 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Generalizable Robotic Data Flywheel: High-Dimensional Factorization and Composition
Mar 26, 2026The lack of sufficiently diverse data, coupled with limited data efficiency, remains a major bottleneck for generalist robotic models, yet systematic strategies for collecting and curating such data are not fully explored. Task diversity arises from implicit factors that are sparsely distributed across multiple dimensions and are difficult to define explicitly. To address this challenge, we propose F-ACIL, a heuristic factor-aware compositional iterative learning framework that enables structured data factorization and promotes compositional generalization. F-ACIL decomposes the data distribution into structured factor spaces such as object, action, and environment. Based on the factorized formulation, we develop a factor-wise data collection and an iterative training paradigm that promotes compositional generalization over the high-dimensional factor space, leading to more effective utilization of real-world robotic demonstrations. With extensive real-world experiments, we show that F-ACIL can achieve more than 45% performance gains with 5-10$\times$ fewer demonstrations comparing to that of which without the strategy. The results suggest that structured factorization offers a practical pathway toward efficient compositional generalization in real-world robotic learning. We believe F-ACIL can inspire more systematic research on building generalizable robotic data flywheel strategies. More demonstrations can be found at: https://f-acil.github.io/
Toward a Multi-View Brain Network Foundation Model: Cross-View Consistency Learning Across Arbitrary Atlases
Mar 20, 2026Brain network analysis provides an interpretable framework for characterizing brain organization and has been widely used for neurological disorder identification. Recent advances in self-supervised learning have motivated the development of brain network foundation models. However, existing approaches are often limited by atlas dependency, insufficient exploitation of multiple network views, and weak incorporation of anatomical priors. In this work, we propose MV-BrainFM, a multi-view brain network foundation model designed to learn generalizable and scalable representations from brain networks constructed with arbitrary atlases. MV-BrainFM explicitly incorporates anatomical distance information into Transformer-based modeling to guide inter-regional interactions, and introduces an unsupervised cross-view consistency learning strategy to align representations from multiple atlases of the same subject in a shared latent space. By jointly enforcing within-view robustness and cross-view alignment during pretraining, the model effectively captures complementary information across heterogeneous network views while remaining atlas-aware. In addition, MV-BrainFM adopts a unified multi-view pretraining paradigm that enables simultaneous learning from multiple datasets and atlases, significantly improving computational efficiency compared to conventional sequential training strategies. The proposed framework also demonstrates strong scalability, consistently benefiting from increasing data diversity while maintaining stable performance across unseen atlas configurations. Extensive experiments on more than 20K subjects from 17 fMRI datasets show that MV-BrainFM consistently outperforms 14 existing brain network foundation models and task-specific baselines under both single-atlas and multi-atlas settings.
World Guidance: World Modeling in Condition Space for Action Generation
Feb 25, 2026Leveraging future observation modeling to facilitate action generation presents a promising avenue for enhancing the capabilities of Vision-Language-Action (VLA) models. However, existing approaches struggle to strike a balance between maintaining efficient, predictable future representations and preserving sufficient fine-grained information to guide precise action generation. To address this limitation, we propose WoG (World Guidance), a framework that maps future observations into compact conditions by injecting them into the action inference pipeline. The VLA is then trained to simultaneously predict these compressed conditions alongside future actions, thereby achieving effective world modeling within the condition space for action inference. We demonstrate that modeling and predicting this condition space not only facilitates fine-grained action generation but also exhibits superior generalization capabilities. Moreover, it learns effectively from substantial human manipulation videos. Extensive experiments across both simulation and real-world environments validate that our method significantly outperforms existing methods based on future prediction. Project page is available at: https://selen-suyue.github.io/WoGNet/
GR-Dexter Technical Report
Dec 30, 2025Vision-language-action (VLA) models have enabled language-conditioned, long-horizon robot manipulation, but most existing systems are limited to grippers. Scaling VLA policies to bimanual robots with high degree-of-freedom (DoF) dexterous hands remains challenging due to the expanded action space, frequent hand-object occlusions, and the cost of collecting real-robot data. We present GR-Dexter, a holistic hardware-model-data framework for VLA-based generalist manipulation on a bimanual dexterous-hand robot. Our approach combines the design of a compact 21-DoF robotic hand, an intuitive bimanual teleoperation system for real-robot data collection, and a training recipe that leverages teleoperated robot trajectories together with large-scale vision-language and carefully curated cross-embodiment datasets. Across real-world evaluations spanning long-horizon everyday manipulation and generalizable pick-and-place, GR-Dexter achieves strong in-domain performance and improved robustness to unseen objects and unseen instructions. We hope GR-Dexter serves as a practical step toward generalist dexterous-hand robotic manipulation.
AInsteinBench: Benchmarking Coding Agents on Scientific Repositories
Dec 24, 2025We introduce AInsteinBench, a large-scale benchmark for evaluating whether large language model (LLM) agents can operate as scientific computing development agents within real research software ecosystems. Unlike existing scientific reasoning benchmarks which focus on conceptual knowledge, or software engineering benchmarks that emphasize generic feature implementation and issue resolving, AInsteinBench evaluates models in end-to-end scientific development settings grounded in production-grade scientific repositories. The benchmark consists of tasks derived from maintainer-authored pull requests across six widely used scientific codebases, spanning quantum chemistry, quantum computing, molecular dynamics, numerical relativity, fluid dynamics, and cheminformatics. All benchmark tasks are carefully curated through multi-stage filtering and expert review to ensure scientific challenge, adequate test coverage, and well-calibrated difficulty. By leveraging evaluation in executable environments, scientifically meaningful failure modes, and test-driven verification, AInsteinBench measures a model's ability to move beyond surface-level code generation toward the core competencies required for computational scientific research.
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
Oct 08, 2024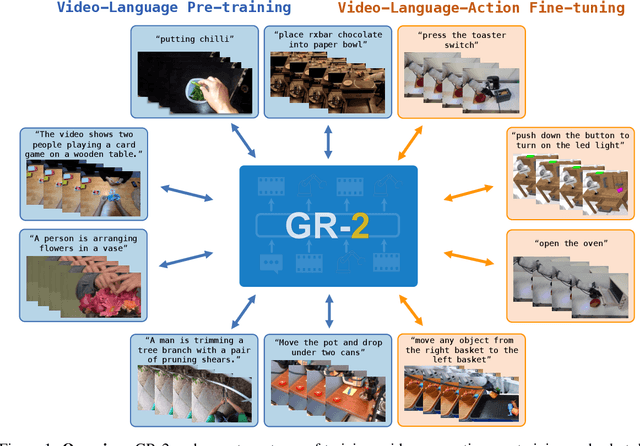
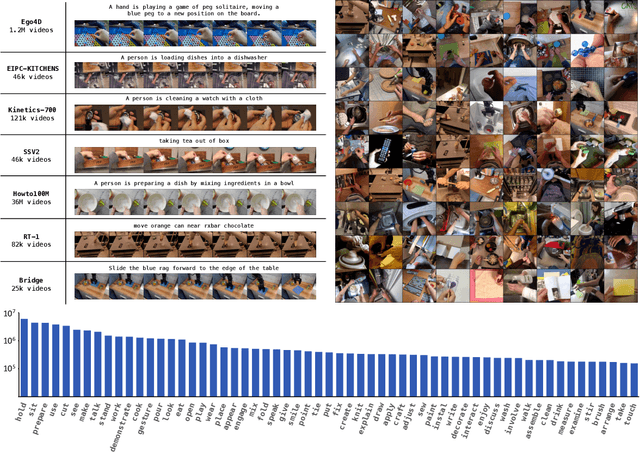


We present GR-2, a state-of-the-art generalist robot agent for versatile and generalizable robot manipulation. GR-2 is first pre-trained on a vast number of Internet videos to capture the dynamics of the world. This large-scale pre-training, involving 38 million video clips and over 50 billion tokens, equips GR-2 with the ability to generalize across a wide range of robotic tasks and environments during subsequent policy learning. Following this, GR-2 is fine-tuned for both video generation and action prediction using robot trajectories. It exhibits impressive multi-task learning capabilities, achieving an average success rate of 97.7% across more than 100 tasks. Moreover, GR-2 demonstrates exceptional generalization to new, previously unseen scenarios, including novel backgrounds, environments, objects, and tasks. Notably, GR-2 scales effectively with model size, underscoring its potential for continued growth and application. Project page: \url{https://gr2-manipulation.github.io}.
A Progressive Single-Modality to Multi-Modality Classification Framework for Alzheimer's Disease Sub-type Diagnosis
Jul 26, 2024
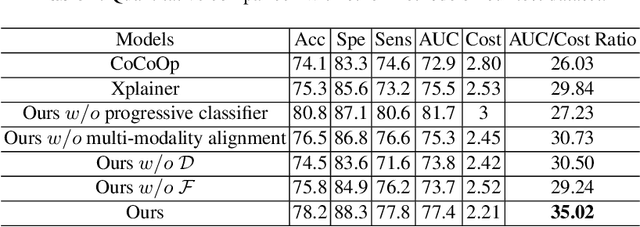

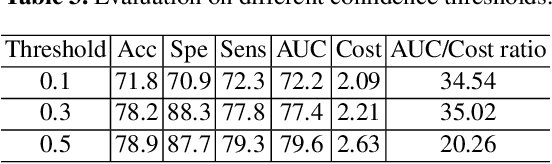
The current clinical diagnosis framework of Alzheimer's disease (AD) involves multiple modalities acquired from multiple diagnosis stages, each with distinct usage and cost. Previous AD diagnosis research has predominantly focused on how to directly fuse multiple modalities for an end-to-end one-stage diagnosis, which practically requires a high cost in data acquisition. Moreover, a significant part of these methods diagnose AD without considering clinical guideline and cannot offer accurate sub-type diagnosis. In this paper, by exploring inter-correlation among multiple modalities, we propose a novel progressive AD sub-type diagnosis framework, aiming to give diagnosis results based on easier-to-access modalities in earlier low-cost stages, instead of modalities from all stages. Specifically, first, we design 1) a text disentanglement network for better processing tabular data collected in the initial stage, and 2) a modality fusion module for fusing multi-modality features separately. Second, we align features from modalities acquired in earlier low-cost stage(s) with later high-cost stage(s) to give accurate diagnosis without actual modality acquisition in later-stage(s) for saving cost. Furthermore, we follow the clinical guideline to align features at each stage for achieving sub-type diagnosis. Third, we leverage a progressive classifier that can progressively include additional acquired modalities (if needed) for diagnosis, to achieve the balance between diagnosis cost and diagnosis performance. We evaluate our proposed framework on large diverse public and in-home datasets (8280 in total) and achieve superior performance over state-of-the-art methods. Our codes will be released after the acceptance.
Potential of Multimodal Large Language Models for Data Mining of Medical Images and Free-text Reports
Jul 08, 2024



Medical images and radiology reports are crucial for diagnosing medical conditions, highlighting the importance of quantitative analysis for clinical decision-making. However, the diversity and cross-source heterogeneity of these data challenge the generalizability of current data-mining methods. Multimodal large language models (MLLMs) have recently transformed many domains, significantly affecting the medical field. Notably, Gemini-Vision-series (Gemini) and GPT-4-series (GPT-4) models have epitomized a paradigm shift in Artificial General Intelligence (AGI) for computer vision, showcasing their potential in the biomedical domain. In this study, we evaluated the performance of the Gemini, GPT-4, and 4 popular large models for an exhaustive evaluation across 14 medical imaging datasets, including 5 medical imaging categories (dermatology, radiology, dentistry, ophthalmology, and endoscopy), and 3 radiology report datasets. The investigated tasks encompass disease classification, lesion segmentation, anatomical localization, disease diagnosis, report generation, and lesion detection. Our experimental results demonstrated that Gemini-series models excelled in report generation and lesion detection but faces challenges in disease classification and anatomical localization. Conversely, GPT-series models exhibited proficiency in lesion segmentation and anatomical localization but encountered difficulties in disease diagnosis and lesion detection. Additionally, both the Gemini series and GPT series contain models that have demonstrated commendable generation efficiency. While both models hold promise in reducing physician workload, alleviating pressure on limited healthcare resources, and fostering collaboration between clinical practitioners and artificial intelligence technologies, substantial enhancements and comprehensive validations remain imperative before clinical deployment.
IRASim: Learning Interactive Real-Robot Action Simulators
Jun 20, 2024



Scalable robot learning in the real world is limited by the cost and safety issues of real robots. In addition, rolling out robot trajectories in the real world can be time-consuming and labor-intensive. In this paper, we propose to learn an interactive real-robot action simulator as an alternative. We introduce a novel method, IRASim, which leverages the power of generative models to generate extremely realistic videos of a robot arm that executes a given action trajectory, starting from an initial given frame. To validate the effectiveness of our method, we create a new benchmark, IRASim Benchmark, based on three real-robot datasets and perform extensive experiments on the benchmark. Results show that IRASim outperforms all the baseline methods and is more preferable in human evaluations. We hope that IRASim can serve as an effective and scalable approach to enhance robot learning in the real world. To promote research for generative real-robot action simulators, we open-source code, benchmark, and checkpoints at https: //gen-irasim.github.io.
TexVocab: Texture Vocabulary-conditioned Human Avatars
Mar 31, 2024



To adequately utilize the available image evidence in multi-view video-based avatar modeling, we propose TexVocab, a novel avatar representation that constructs a texture vocabulary and associates body poses with texture maps for animation. Given multi-view RGB videos, our method initially back-projects all the available images in the training videos to the posed SMPL surface, producing texture maps in the SMPL UV domain. Then we construct pairs of human poses and texture maps to establish a texture vocabulary for encoding dynamic human appearances under various poses. Unlike the commonly used joint-wise manner, we further design a body-part-wise encoding strategy to learn the structural effects of the kinematic chain. Given a driving pose, we query the pose feature hierarchically by decomposing the pose vector into several body parts and interpolating the texture features for synthesizing fine-grained human dynamics. Overall, our method is able to create animatable human avatars with detailed and dynamic appearances from RGB videos, and the experiments show that our method outperforms state-of-the-art approaches. The project page can be found at https://texvocab.github.io/.