 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffDet4SAR: Diffusion-based Aircraft Target Detection Network for SAR Images
Apr 04, 2024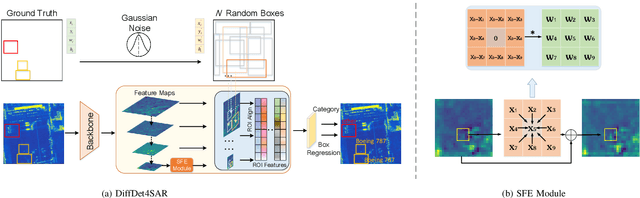


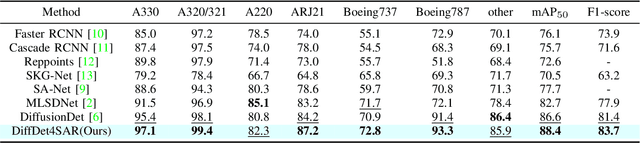
Aircraft target detection in SAR images is a challenging task due to the discrete scattering points and severe background clutter interference. Currently, methods with convolution-based or transformer-based paradigms cannot adequately address these issues. In this letter, we explore diffusion models for SAR image aircraft target detection for the first time and propose a novel \underline{Diff}usion-based aircraft target \underline{Det}ection network \underline{for} \underline{SAR} images (DiffDet4SAR). Specifically, the proposed DiffDet4SAR yields two main advantages for SAR aircraft target detection: 1) DiffDet4SAR maps the SAR aircraft target detection task to a denoising diffusion process of bounding boxes without heuristic anchor size selection, effectively enabling large variations in aircraft sizes to be accommodated; and 2) the dedicatedly designed Scattering Feature Enhancement (SFE) module further reduces the clutter intensity and enhances the target saliency during inference. Extensive experimental results on the SAR-AIRcraft-1.0 dataset show that the proposed DiffDet4SAR achieves 88.4\% mAP$_{50}$, outperforming the state-of-the-art methods by 6\%. Code is availabel at \href{https://github.com/JoyeZLearning/DiffDet4SAR}.
DI-V2X: Learning Domain-Invariant Representation for Vehicle-Infrastructure Collaborative 3D Object Detection
Dec 25, 2023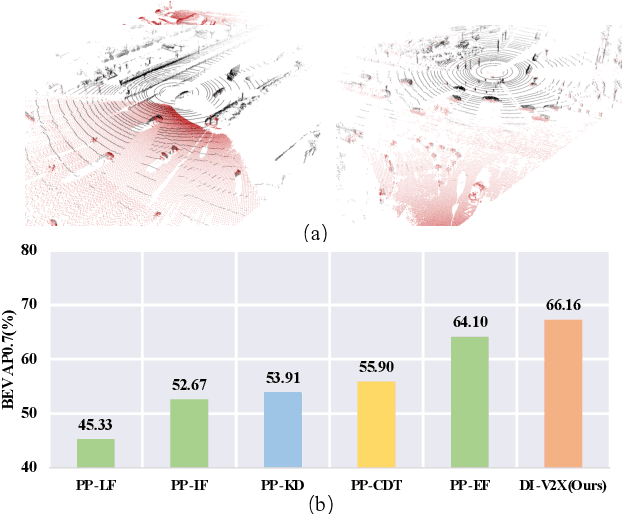
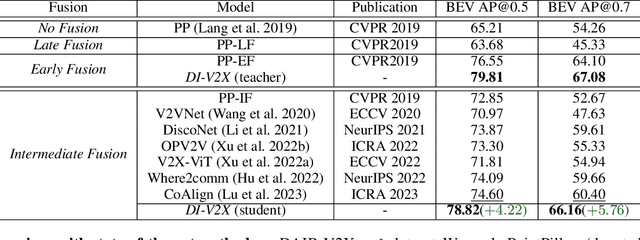
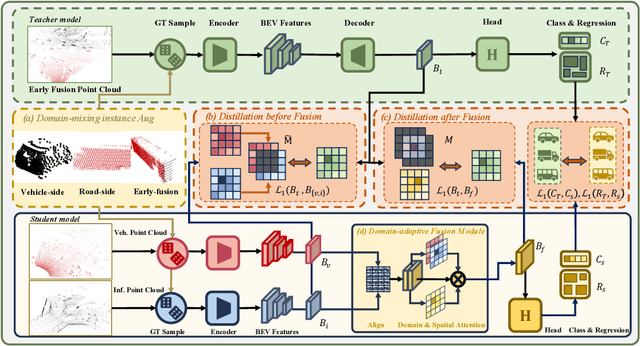
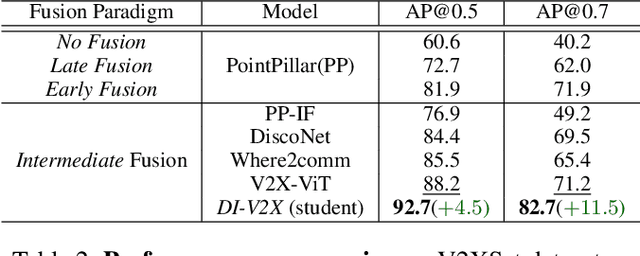
Vehicle-to-Everything (V2X) collaborative perception has recently gained significant attention due to its capability to enhance scene understanding by integrating information from various agents, e.g., vehicles, and infrastructure. However, current works often treat the information from each agent equally, ignoring the inherent domain gap caused by the utilization of different LiDAR sensors of each agent, thus leading to suboptimal performance. In this paper, we propose DI-V2X, that aims to learn Domain-Invariant representations through a new distillation framework to mitigate the domain discrepancy in the context of V2X 3D object detection. DI-V2X comprises three essential components: a domain-mixing instance augmentation (DMA) module, a progressive domain-invariant distillation (PDD) module, and a domain-adaptive fusion (DAF) module. Specifically, DMA builds a domain-mixing 3D instance bank for the teacher and student models during training, resulting in aligned data representation. Next, PDD encourages the student models from different domains to gradually learn a domain-invariant feature representation towards the teacher, where the overlapping regions between agents are employed as guidance to facilitate the distillation process. Furthermore, DAF closes the domain gap between the students by incorporating calibration-aware domain-adaptive attention. Extensive experiments on the challenging DAIR-V2X and V2XSet benchmark datasets demonstrate DI-V2X achieves remarkable performance, outperforming all the previous V2X models. Code is available at https://github.com/Serenos/DI-V2X
Secure and Fast Asynchronous Vertical Federated Learning via Cascaded Hybrid Optimization
Jun 29, 2023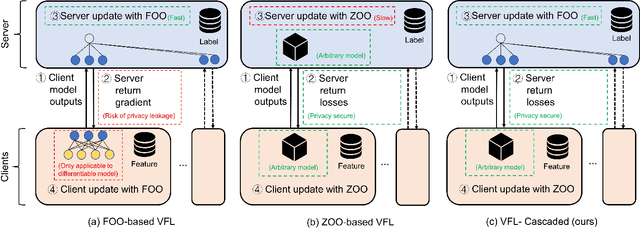
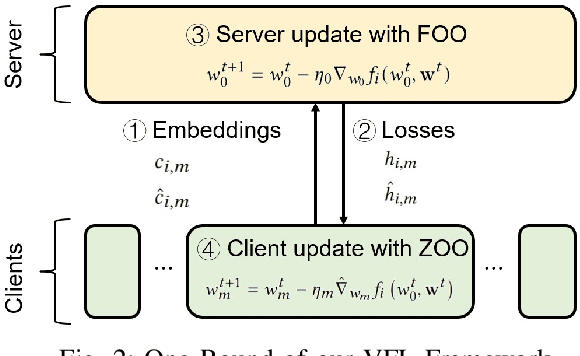
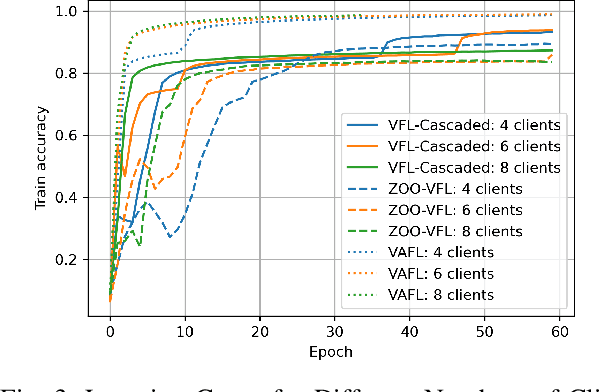
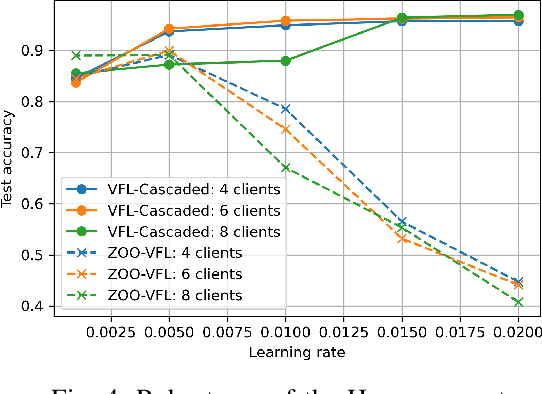
Vertical Federated Learning (VFL) attracts increasing attention because it empowers multiple parties to jointly train a privacy-preserving model over vertically partitioned data. Recent research has shown that applying zeroth-order optimization (ZOO) has many advantages in building a practical VFL algorithm. However, a vital problem with the ZOO-based VFL is its slow convergence rate, which limits its application in handling modern large models. To address this problem, we propose a cascaded hybrid optimization method in VFL. In this method, the downstream models (clients) are trained with ZOO to protect privacy and ensure that no internal information is shared. Meanwhile, the upstream model (server) is updated with first-order optimization (FOO) locally, which significantly improves the convergence rate, making it feasible to train the large models without compromising privacy and security. We theoretically prove that our VFL framework converges faster than the ZOO-based VFL, as the convergence of our framework is not limited by the size of the server model, making it effective for training large models with the major part on the server. Extensive experiments demonstrate that our method achieves faster convergence than the ZOO-based VFL framework, while maintaining an equivalent level of privacy protection. Moreover, we show that the convergence of our VFL is comparable to the unsafe FOO-based VFL baseline. Additionally, we demonstrate that our method makes the training of a large model feasible.
DINF: Dynamic Instance Noise Filter for Occluded Pedestrian Detection
Jan 13, 2023



Occlusion issue is the biggest challenge in pedestrian detection. RCNN-based detectors extract instance features by cropping rectangle regions of interest in the feature maps. However, the visible pixels of the occluded objects are limited, making the rectangle instance feature mixed with a lot of instance-irrelevant noise information. Besides, by counting the number of instances with different degrees of overlap of CrowdHuman dataset, we find that the number of severely overlapping objects and the number of slightly overlapping objects are unbalanced, which may exacerbate the challenges posed by occlusion issues. Regarding to the noise issue, from the perspective of denoising, an iterable dynamic instance noise filter (DINF) is proposed for the RCNN-based pedestrian detectors to improve the signal-noise ratio of the instance feature. Simulating the wavelet denoising process, we use the instance feature vector to generate dynamic convolutional kernels to transform the RoIs features to a domain in which the near-zero values represent the noise information. Then, soft thresholding with channel-wise adaptive thresholds is applied to convert the near-zero values to zero to filter out noise information. For the imbalance issue, we propose an IoU-Focal factor (IFF) to modulate the contributions of the well-regressed boxes and the bad-regressed boxes to the loss in the training process, paying more attention to the minority severely overlapping objects. Extensive experiments conducted on CrowdHuman and CityPersons demonstrate that our methods can help RCNN-based pedestrian detectors achieve state-of-the-art performance.
X-PuDu at SemEval-2022 Task 7: A Replaced Token Detection Task Pre-trained Model with Pattern-aware Ensembling for Identifying Plausible Clarifications
Nov 27, 2022This paper describes our winning system on SemEval 2022 Task 7: Identifying Plausible Clarifications of Implicit and Underspecified Phrases in Instructional Texts. A replaced token detection pre-trained model is utilized with minorly different task-specific heads for SubTask-A: Multi-class Classification and SubTask-B: Ranking. Incorporating a pattern-aware ensemble method, our system achieves a 68.90% accuracy score and 0.8070 spearman's rank correlation score surpassing the 2nd place with a large margin by 2.7 and 2.2 percent points for SubTask-A and SubTask-B, respectively. Our approach is simple and easy to implement, and we conducted ablation studies and qualitative and quantitative analyses for the working strategies used in our system.
TSAA: A Two-Stage Anchor Assignment Method towards Anchor Drift in Crowded Object Detection
Nov 11, 2022



Among current anchor-based detectors, a positive anchor box will be intuitively assigned to the object that overlaps it the most. The assigned label to each anchor will directly determine the optimization direction of the corresponding prediction box, including the direction of box regression and category prediction. In our practice of crowded object detection, however, the results show that a positive anchor does not always regress toward the object that overlaps it the most when multiple objects overlap. We name it anchor drift. The anchor drift reflects that the anchor-object matching relation, which is determined by the degree of overlap between anchors and objects, is not always optimal. Conflicts between the fixed matching relation and learned experience in the past training process may cause ambiguous predictions and thus raise the false-positive rate. In this paper, a simple but efficient adaptive two-stage anchor assignment (TSAA) method is proposed. It utilizes the final prediction boxes rather than the fixed anchors to calculate the overlap degree with objects to determine which object to regress for each anchor. The participation of the prediction box makes the anchor-object assignment mechanism adaptive. Extensive experiments are conducted on three classic detectors RetinaNet, Faster-RCNN and YOLOv3 on CrowdHuman and COCO to evaluate the effectiveness of TSAA. The results show that TSAA can significantly improve the detectors' performance without additional computational costs or network structure changes.
Toward Clinically Assisted Colorectal Polyp Recognition via Structured Cross-modal Representation Consistency
Jun 24, 2022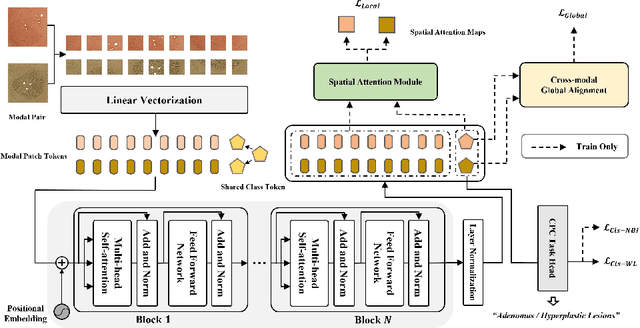
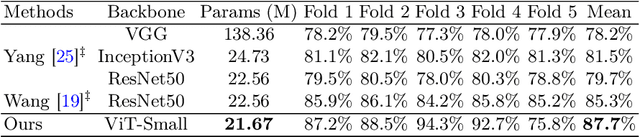
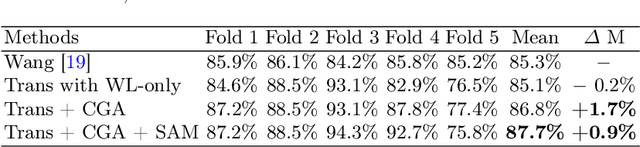
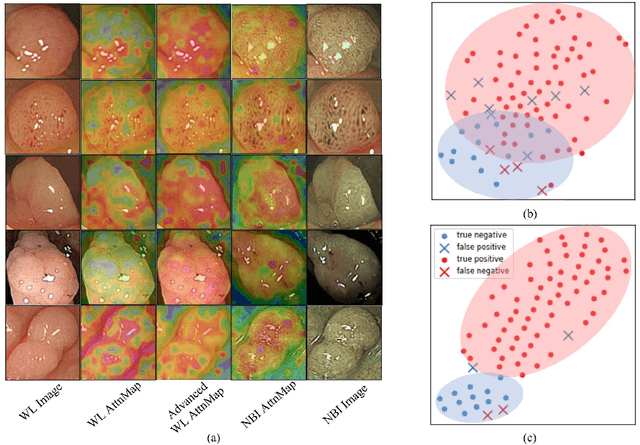
The colorectal polyps classification is a critical clinical examination. To improve the classification accuracy, most computer-aided diagnosis algorithms recognize colorectal polyps by adopting Narrow-Band Imaging (NBI). However, the NBI usually suffers from missing utilization in real clinic scenarios since the acquisition of this specific image requires manual switching of the light mode when polyps have been detected by using White-Light (WL) images. To avoid the above situation, we propose a novel method to directly achieve accurate white-light colonoscopy image classification by conducting structured cross-modal representation consistency. In practice, a pair of multi-modal images, i.e. NBI and WL, are fed into a shared Transformer to extract hierarchical feature representations. Then a novel designed Spatial Attention Module (SAM) is adopted to calculate the similarities between the class token and patch tokens %from multi-levels for a specific modality image. By aligning the class tokens and spatial attention maps of paired NBI and WL images at different levels, the Transformer achieves the ability to keep both global and local representation consistency for the above two modalities. Extensive experimental results illustrate the proposed method outperforms the recent studies with a margin, realizing multi-modal prediction with a single Transformer while greatly improving the classification accuracy when only with WL images.
Colorectal Polyp Classification from White-light Colonoscopy Images via Domain Alignment
Aug 05, 2021
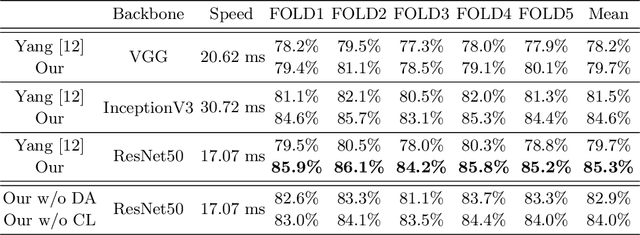

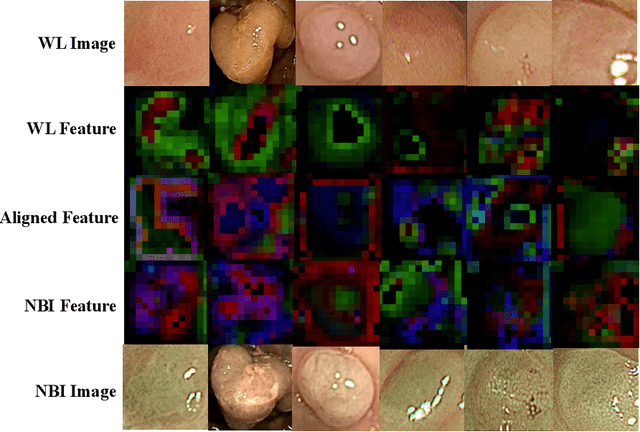
Differentiation of colorectal polyps is an important clinical examination. A computer-aided diagnosis system is required to assist accurate diagnosis from colonoscopy images. Most previous studies at-tempt to develop models for polyp differentiation using Narrow-Band Imaging (NBI) or other enhanced images. However, the wide range of these models' applications for clinical work has been limited by the lagging of imaging techniques. Thus, we propose a novel framework based on a teacher-student architecture for the accurate colorectal polyp classification (CPC) through directly using white-light (WL) colonoscopy images in the examination. In practice, during training, the auxiliary NBI images are utilized to train a teacher network and guide the student network to acquire richer feature representation from WL images. The feature transfer is realized by domain alignment and contrastive learning. Eventually the final student network has the ability to extract aligned features from only WL images to facilitate the CPC task. Besides, we release the first public-available paired CPC dataset containing WL-NBI pairs for the alignment training. Quantitative and qualitative evaluation indicates that the proposed method outperforms the previous methods in CPC, improving the accuracy by 5.6%with very fast speed.
Understanding the Disharmony between Weight Normalization Family and Weight Decay: $ε-$shifted $L_2$ Regularizer
Nov 14, 2019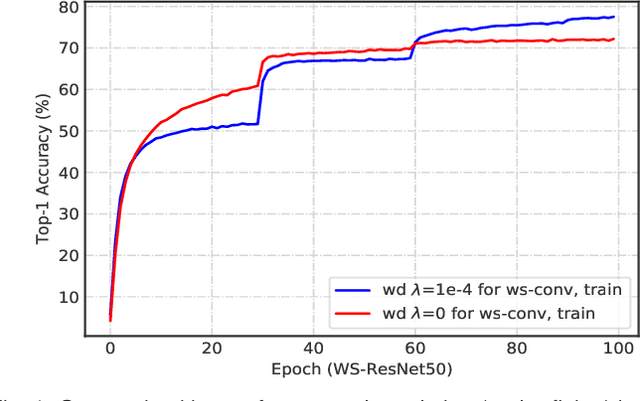

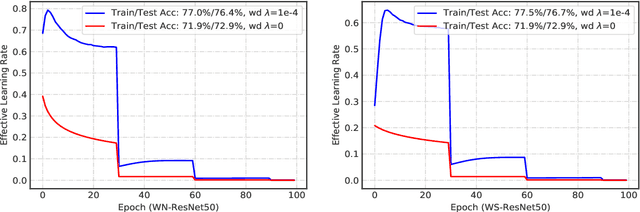
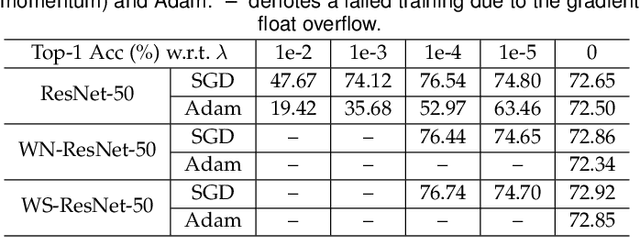
The merits of fast convergence and potentially better performance of the weight normalization family have drawn increasing attention in recent years. These methods use standardization or normalization that changes the weight $\boldsymbol{W}$ to $\boldsymbol{W}'$, which makes $\boldsymbol{W}'$ independent to the magnitude of $\boldsymbol{W}$. Surprisingly, $\boldsymbol{W}$ must be decayed during gradient descent, otherwise we will observe a severe under-fitting problem, which is very counter-intuitive since weight decay is widely known to prevent deep networks from over-fitting. In this paper, we \emph{theoretically} prove that the weight decay term $\frac{1}{2}\lambda||{\boldsymbol{W}}||^2$ merely modulates the effective learning rate for improving objective optimization, and has no influence on generalization when the weight normalization family is compositely employed. Furthermore, we also expose several critical problems when introducing weight decay term to weight normalization family, including the missing of global minimum and training instability. To address these problems, we propose an $\epsilon-$shifted $L_2$ regularizer, which shifts the $L_2$ objective by a positive constant $\epsilon$. Such a simple operation can theoretically guarantee the existence of global minimum, while preventing the network weights from being too small and thus avoiding gradient float overflow. It significantly improves the training stability and can achieve slightly better performance in our practice. The effectiveness of $\epsilon-$shifted $L_2$ regularizer is comprehensively validated on the ImageNet, CIFAR-100, and COCO datasets. Our codes and pretrained models will be released in https://github.com/implus/PytorchInsight.