 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodiment-Aware Generalist Specialist Distillation for Unified Humanoid Whole-Body Control
Feb 03, 2026Humanoid Whole-Body Controllers trained with reinforcement learning (RL) have recently achieved remarkable performance, yet many target a single robot embodiment. Variations in dynamics, degrees of freedom (DoFs), and kinematic topology still hinder a single policy from commanding diverse humanoids. Moreover, obtaining a generalist policy that not only transfers across embodiments but also supports richer behaviors-beyond simple walking to squatting, leaning-remains especially challenging. In this work, we tackle these obstacles by introducing EAGLE, an iterative generalist-specialist distillation framework that produces a single unified policy that controls multiple heterogeneous humanoids without per-robot reward tuning. During each cycle, embodiment-specific specialists are forked from the current generalist, refined on their respective robots, and new skills are distilled back into the generalist by training on the pooled embodiment set. Repeating this loop until performance convergence produces a robust Whole-Body Controller validated on robots such as Unitree H1, G1, and Fourier N1. We conducted experiments on five different robots in simulation and four in real-world settings. Through quantitative evaluations, EAGLE achieves high tracking accuracy and robustness compared to other methods, marking a step toward scalable, fleet-level humanoid control. See more details at https://eagle-wbc.github.io/
UniCon: A Unified System for Efficient Robot Learning Transfers
Jan 21, 2026Deploying learning-based controllers across heterogeneous robots is challenging due to platform differences, inconsistent interfaces, and inefficient middleware. To address these issues, we present UniCon, a lightweight framework that standardizes states, control flow, and instrumentation across platforms. It decomposes workflows into execution graphs with reusable components, separating system states from control logic to enable plug-and-play deployment across various robot morphologies. Unlike traditional middleware, it prioritizes efficiency through batched, vectorized data flow, minimizing communication overhead and improving inference latency. This modular, data-oriented approach enables seamless sim-to-real transfer with minimal re-engineering. We demonstrate that UniCon reduces code redundancy when transferring workflows and achieves higher inference efficiency compared to ROS-based systems. Deployed on over 12 robot models from 7 manufacturers, it has been successfully integrated into ongoing research projects, proving its effectiveness in real-world scenarios.
D4W: Dependable Data-Driven Dynamics for Wheeled Robots
Nov 14, 2024Wheeled robots have gained significant attention due to their wide range of applications in manufacturing, logistics, and service industries. However, due to the difficulty of building a highly accurate dynamics model for wheeled robots, developing and testing control algorithms for them remains challenging and time-consuming, requiring extensive physical experimentation. To address this problem, we propose D4W, i.e., Dependable Data-Driven Dynamics for Wheeled Robots, a simulation framework incorporating data-driven methods to accelerate the development and evaluation of algorithms for wheeled robots. The key contribution of D4W is a solution that utilizes real-world sensor data to learn accurate models of robot dynamics. The learned dynamics can capture complex robot behaviors and interactions with the environment throughout simulations, surpassing the limitations of analytical methods, which only work in simplified scenarios. Experimental results show that D4W achieves the best simulation accuracy compared to traditional approaches, allowing for rapid iteration of wheel robot algorithms with less or no need for fine-tuning in reality. We further verify the usability and practicality of the proposed framework through integration with existing simulators and controllers.
GenSim2: Scaling Robot Data Generation with Multi-modal and Reasoning LLMs
Oct 04, 2024



Robotic simulation today remains challenging to scale up due to the human efforts required to create diverse simulation tasks and scenes. Simulation-trained policies also face scalability issues as many sim-to-real methods focus on a single task. To address these challenges, this work proposes GenSim2, a scalable framework that leverages coding LLMs with multi-modal and reasoning capabilities for complex and realistic simulation task creation, including long-horizon tasks with articulated objects. To automatically generate demonstration data for these tasks at scale, we propose planning and RL solvers that generalize within object categories. The pipeline can generate data for up to 100 articulated tasks with 200 objects and reduce the required human efforts. To utilize such data, we propose an effective multi-task language-conditioned policy architecture, dubbed proprioceptive point-cloud transformer (PPT), that learns from the generated demonstrations and exhibits strong sim-to-real zero-shot transfer. Combining the proposed pipeline and the policy architecture, we show a promising usage of GenSim2 that the generated data can be used for zero-shot transfer or co-train with real-world collected data, which enhances the policy performance by 20% compared with training exclusively on limited real data.
World Model-based Perception for Visual Legged Locomotion
Sep 25, 2024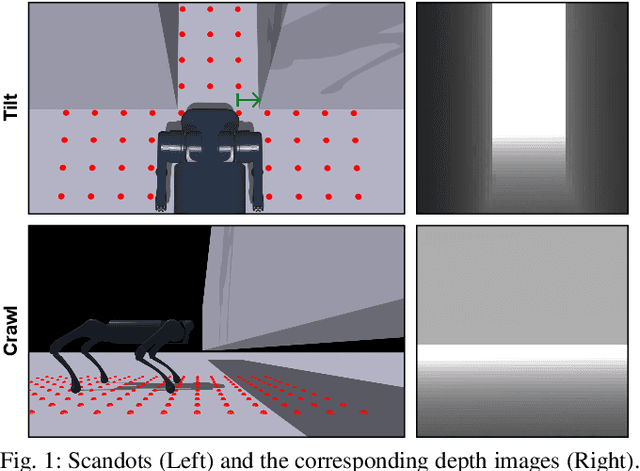
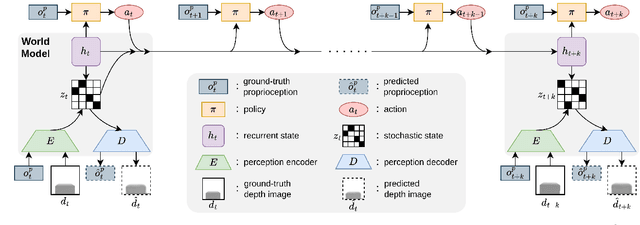
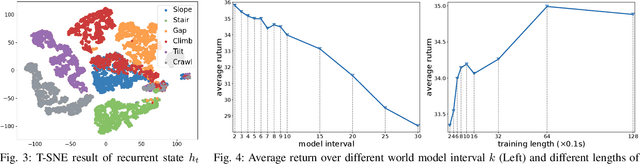

Legged locomotion over various terrains is challenging and requires precise perception of the robot and its surroundings from both proprioception and vision. However, learning directly from high-dimensional visual input is often data-inefficient and intricate. To address this issue, traditional methods attempt to learn a teacher policy with access to privileged information first and then learn a student policy to imitate the teacher's behavior with visual input. Despite some progress, this imitation framework prevents the student policy from achieving optimal performance due to the information gap between inputs. Furthermore, the learning process is unnatural since animals intuitively learn to traverse different terrains based on their understanding of the world without privileged knowledge. Inspired by this natural ability, we propose a simple yet effective method, World Model-based Perception (WMP), which builds a world model of the environment and learns a policy based on the world model. We illustrate that though completely trained in simulation, the world model can make accurate predictions of real-world trajectories, thus providing informative signals for the policy controller. Extensive simulated and real-world experiments demonstrate that WMP outperforms state-of-the-art baselines in traversability and robustness. Videos and Code are available at: https://wmp-loco.github.io/.
DCNN-GAN: Reconstructing Realistic Image from fMRI
Jan 13, 2019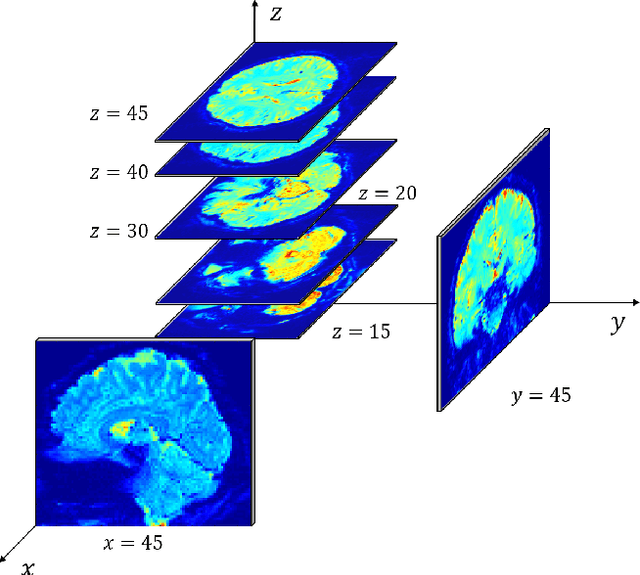
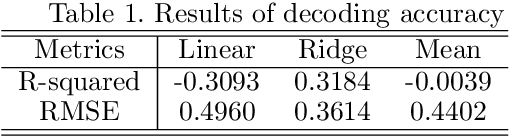
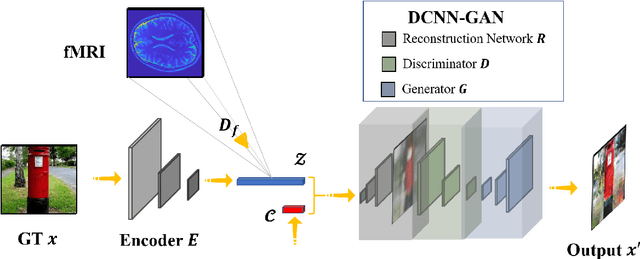

Visualizing the perceptual content by analyzing human functional magnetic resonance imaging (fMRI) has been an active research area. However, due to its high dimensionality, complex dimensional structure, and small number of samples available, reconstructing realistic images from fMRI remains challenging. Recently with the development of convolutional neural network (CNN) and generative adversarial network (GAN), mapping multi-voxel fMRI data to complex, realistic images has been made possible. In this paper, we propose a model, DCNN-GAN, by combining a reconstruction network and GAN. We utilize the CNN for hierarchical feature extraction and the DCNN-GAN to reconstruct more realistic images. Extensive experiments have been conducted, showing that our method outperforms previous works, regarding reconstruction quality and computational cost.