 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperience Makes Skillful: Enabling Generalizable Medical Agent Reasoning via Self-Evolving Skill Memory
Jun 08, 2026Medical agent systems are increasingly expected to support interactive clinical decision making rather than only static question answering. In such settings, effective agents must reuse prior experience across evolving cases, yet existing memory mechanisms often retain raw historical traces that are redundant, noisy, and difficult to govern. More importantly, they rarely distinguish which memories are truly useful for future reasoning. This limits their ability to accumulate compact and reliable experience for long-horizon clinical reasoning. To close this gap, we propose SkeMex, a post-deployment self-evolution framework that improves medical agents through a skill-based memory without updating model weights. SkeMex distills informative interaction trajectories into structured skills that encode reusable procedural knowledge, and organizes them into a multi-branch repository spanning general, task-specific, and action-level experience. To determine which memories should be reused and retained, SkeMex estimates context-dependent utility from environment feedback and uses it to guide value-aware retrieval and repository governance. A closed-loop ``Read--Write--Assess--Govern" lifecycle further supports continual evolution by writing new skills, updating utilities, promoting useful memories, and removing harmful entries. Experiments across diverse clinical tasks show that SkeMex consistently outperforms representative memory-based agents in both offline and online settings. It also generalizes across model backbones and supports transferable skill memory. All data and code will be released publicly.
Project Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
InternAgent-1.5: A Unified Agentic Framework for Long-Horizon Autonomous Scientific Discovery
Feb 09, 2026We introduce InternAgent-1.5, a unified system designed for end-to-end scientific discovery across computational and empirical domains. The system is built on a structured architecture composed of three coordinated subsystems for generation, verification, and evolution. These subsystems are supported by foundational capabilities for deep research, solution optimization, and long horizon memory. The architecture allows InternAgent-1.5 to operate continuously across extended discovery cycles while maintaining coherent and improving behavior. It also enables the system to coordinate computational modeling and laboratory experimentation within a single unified system. We evaluate InternAgent-1.5 on scientific reasoning benchmarks such as GAIA, HLE, GPQA, and FrontierScience, and the system achieves leading performance that demonstrates strong foundational capabilities. Beyond these benchmarks, we further assess two categories of discovery tasks. In algorithm discovery tasks, InternAgent-1.5 autonomously designs competitive methods for core machine learning problems. In empirical discovery tasks, it executes complete computational or wet lab experiments and produces scientific findings in earth, life, biological, and physical domains. Overall, these results show that InternAgent-1.5 provides a general and scalable framework for autonomous scientific discovery.
PathOrchestra: A Comprehensive Foundation Model for Computational Pathology with Over 100 Diverse Clinical-Grade Tasks
Mar 31, 2025The complexity and variability inherent in high-resolution pathological images present significant challenges in computational pathology. While pathology foundation models leveraging AI have catalyzed transformative advancements, their development demands large-scale datasets, considerable storage capacity, and substantial computational resources. Furthermore, ensuring their clinical applicability and generalizability requires rigorous validation across a broad spectrum of clinical tasks. Here, we present PathOrchestra, a versatile pathology foundation model trained via self-supervised learning on a dataset comprising 300K pathological slides from 20 tissue and organ types across multiple centers. The model was rigorously evaluated on 112 clinical tasks using a combination of 61 private and 51 public datasets. These tasks encompass digital slide preprocessing, pan-cancer classification, lesion identification, multi-cancer subtype classification, biomarker assessment, gene expression prediction, and the generation of structured reports. PathOrchestra demonstrated exceptional performance across 27,755 WSIs and 9,415,729 ROIs, achieving over 0.950 accuracy in 47 tasks, including pan-cancer classification across various organs, lymphoma subtype diagnosis, and bladder cancer screening. Notably, it is the first model to generate structured reports for high-incidence colorectal cancer and diagnostically complex lymphoma-areas that are infrequently addressed by foundational models but hold immense clinical potential. Overall, PathOrchestra exemplifies the feasibility and efficacy of a large-scale, self-supervised pathology foundation model, validated across a broad range of clinical-grade tasks. Its high accuracy and reduced reliance on extensive data annotation underline its potential for clinical integration, offering a pathway toward more efficient and high-quality medical services.
End-to-end Triple-domain PET Enhancement: A Hybrid Denoising-and-reconstruction Framework for Reconstructing Standard-dose PET Images from Low-dose PET Sinograms
Dec 04, 2024


As a sensitive functional imaging technique, positron emission tomography (PET) plays a critical role in early disease diagnosis. However, obtaining a high-quality PET image requires injecting a sufficient dose (standard dose) of radionuclides into the body, which inevitably poses radiation hazards to patients. To mitigate radiation hazards, the reconstruction of standard-dose PET (SPET) from low-dose PET (LPET) is desired. According to imaging theory, PET reconstruction process involves multiple domains (e.g., projection domain and image domain), and a significant portion of the difference between SPET and LPET arises from variations in the noise levels introduced during the sampling of raw data as sinograms. In light of these two facts, we propose an end-to-end TriPle-domain LPET EnhancemenT (TriPLET) framework, by leveraging the advantages of a hybrid denoising-and-reconstruction process and a triple-domain representation (i.e., sinograms, frequency spectrum maps, and images) to reconstruct SPET images from LPET sinograms. Specifically, TriPLET consists of three sequentially coupled components including 1) a Transformer-assisted denoising network that denoises the inputted LPET sinograms in the projection domain, 2) a discrete-wavelet-transform-based reconstruction network that further reconstructs SPET from LPET in the wavelet domain, and 3) a pair-based adversarial network that evaluates the reconstructed SPET images in the image domain. Extensive experiments on the real PET dataset demonstrate that our proposed TriPLET can reconstruct SPET images with the highest similarity and signal-to-noise ratio to real data, compared with state-of-the-art methods.
BrainMVP: Multi-modal Vision Pre-training for Brain Image Analysis using Multi-parametric MRI
Oct 14, 2024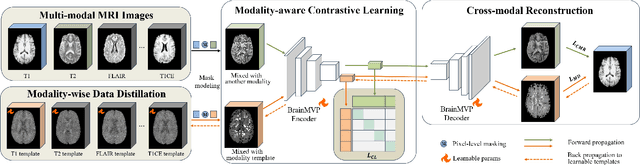
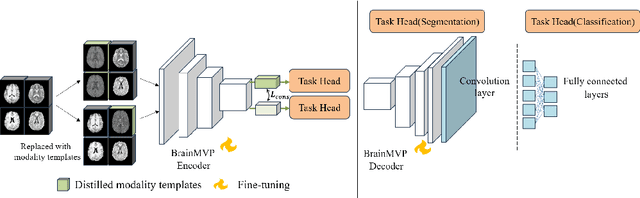
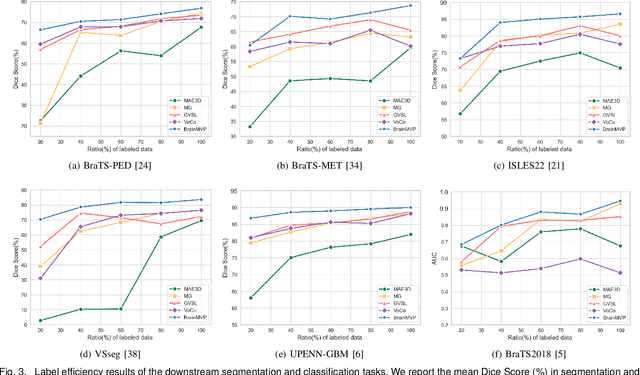
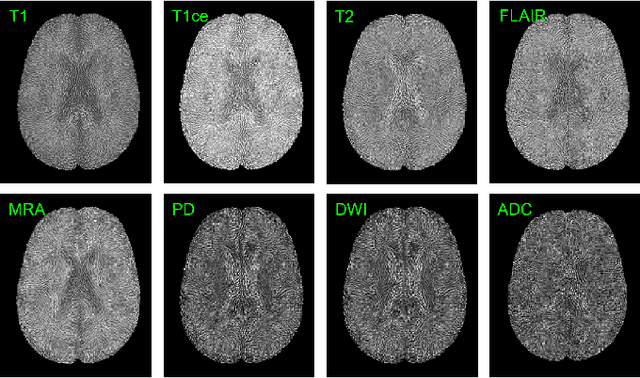
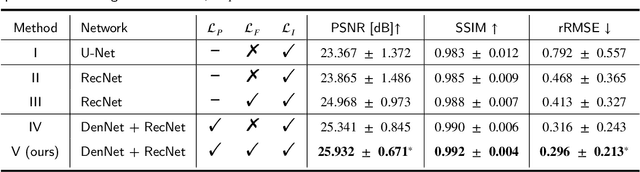
Accurate diagnosis of brain abnormalities is greatly enhanced by the inclusion of complementary multi-parametric MRI imaging data. There is significant potential to develop a universal pre-training model that can be quickly adapted for image modalities and various clinical scenarios. However, current models often rely on uni-modal image data, neglecting the cross-modal correlations among different image modalities or struggling to scale up pre-training in the presence of missing modality data. In this paper, we propose BrainMVP, a multi-modal vision pre-training framework for brain image analysis using multi-parametric MRI scans. First, we collect 16,022 brain MRI scans (over 2.4 million images), encompassing eight MRI modalities sourced from a diverse range of centers and devices. Then, a novel pre-training paradigm is proposed for the multi-modal MRI data, addressing the issue of missing modalities and achieving multi-modal information fusion. Cross-modal reconstruction is explored to learn distinctive brain image embeddings and efficient modality fusion capabilities. A modality-wise data distillation module is proposed to extract the essence representation of each MR image modality for both the pre-training and downstream application purposes. Furthermore, we introduce a modality-aware contrastive learning module to enhance the cross-modality association within a study. Extensive experiments on downstream tasks demonstrate superior performance compared to state-of-the-art pre-training methods in the medical domain, with Dice Score improvement of 0.28%-14.47% across six segmentation benchmarks and a consistent accuracy improvement of 0.65%-18.07% in four individual classification tasks.
CIResDiff: A Clinically-Informed Residual Diffusion Model for Predicting Idiopathic Pulmonary Fibrosis Progression
Aug 05, 2024


The progression of Idiopathic Pulmonary Fibrosis (IPF) significantly correlates with higher patient mortality rates. Early detection of IPF progression is critical for initiating timely treatment, which can effectively slow down the advancement of the disease. However, the current clinical criteria define disease progression requiring two CT scans with a one-year interval, presenting a dilemma: a disease progression is identified only after the disease has already progressed. To this end, in this paper, we develop a novel diffusion model to accurately predict the progression of IPF by generating patient's follow-up CT scan from the initial CT scan. Specifically, from the clinical prior knowledge, we tailor improvements to the traditional diffusion model and propose a Clinically-Informed Residual Diffusion model, called CIResDiff. The key innovations of CIResDiff include 1) performing the target region pre-registration to align the lung regions of two CT scans at different time points for reducing the generation difficulty, 2) adopting the residual diffusion instead of traditional diffusion to enable the model focus more on differences (i.e., lesions) between the two CT scans rather than the largely identical anatomical content, and 3) designing the clinically-informed process based on CLIP technology to integrate lung function information which is highly relevant to diagnosis into the reverse process for assisting generation. Extensive experiments on clinical data demonstrate that our approach can outperform state-of-the-art methods and effectively predict the progression of IPF.
A dual-task mutual learning framework for predicting post-thrombectomy cerebral hemorrhage
Aug 01, 2024Ischemic stroke is a severe condition caused by the blockage of brain blood vessels, and can lead to the death of brain tissue due to oxygen deprivation. Thrombectomy has become a common treatment choice for ischemic stroke due to its immediate effectiveness. But, it carries the risk of postoperative cerebral hemorrhage. Clinically, multiple CT scans within 0-72 hours post-surgery are used to monitor for hemorrhage. However, this approach exposes radiation dose to patients, and may delay the detection of cerebral hemorrhage. To address this dilemma, we propose a novel prediction framework for measuring postoperative cerebral hemorrhage using only the patient's initial CT scan. Specifically, we introduce a dual-task mutual learning framework to takes the initial CT scan as input and simultaneously estimates both the follow-up CT scan and prognostic label to predict the occurrence of postoperative cerebral hemorrhage. Our proposed framework incorporates two attention mechanisms, i.e., self-attention and interactive attention. Specifically, the self-attention mechanism allows the model to focus more on high-density areas in the image, which are critical for diagnosis (i.e., potential hemorrhage areas). The interactive attention mechanism further models the dependencies between the interrelated generation and classification tasks, enabling both tasks to perform better than the case when conducted individually. Validated on clinical data, our method can generate follow-up CT scans better than state-of-the-art methods, and achieves an accuracy of 86.37% in predicting follow-up prognostic labels. Thus, our work thus contributes to the timely screening of post-thrombectomy cerebral hemorrhage, and could significantly reform the clinical process of thrombectomy and other similar operations related to stroke.
A Progressive Single-Modality to Multi-Modality Classification Framework for Alzheimer's Disease Sub-type Diagnosis
Jul 26, 2024
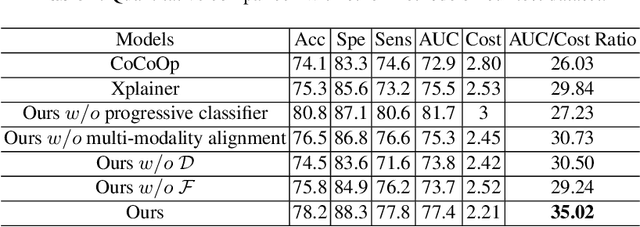

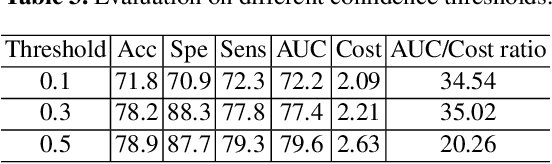
The current clinical diagnosis framework of Alzheimer's disease (AD) involves multiple modalities acquired from multiple diagnosis stages, each with distinct usage and cost. Previous AD diagnosis research has predominantly focused on how to directly fuse multiple modalities for an end-to-end one-stage diagnosis, which practically requires a high cost in data acquisition. Moreover, a significant part of these methods diagnose AD without considering clinical guideline and cannot offer accurate sub-type diagnosis. In this paper, by exploring inter-correlation among multiple modalities, we propose a novel progressive AD sub-type diagnosis framework, aiming to give diagnosis results based on easier-to-access modalities in earlier low-cost stages, instead of modalities from all stages. Specifically, first, we design 1) a text disentanglement network for better processing tabular data collected in the initial stage, and 2) a modality fusion module for fusing multi-modality features separately. Second, we align features from modalities acquired in earlier low-cost stage(s) with later high-cost stage(s) to give accurate diagnosis without actual modality acquisition in later-stage(s) for saving cost. Furthermore, we follow the clinical guideline to align features at each stage for achieving sub-type diagnosis. Third, we leverage a progressive classifier that can progressively include additional acquired modalities (if needed) for diagnosis, to achieve the balance between diagnosis cost and diagnosis performance. We evaluate our proposed framework on large diverse public and in-home datasets (8280 in total) and achieve superior performance over state-of-the-art methods. Our codes will be released after the acceptance.
Cost-effective Instruction Learning for Pathology Vision and Language Analysis
Jul 25, 2024
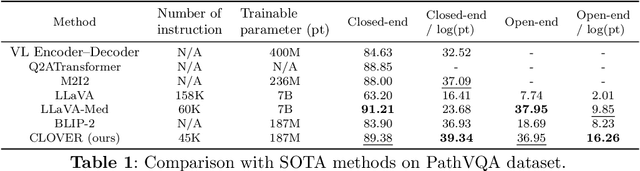
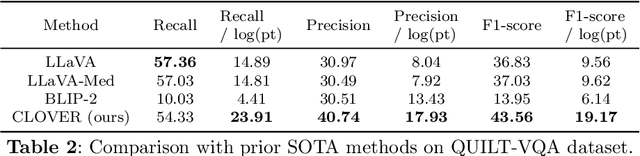

The advent of vision-language models fosters the interactive conversations between AI-enabled models and humans. Yet applying these models into clinics must deal with daunting challenges around large-scale training data, financial, and computational resources. Here we propose a cost-effective instruction learning framework for conversational pathology named as CLOVER. CLOVER only trains a lightweight module and uses instruction tuning while freezing the parameters of the large language model. Instead of using costly GPT-4, we propose well-designed prompts on GPT-3.5 for building generation-based instructions, emphasizing the utility of pathological knowledge derived from the Internet source. To augment the use of instructions, we construct a high-quality set of template-based instructions in the context of digital pathology. From two benchmark datasets, our findings reveal the strength of hybrid-form instructions in the visual question-answer in pathology. Extensive results show the cost-effectiveness of CLOVER in answering both open-ended and closed-ended questions, where CLOVER outperforms strong baselines that possess 37 times more training parameters and use instruction data generated from GPT-4. Through the instruction tuning, CLOVER exhibits robustness of few-shot learning in the external clinical dataset. These findings demonstrate that cost-effective modeling of CLOVER could accelerate the adoption of rapid conversational applications in the landscape of digital pathology.