective KV Cache Eviction Framework for LLMs at Inference Time
Aug 07, 2024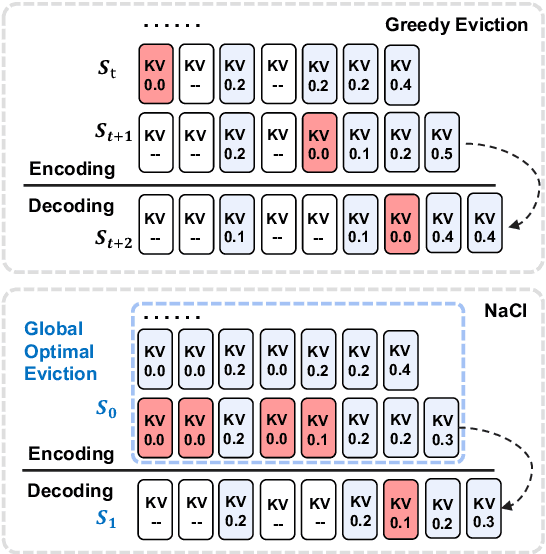
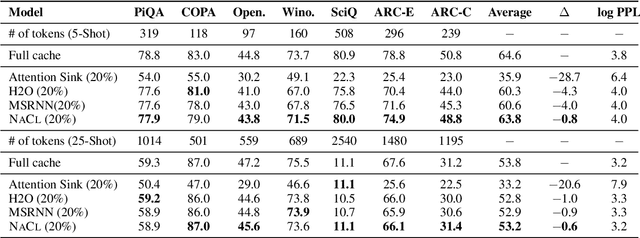
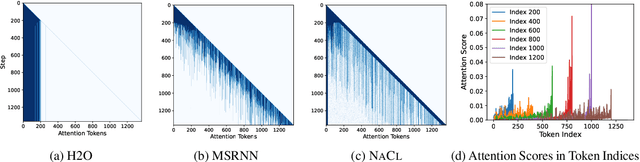
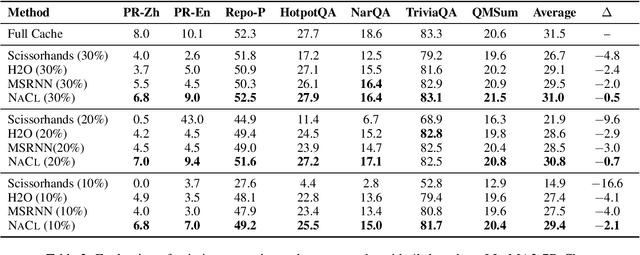
Large Language Models (LLMs) have ignited an innovative surge of AI applications, marking a new era of exciting possibilities equipped with extended context windows. However, hosting these models is cost-prohibitive mainly due to the extensive memory consumption of KV Cache involving long-context modeling. Despite several works proposing to evict unnecessary tokens from the KV Cache, most of them rely on the biased local statistics of accumulated attention scores and report performance using unconvincing metric like perplexity on inadequate short-text evaluation. In this paper, we propose NACL, a general framework for long-context KV cache eviction that achieves more optimal and efficient eviction in a single operation during the encoding phase. Due to NACL's efficiency, we combine more accurate attention score statistics in PROXY TOKENS EVICTION with the diversified random eviction strategy of RANDOM EVICTION, aiming to alleviate the issue of attention bias and enhance the robustness in maintaining pivotal tokens for long-context modeling tasks. Notably, our method significantly improves the performance on short- and long-text tasks by 80% and 76% respectively, reducing KV Cache by up to 50% with over 95% performance maintenance. The code is available at https: //github.com/PaddlePaddle/Research/ tree/master/NLP/ACL2024-NACL.