 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedOne: Query-Efficient Federated Learning for Black-box Discrete Prompt Learning
Jun 17, 2025

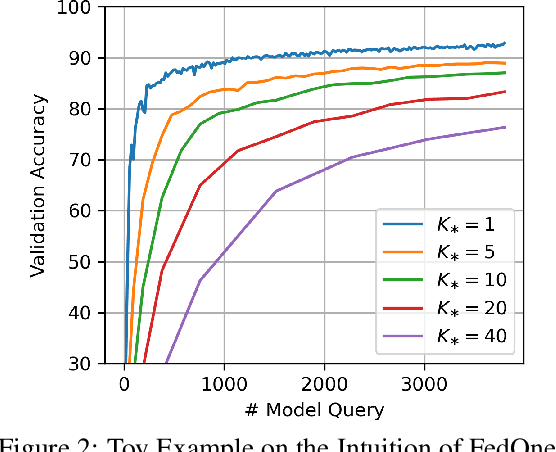

Black-Box Discrete Prompt Learning is a prompt-tuning method that optimizes discrete prompts without accessing model parameters or gradients, making the prompt tuning on a cloud-based Large Language Model (LLM) feasible. Adapting federated learning to BDPL could further enhance prompt tuning performance by leveraging data from diverse sources. However, all previous research on federated black-box prompt tuning had neglected the substantial query cost associated with the cloud-based LLM service. To address this gap, we conducted a theoretical analysis of query efficiency within the context of federated black-box prompt tuning. Our findings revealed that degrading FedAvg to activate only one client per round, a strategy we called \textit{FedOne}, enabled optimal query efficiency in federated black-box prompt learning. Building on this insight, we proposed the FedOne framework, a federated black-box discrete prompt learning method designed to maximize query efficiency when interacting with cloud-based LLMs. We conducted numerical experiments on various aspects of our framework, demonstrating a significant improvement in query efficiency, which aligns with our theoretical results.
* Published in Proceedings of the 42nd International Conference on Machine Learning
Event-Driven Online Vertical Federated Learning
Jun 17, 2025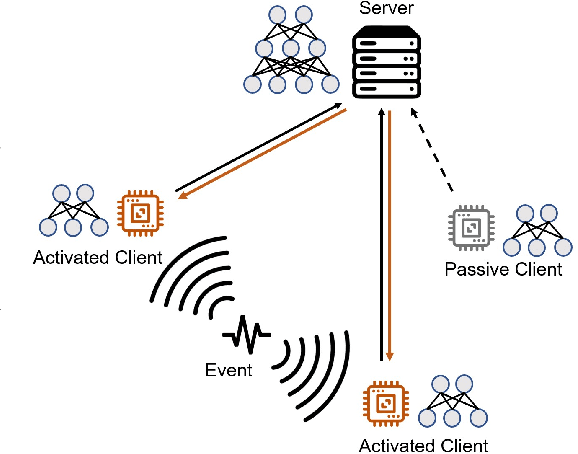



Online learning is more adaptable to real-world scenarios in Vertical Federated Learning (VFL) compared to offline learning. However, integrating online learning into VFL presents challenges due to the unique nature of VFL, where clients possess non-intersecting feature sets for the same sample. In real-world scenarios, the clients may not receive data streaming for the disjoint features for the same entity synchronously. Instead, the data are typically generated by an \emph{event} relevant to only a subset of clients. We are the first to identify these challenges in online VFL, which have been overlooked by previous research. To address these challenges, we proposed an event-driven online VFL framework. In this framework, only a subset of clients were activated during each event, while the remaining clients passively collaborated in the learning process. Furthermore, we incorporated \emph{dynamic local regret (DLR)} into VFL to address the challenges posed by online learning problems with non-convex models within a non-stationary environment. We conducted a comprehensive regret analysis of our proposed framework, specifically examining the DLR under non-convex conditions with event-driven online VFL. Extensive experiments demonstrated that our proposed framework was more stable than the existing online VFL framework under non-stationary data conditions while also significantly reducing communication and computation costs.
* Published as a conference paper at ICLR 2025
Secure and Fast Asynchronous Vertical Federated Learning via Cascaded Hybrid Optimization
Jun 29, 2023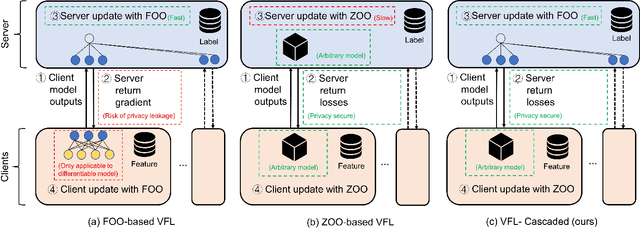
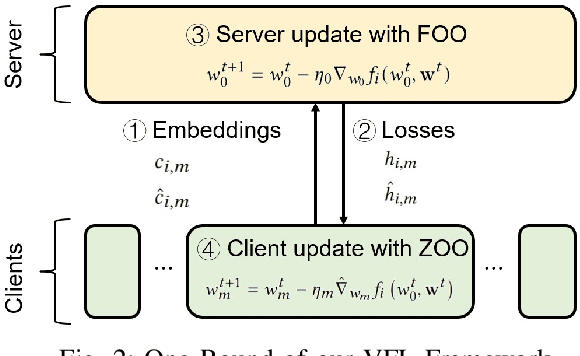
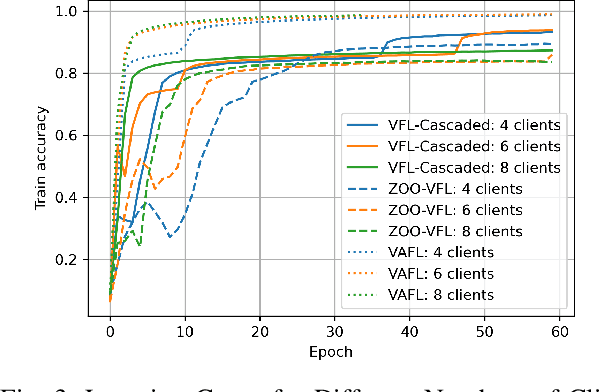
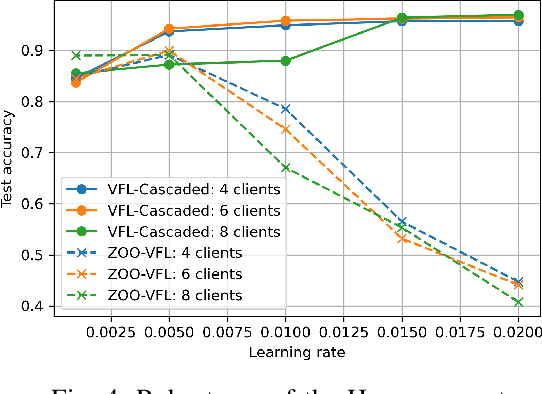
Vertical Federated Learning (VFL) attracts increasing attention because it empowers multiple parties to jointly train a privacy-preserving model over vertically partitioned data. Recent research has shown that applying zeroth-order optimization (ZOO) has many advantages in building a practical VFL algorithm. However, a vital problem with the ZOO-based VFL is its slow convergence rate, which limits its application in handling modern large models. To address this problem, we propose a cascaded hybrid optimization method in VFL. In this method, the downstream models (clients) are trained with ZOO to protect privacy and ensure that no internal information is shared. Meanwhile, the upstream model (server) is updated with first-order optimization (FOO) locally, which significantly improves the convergence rate, making it feasible to train the large models without compromising privacy and security. We theoretically prove that our VFL framework converges faster than the ZOO-based VFL, as the convergence of our framework is not limited by the size of the server model, making it effective for training large models with the major part on the server. Extensive experiments demonstrate that our method achieves faster convergence than the ZOO-based VFL framework, while maintaining an equivalent level of privacy protection. Moreover, we show that the convergence of our VFL is comparable to the unsafe FOO-based VFL baseline. Additionally, we demonstrate that our method makes the training of a large model feasible.