 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoR: Mixture of Ranks for Low-Rank Adaptation Tuning
Paper and Code
Oct 17, 2024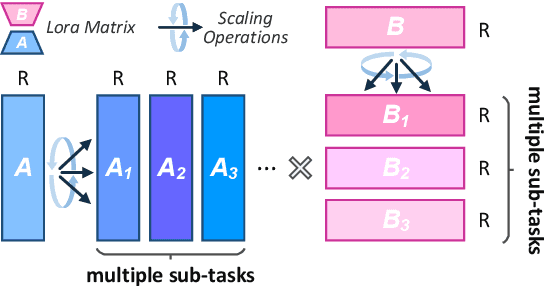
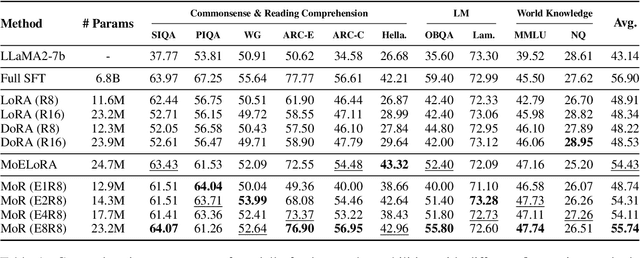
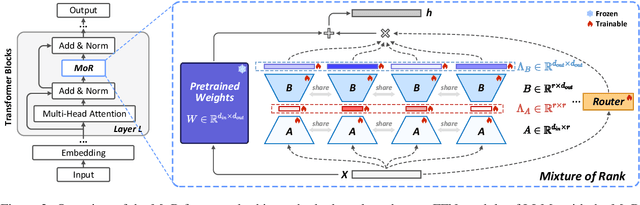

Low-Rank Adaptation (LoRA) drives research to align its performance with full fine-tuning. However, significant challenges remain: (1) Simply increasing the rank size of LoRA does not effectively capture high-rank information, which leads to a performance bottleneck.(2) MoE-style LoRA methods substantially increase parameters and inference latency, contradicting the goals of efficient fine-tuning and ease of application. To address these challenges, we introduce Mixture of Ranks (MoR), which learns rank-specific information for different tasks based on input and efficiently integrates multi-rank information. We firstly propose a new framework that equates the integration of multiple LoRAs to expanding the rank of LoRA. Moreover, we hypothesize that low-rank LoRA already captures sufficient intrinsic information, and MoR can derive high-rank information through mathematical transformations of the low-rank components. Thus, MoR can reduces the learning difficulty of LoRA and enhances its multi-task capabilities. MoR achieves impressive results, with MoR delivering a 1.31\% performance improvement while using only 93.93\% of the parameters compared to baseline methods.