 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProject Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
AI Can Learn Scientific Taste
Mar 15, 2026Great scientists have strong judgement and foresight, closely tied to what we call scientific taste. Here, we use the term to refer to the capacity to judge and propose research ideas with high potential impact. However, most relative research focuses on improving an AI scientist's executive capability, while enhancing an AI's scientific taste remains underexplored. In this work, we propose Reinforcement Learning from Community Feedback (RLCF), a training paradigm that uses large-scale community signals as supervision, and formulate scientific taste learning as a preference modeling and alignment problem. For preference modeling, we train Scientific Judge on 700K field- and time-matched pairs of high- vs. low-citation papers to judge ideas. For preference alignment, using Scientific Judge as a reward model, we train a policy model, Scientific Thinker, to propose research ideas with high potential impact. Experiments show Scientific Judge outperforms SOTA LLMs (e.g., GPT-5.2, Gemini 3 Pro) and generalizes to future-year test, unseen fields, and peer-review preference. Furthermore, Scientific Thinker proposes research ideas with higher potential impact than baselines. Our findings show that AI can learn scientific taste, marking a key step toward reaching human-level AI scientists.
Improving Medical Reasoning with Curriculum-Aware Reinforcement Learning
May 25, 2025



Recent advances in reinforcement learning with verifiable, rule-based rewards have greatly enhanced the reasoning capabilities and out-of-distribution generalization of VLMs/LLMs, obviating the need for manually crafted reasoning chains. Despite these promising developments in the general domain, their translation to medical imaging remains limited. Current medical reinforcement fine-tuning (RFT) methods predominantly focus on close-ended VQA, thereby restricting the model's ability to engage in world knowledge retrieval and flexible task adaptation. More critically, these methods fall short of addressing the critical clinical demand for open-ended, reasoning-intensive decision-making. To bridge this gap, we introduce \textbf{MedCCO}, the first multimodal reinforcement learning framework tailored for medical VQA that unifies close-ended and open-ended data within a curriculum-driven RFT paradigm. Specifically, MedCCO is initially fine-tuned on a diverse set of close-ended medical VQA tasks to establish domain-grounded reasoning capabilities, and is then progressively adapted to open-ended tasks to foster deeper knowledge enhancement and clinical interpretability. We validate MedCCO across eight challenging medical VQA benchmarks, spanning both close-ended and open-ended settings. Experimental results show that MedCCO consistently enhances performance and generalization, achieving a 11.4\% accuracy gain across three in-domain tasks, and a 5.7\% improvement on five out-of-domain benchmarks. These findings highlight the promise of curriculum-guided RL in advancing robust, clinically-relevant reasoning in medical multimodal language models.
LSSInst: Improving Geometric Modeling in LSS-Based BEV Perception with Instance Representation
Nov 19, 2024



With the attention gained by camera-only 3D object detection in autonomous driving, methods based on Bird-Eye-View (BEV) representation especially derived from the forward view transformation paradigm, i.e., lift-splat-shoot (LSS), have recently seen significant progress. The BEV representation formulated by the frustum based on depth distribution prediction is ideal for learning the road structure and scene layout from multi-view images. However, to retain computational efficiency, the compressed BEV representation such as in resolution and axis is inevitably weak in retaining the individual geometric details, undermining the methodological generality and applicability. With this in mind, to compensate for the missing details and utilize multi-view geometry constraints, we propose LSSInst, a two-stage object detector incorporating BEV and instance representations in tandem. The proposed detector exploits fine-grained pixel-level features that can be flexibly integrated into existing LSS-based BEV networks. Having said that, due to the inherent gap between two representation spaces, we design the instance adaptor for the BEV-to-instance semantic coherence rather than pass the proposal naively. Extensive experiments demonstrated that our proposed framework is of excellent generalization ability and performance, which boosts the performances of modern LSS-based BEV perception methods without bells and whistles and outperforms current LSS-based state-of-the-art works on the large-scale nuScenes benchmark.
CrossFusion: Interleaving Cross-modal Complementation for Noise-resistant 3D Object Detection
Apr 19, 2023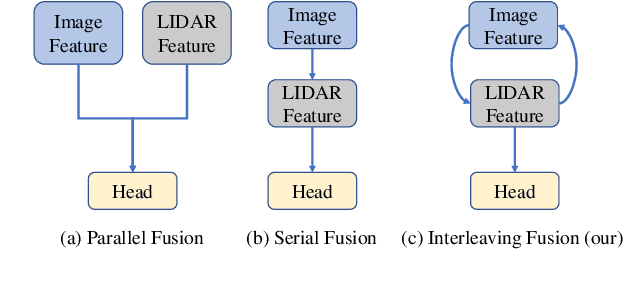
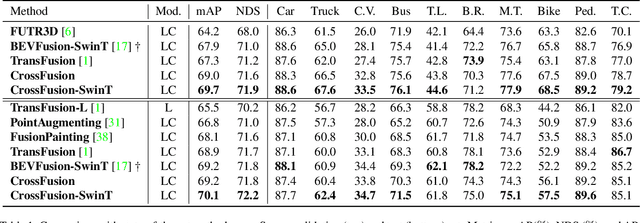
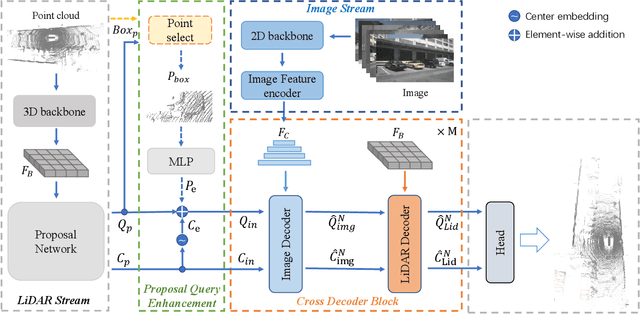

The combination of LiDAR and camera modalities is proven to be necessary and typical for 3D object detection according to recent studies. Existing fusion strategies tend to overly rely on the LiDAR modal in essence, which exploits the abundant semantics from the camera sensor insufficiently. However, existing methods cannot rely on information from other modalities because the corruption of LiDAR features results in a large domain gap. Following this, we propose CrossFusion, a more robust and noise-resistant scheme that makes full use of the camera and LiDAR features with the designed cross-modal complementation strategy. Extensive experiments we conducted show that our method not only outperforms the state-of-the-art methods under the setting without introducing an extra depth estimation network but also demonstrates our model's noise resistance without re-training for the specific malfunction scenarios by increasing 5.2\% mAP and 2.4\% NDS.
Toward Clinically Assisted Colorectal Polyp Recognition via Structured Cross-modal Representation Consistency
Jun 24, 2022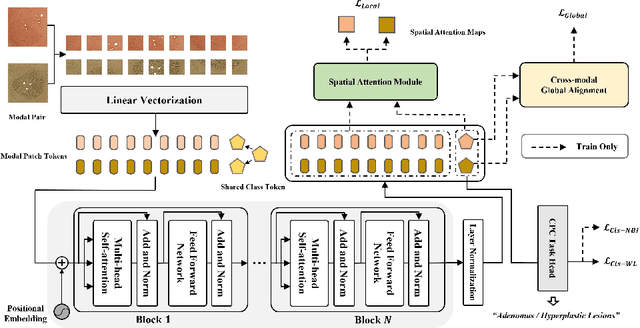
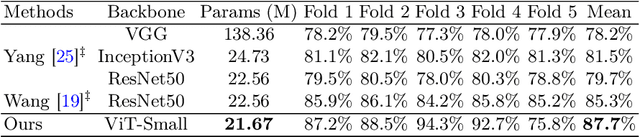
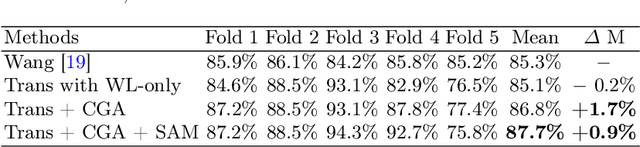
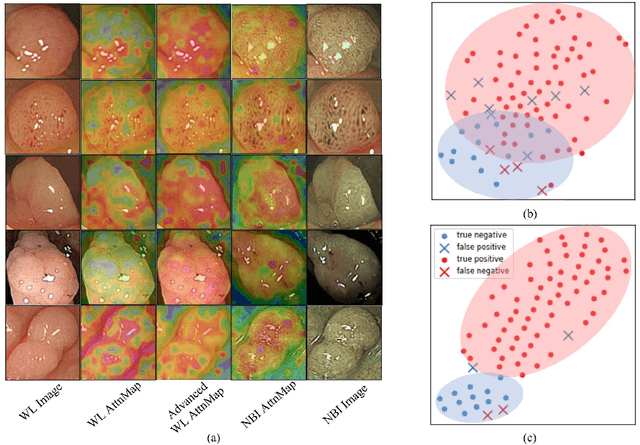
The colorectal polyps classification is a critical clinical examination. To improve the classification accuracy, most computer-aided diagnosis algorithms recognize colorectal polyps by adopting Narrow-Band Imaging (NBI). However, the NBI usually suffers from missing utilization in real clinic scenarios since the acquisition of this specific image requires manual switching of the light mode when polyps have been detected by using White-Light (WL) images. To avoid the above situation, we propose a novel method to directly achieve accurate white-light colonoscopy image classification by conducting structured cross-modal representation consistency. In practice, a pair of multi-modal images, i.e. NBI and WL, are fed into a shared Transformer to extract hierarchical feature representations. Then a novel designed Spatial Attention Module (SAM) is adopted to calculate the similarities between the class token and patch tokens %from multi-levels for a specific modality image. By aligning the class tokens and spatial attention maps of paired NBI and WL images at different levels, the Transformer achieves the ability to keep both global and local representation consistency for the above two modalities. Extensive experimental results illustrate the proposed method outperforms the recent studies with a margin, realizing multi-modal prediction with a single Transformer while greatly improving the classification accuracy when only with WL images.