 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridgeVLA: Input-Output Alignment for Efficient 3D Manipulation Learning with Vision-Language Models
Jun 09, 2025Recently, leveraging pre-trained vision-language models (VLMs) for building vision-language-action (VLA) models has emerged as a promising approach to effective robot manipulation learning. However, only few methods incorporate 3D signals into VLMs for action prediction, and they do not fully leverage the spatial structure inherent in 3D data, leading to low sample efficiency. In this paper, we introduce BridgeVLA, a novel 3D VLA model that (1) projects 3D inputs to multiple 2D images, ensuring input alignment with the VLM backbone, and (2) utilizes 2D heatmaps for action prediction, unifying the input and output spaces within a consistent 2D image space. In addition, we propose a scalable pre-training method that equips the VLM backbone with the capability to predict 2D heatmaps before downstream policy learning. Extensive experiments show the proposed method is able to learn 3D manipulation efficiently and effectively. BridgeVLA outperforms state-of-the-art baseline methods across three simulation benchmarks. In RLBench, it improves the average success rate from 81.4% to 88.2%. In COLOSSEUM, it demonstrates significantly better performance in challenging generalization settings, boosting the average success rate from 56.7% to 64.0%. In GemBench, it surpasses all the comparing baseline methods in terms of average success rate. In real-robot experiments, BridgeVLA outperforms a state-of-the-art baseline method by 32% on average. It generalizes robustly in multiple out-of-distribution settings, including visual disturbances and unseen instructions. Remarkably, it is able to achieve a success rate of 96.8% on 10+ tasks with only 3 trajectories per task, highlighting its extraordinary sample efficiency. Project Website:https://bridgevla.github.io/
Robotic Policy Learning via Human-assisted Action Preference Optimization
Jun 08, 2025



Establishing a reliable and iteratively refined robotic system is essential for deploying real-world applications. While Vision-Language-Action (VLA) models are widely recognized as the foundation model for such robotic deployment, their dependence on expert demonstrations hinders the crucial capabilities of correction and learning from failures. To mitigate this limitation, we introduce a Human-assisted Action Preference Optimization method named HAPO, designed to correct deployment failures and foster effective adaptation through preference alignment for VLA models. This method begins with a human-robot collaboration framework for reliable failure correction and interaction trajectory collection through human intervention. These human-intervention trajectories are further employed within the action preference optimization process, facilitating VLA models to mitigate failure action occurrences while enhancing corrective action adaptation. Specifically, we propose an adaptive reweighting algorithm to address the issues of irreversible interactions and token probability mismatch when introducing preference optimization into VLA models, facilitating model learning from binary desirability signals derived from interactions. Through combining these modules, our human-assisted action preference optimization method ensures reliable deployment and effective learning from failure for VLA models. The experiments conducted in simulation and real-world scenarios prove superior generalization and robustness of our framework across a variety of manipulation tasks.
BrainSegDMlF: A Dynamic Fusion-enhanced SAM for Brain Lesion Segmentation
May 09, 2025The segmentation of substantial brain lesions is a significant and challenging task in the field of medical image segmentation. Substantial brain lesions in brain imaging exhibit high heterogeneity, with indistinct boundaries between lesion regions and normal brain tissue. Small lesions in single slices are difficult to identify, making the accurate and reproducible segmentation of abnormal regions, as well as their feature description, highly complex. Existing methods have the following limitations: 1) They rely solely on single-modal information for learning, neglecting the multi-modal information commonly used in diagnosis. This hampers the ability to comprehensively acquire brain lesion information from multiple perspectives and prevents the effective integration and utilization of multi-modal data inputs, thereby limiting a holistic understanding of lesions. 2) They are constrained by the amount of data available, leading to low sensitivity to small lesions and difficulty in detecting subtle pathological changes. 3) Current SAM-based models rely on external prompts, which cannot achieve automatic segmentation and, to some extent, affect diagnostic efficiency.To address these issues, we have developed a large-scale fully automated segmentation model specifically designed for brain lesion segmentation, named BrainSegDMLF. This model has the following features: 1) Dynamic Modal Interactive Fusion (DMIF) module that processes and integrates multi-modal data during the encoding process, providing the SAM encoder with more comprehensive modal information. 2) Layer-by-Layer Upsampling Decoder, enabling the model to extract rich low-level and high-level features even with limited data, thereby detecting the presence of small lesions. 3) Automatic segmentation masks, allowing the model to generate lesion masks automatically without requiring manual prompts.
NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.
Semi-Supervised Video Desnowing Network via Temporal Decoupling Experts and Distribution-Driven Contrastive Regularization
Oct 10, 2024



Snow degradations present formidable challenges to the advancement of computer vision tasks by the undesirable corruption in outdoor scenarios. While current deep learning-based desnowing approaches achieve success on synthetic benchmark datasets, they struggle to restore out-of-distribution real-world snowy videos due to the deficiency of paired real-world training data. To address this bottleneck, we devise a new paradigm for video desnowing in a semi-supervised spirit to involve unlabeled real data for the generalizable snow removal. Specifically, we construct a real-world dataset with 85 snowy videos, and then present a Semi-supervised Video Desnowing Network (SemiVDN) equipped by a novel Distribution-driven Contrastive Regularization. The elaborated contrastive regularization mitigates the distribution gap between the synthetic and real data, and consequently maintains the desired snow-invariant background details. Furthermore, based on the atmospheric scattering model, we introduce a Prior-guided Temporal Decoupling Experts module to decompose the physical components that make up a snowy video in a frame-correlated manner. We evaluate our SemiVDN on benchmark datasets and the collected real snowy data. The experimental results demonstrate the superiority of our approach against state-of-the-art image- and video-level desnowing methods.
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
Oct 08, 2024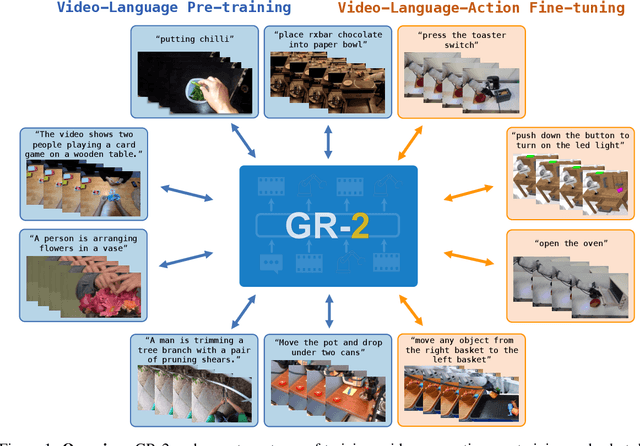
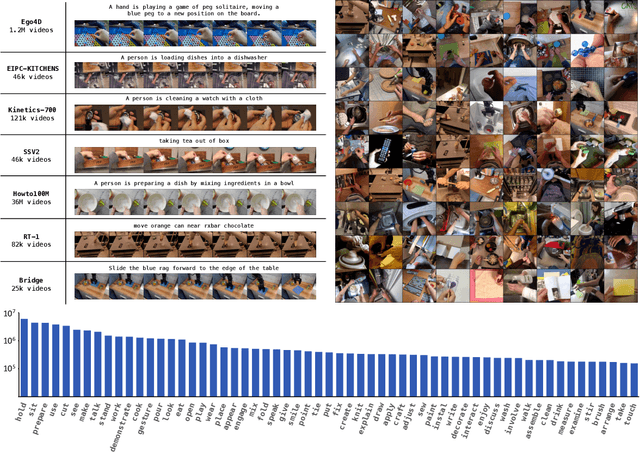


We present GR-2, a state-of-the-art generalist robot agent for versatile and generalizable robot manipulation. GR-2 is first pre-trained on a vast number of Internet videos to capture the dynamics of the world. This large-scale pre-training, involving 38 million video clips and over 50 billion tokens, equips GR-2 with the ability to generalize across a wide range of robotic tasks and environments during subsequent policy learning. Following this, GR-2 is fine-tuned for both video generation and action prediction using robot trajectories. It exhibits impressive multi-task learning capabilities, achieving an average success rate of 97.7% across more than 100 tasks. Moreover, GR-2 demonstrates exceptional generalization to new, previously unseen scenarios, including novel backgrounds, environments, objects, and tasks. Notably, GR-2 scales effectively with model size, underscoring its potential for continued growth and application. Project page: \url{https://gr2-manipulation.github.io}.
World Model-based Perception for Visual Legged Locomotion
Sep 25, 2024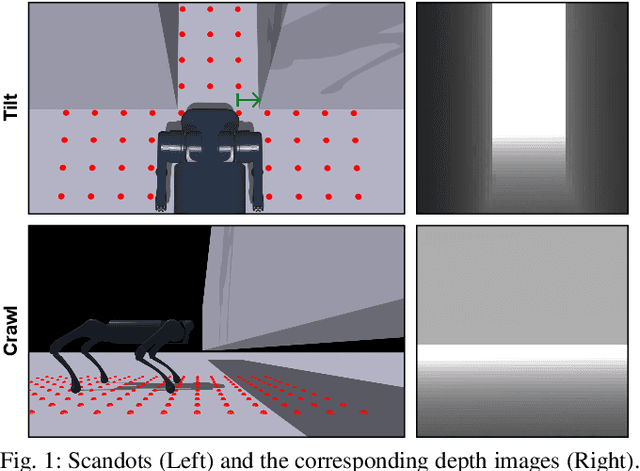
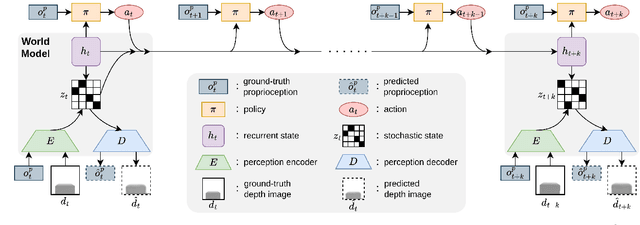
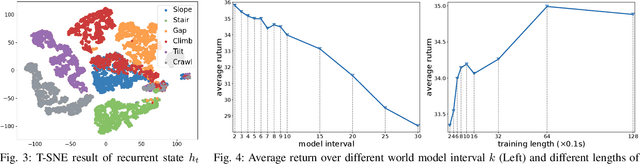

Legged locomotion over various terrains is challenging and requires precise perception of the robot and its surroundings from both proprioception and vision. However, learning directly from high-dimensional visual input is often data-inefficient and intricate. To address this issue, traditional methods attempt to learn a teacher policy with access to privileged information first and then learn a student policy to imitate the teacher's behavior with visual input. Despite some progress, this imitation framework prevents the student policy from achieving optimal performance due to the information gap between inputs. Furthermore, the learning process is unnatural since animals intuitively learn to traverse different terrains based on their understanding of the world without privileged knowledge. Inspired by this natural ability, we propose a simple yet effective method, World Model-based Perception (WMP), which builds a world model of the environment and learns a policy based on the world model. We illustrate that though completely trained in simulation, the world model can make accurate predictions of real-world trajectories, thus providing informative signals for the policy controller. Extensive simulated and real-world experiments demonstrate that WMP outperforms state-of-the-art baselines in traversability and robustness. Videos and Code are available at: https://wmp-loco.github.io/.
GR-MG: Leveraging Partially Annotated Data via Multi-Modal Goal Conditioned Policy
Aug 26, 2024The robotics community has consistently aimed to achieve generalizable robot manipulation with flexible natural language instructions. One of the primary challenges is that obtaining robot data fully annotated with both actions and texts is time-consuming and labor-intensive. However, partially annotated data, such as human activity videos without action labels and robot play data without language labels, is much easier to collect. Can we leverage these data to enhance the generalization capability of robots? In this paper, we propose GR-MG, a novel method which supports conditioning on both a language instruction and a goal image. During training, GR-MG samples goal images from trajectories and conditions on both the text and the goal image or solely on the image when text is unavailable. During inference, where only the text is provided, GR-MG generates the goal image via a diffusion-based image-editing model and condition on both the text and the generated image. This approach enables GR-MG to leverage large amounts of partially annotated data while still using language to flexibly specify tasks. To generate accurate goal images, we propose a novel progress-guided goal image generation model which injects task progress information into the generation process, significantly improving the fidelity and the performance. In simulation experiments, GR-MG improves the average number of tasks completed in a row of 5 from 3.35 to 4.04. In real-robot experiments, GR-MG is able to perform 47 different tasks and improves the success rate from 62.5% to 75.0% and 42.4% to 57.6% in simple and generalization settings, respectively. Code and checkpoints will be available at the project page: https://gr-mg.github.io/.
RainMamba: Enhanced Locality Learning with State Space Models for Video Deraining
Jul 31, 2024



The outdoor vision systems are frequently contaminated by rain streaks and raindrops, which significantly degenerate the performance of visual tasks and multimedia applications. The nature of videos exhibits redundant temporal cues for rain removal with higher stability. Traditional video deraining methods heavily rely on optical flow estimation and kernel-based manners, which have a limited receptive field. Yet, transformer architectures, while enabling long-term dependencies, bring about a significant increase in computational complexity. Recently, the linear-complexity operator of the state space models (SSMs) has contrarily facilitated efficient long-term temporal modeling, which is crucial for rain streaks and raindrops removal in videos. Unexpectedly, its uni-dimensional sequential process on videos destroys the local correlations across the spatio-temporal dimension by distancing adjacent pixels. To address this, we present an improved SSMs-based video deraining network (RainMamba) with a novel Hilbert scanning mechanism to better capture sequence-level local information. We also introduce a difference-guided dynamic contrastive locality learning strategy to enhance the patch-level self-similarity learning ability of the proposed network. Extensive experiments on four synthesized video deraining datasets and real-world rainy videos demonstrate the superiority of our network in the removal of rain streaks and raindrops.
IRASim: Learning Interactive Real-Robot Action Simulators
Jun 20, 2024



Scalable robot learning in the real world is limited by the cost and safety issues of real robots. In addition, rolling out robot trajectories in the real world can be time-consuming and labor-intensive. In this paper, we propose to learn an interactive real-robot action simulator as an alternative. We introduce a novel method, IRASim, which leverages the power of generative models to generate extremely realistic videos of a robot arm that executes a given action trajectory, starting from an initial given frame. To validate the effectiveness of our method, we create a new benchmark, IRASim Benchmark, based on three real-robot datasets and perform extensive experiments on the benchmark. Results show that IRASim outperforms all the baseline methods and is more preferable in human evaluations. We hope that IRASim can serve as an effective and scalable approach to enhance robot learning in the real world. To promote research for generative real-robot action simulators, we open-source code, benchmark, and checkpoints at https: //gen-irasim.github.io.