 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Medical Reasoning with Curriculum-Aware Reinforcement Learning
May 25, 2025



Recent advances in reinforcement learning with verifiable, rule-based rewards have greatly enhanced the reasoning capabilities and out-of-distribution generalization of VLMs/LLMs, obviating the need for manually crafted reasoning chains. Despite these promising developments in the general domain, their translation to medical imaging remains limited. Current medical reinforcement fine-tuning (RFT) methods predominantly focus on close-ended VQA, thereby restricting the model's ability to engage in world knowledge retrieval and flexible task adaptation. More critically, these methods fall short of addressing the critical clinical demand for open-ended, reasoning-intensive decision-making. To bridge this gap, we introduce \textbf{MedCCO}, the first multimodal reinforcement learning framework tailored for medical VQA that unifies close-ended and open-ended data within a curriculum-driven RFT paradigm. Specifically, MedCCO is initially fine-tuned on a diverse set of close-ended medical VQA tasks to establish domain-grounded reasoning capabilities, and is then progressively adapted to open-ended tasks to foster deeper knowledge enhancement and clinical interpretability. We validate MedCCO across eight challenging medical VQA benchmarks, spanning both close-ended and open-ended settings. Experimental results show that MedCCO consistently enhances performance and generalization, achieving a 11.4\% accuracy gain across three in-domain tasks, and a 5.7\% improvement on five out-of-domain benchmarks. These findings highlight the promise of curriculum-guided RL in advancing robust, clinically-relevant reasoning in medical multimodal language models.
Cost-effective Instruction Learning for Pathology Vision and Language Analysis
Jul 25, 2024
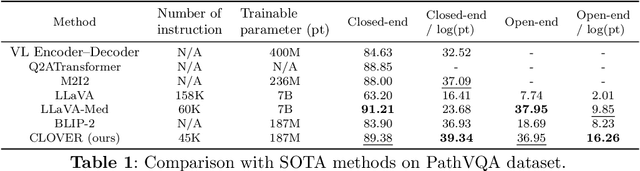
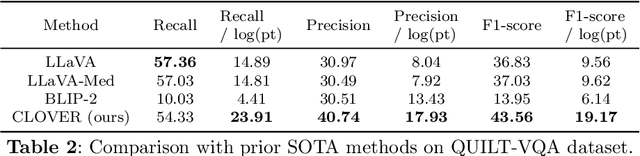

The advent of vision-language models fosters the interactive conversations between AI-enabled models and humans. Yet applying these models into clinics must deal with daunting challenges around large-scale training data, financial, and computational resources. Here we propose a cost-effective instruction learning framework for conversational pathology named as CLOVER. CLOVER only trains a lightweight module and uses instruction tuning while freezing the parameters of the large language model. Instead of using costly GPT-4, we propose well-designed prompts on GPT-3.5 for building generation-based instructions, emphasizing the utility of pathological knowledge derived from the Internet source. To augment the use of instructions, we construct a high-quality set of template-based instructions in the context of digital pathology. From two benchmark datasets, our findings reveal the strength of hybrid-form instructions in the visual question-answer in pathology. Extensive results show the cost-effectiveness of CLOVER in answering both open-ended and closed-ended questions, where CLOVER outperforms strong baselines that possess 37 times more training parameters and use instruction data generated from GPT-4. Through the instruction tuning, CLOVER exhibits robustness of few-shot learning in the external clinical dataset. These findings demonstrate that cost-effective modeling of CLOVER could accelerate the adoption of rapid conversational applications in the landscape of digital pathology.