 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Real-World Action-Video Dynamics with Heterogeneous Masked Autoregression
Feb 06, 2025We propose Heterogeneous Masked Autoregression (HMA) for modeling action-video dynamics to generate high-quality data and evaluation in scaling robot learning. Building interactive video world models and policies for robotics is difficult due to the challenge of handling diverse settings while maintaining computational efficiency to run in real time. HMA uses heterogeneous pre-training from observations and action sequences across different robotic embodiments, domains, and tasks. HMA uses masked autoregression to generate quantized or soft tokens for video predictions. \ourshort achieves better visual fidelity and controllability than the previous robotic video generation models with 15 times faster speed in the real world. After post-training, this model can be used as a video simulator from low-level action inputs for evaluating policies and generating synthetic data. See this link https://liruiw.github.io/hma for more information.
Inference-Time Policy Steering through Human Interactions
Nov 25, 2024



Generative policies trained with human demonstrations can autonomously accomplish multimodal, long-horizon tasks. However, during inference, humans are often removed from the policy execution loop, limiting the ability to guide a pre-trained policy towards a specific sub-goal or trajectory shape among multiple predictions. Naive human intervention may inadvertently exacerbate distribution shift, leading to constraint violations or execution failures. To better align policy output with human intent without inducing out-of-distribution errors, we propose an Inference-Time Policy Steering (ITPS) framework that leverages human interactions to bias the generative sampling process, rather than fine-tuning the policy on interaction data. We evaluate ITPS across three simulated and real-world benchmarks, testing three forms of human interaction and associated alignment distance metrics. Among six sampling strategies, our proposed stochastic sampling with diffusion policy achieves the best trade-off between alignment and distribution shift. Videos are available at https://yanweiw.github.io/itps/.
GenSim2: Scaling Robot Data Generation with Multi-modal and Reasoning LLMs
Oct 04, 2024



Robotic simulation today remains challenging to scale up due to the human efforts required to create diverse simulation tasks and scenes. Simulation-trained policies also face scalability issues as many sim-to-real methods focus on a single task. To address these challenges, this work proposes GenSim2, a scalable framework that leverages coding LLMs with multi-modal and reasoning capabilities for complex and realistic simulation task creation, including long-horizon tasks with articulated objects. To automatically generate demonstration data for these tasks at scale, we propose planning and RL solvers that generalize within object categories. The pipeline can generate data for up to 100 articulated tasks with 200 objects and reduce the required human efforts. To utilize such data, we propose an effective multi-task language-conditioned policy architecture, dubbed proprioceptive point-cloud transformer (PPT), that learns from the generated demonstrations and exhibits strong sim-to-real zero-shot transfer. Combining the proposed pipeline and the policy architecture, we show a promising usage of GenSim2 that the generated data can be used for zero-shot transfer or co-train with real-world collected data, which enhances the policy performance by 20% compared with training exclusively on limited real data.
Scaling Proprioceptive-Visual Learning with Heterogeneous Pre-trained Transformers
Sep 30, 2024



One of the roadblocks for training generalist robotic models today is heterogeneity. Previous robot learning methods often collect data to train with one specific embodiment for one task, which is expensive and prone to overfitting. This work studies the problem of learning policy representations through heterogeneous pre-training on robot data across different embodiments and tasks at scale. We propose Heterogeneous Pre-trained Transformers (HPT), which pre-train a large, shareable trunk of a policy neural network to learn a task and embodiment agnostic shared representation. This general architecture aligns the specific proprioception and vision inputs from distinct embodiments to a short sequence of tokens and then processes such tokens to map to control robots for different tasks. Leveraging the recent large-scale multi-embodiment real-world robotic datasets as well as simulation, deployed robots, and human video datasets, we investigate pre-training policies across heterogeneity. We conduct experiments to investigate the scaling behaviors of training objectives, to the extent of 52 datasets. HPTs outperform several baselines and enhance the fine-tuned policy performance by over 20% on unseen tasks in multiple simulator benchmarks and real-world settings. See the project website (https://liruiw.github.io/hpt/) for code and videos.
* See the project website (https://liruiw.github.io/hpt/) for code and videos
Transferable Tactile Transformers for Representation Learning Across Diverse Sensors and Tasks
Jun 19, 2024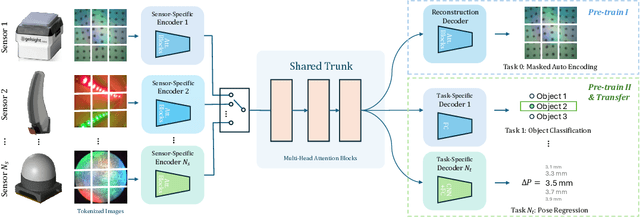
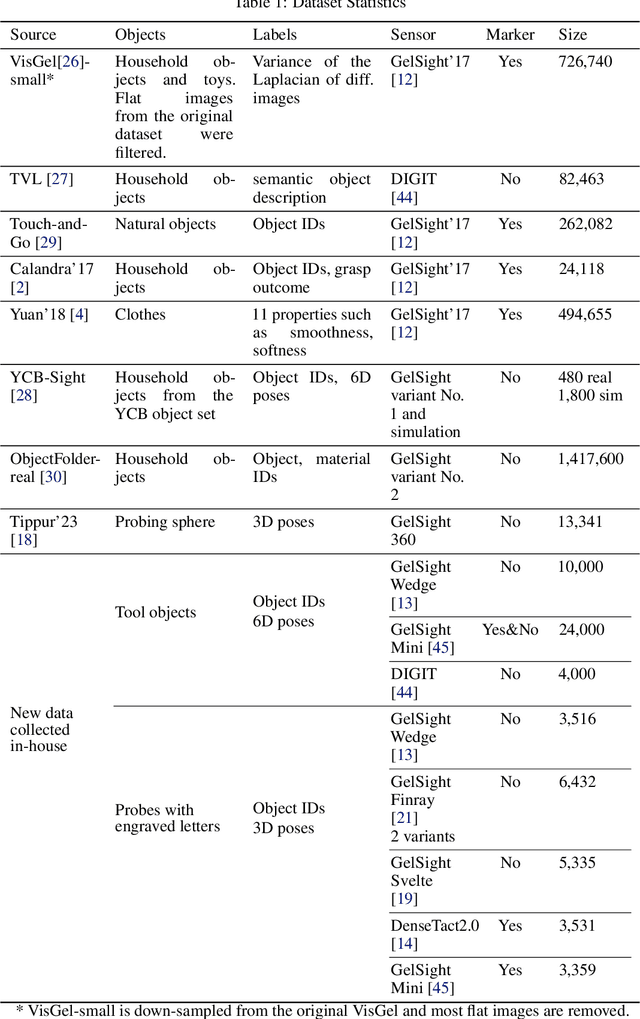
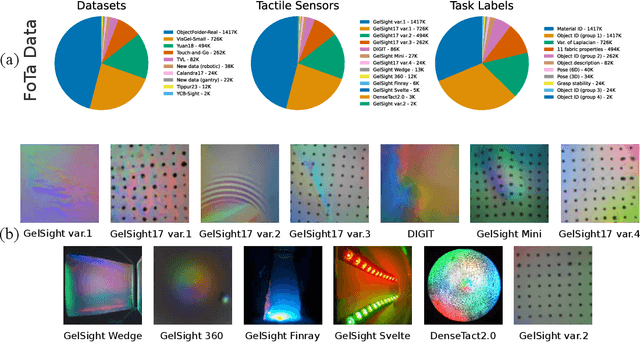
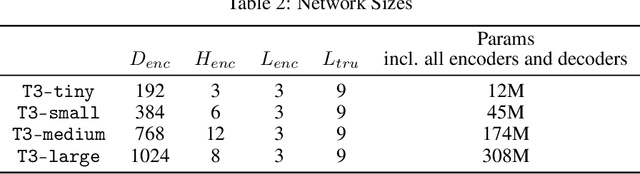
This paper presents T3: Transferable Tactile Transformers, a framework for tactile representation learning that scales across multi-sensors and multi-tasks. T3 is designed to overcome the contemporary issue that camera-based tactile sensing is extremely heterogeneous, i.e. sensors are built into different form factors, and existing datasets were collected for disparate tasks. T3 captures the shared latent information across different sensor-task pairings by constructing a shared trunk transformer with sensor-specific encoders and task-specific decoders. The pre-training of T3 utilizes a novel Foundation Tactile (FoTa) dataset, which is aggregated from several open-sourced datasets and it contains over 3 million data points gathered from 13 sensors and 11 tasks. FoTa is the largest and most diverse dataset in tactile sensing to date and it is made publicly available in a unified format. Across various sensors and tasks, experiments show that T3 pre-trained with FoTa achieved zero-shot transferability in certain sensor-task pairings, can be further fine-tuned with small amounts of domain-specific data, and its performance scales with bigger network sizes. T3 is also effective as a tactile encoder for long horizon contact-rich manipulation. Results from sub-millimeter multi-pin electronics insertion tasks show that T3 achieved a task success rate 25% higher than that of policies trained with tactile encoders trained from scratch, or 53% higher than without tactile sensing. Data, code, and model checkpoints are open-sourced at https://t3.alanz.info.
PoCo: Policy Composition from and for Heterogeneous Robot Learning
Feb 04, 2024
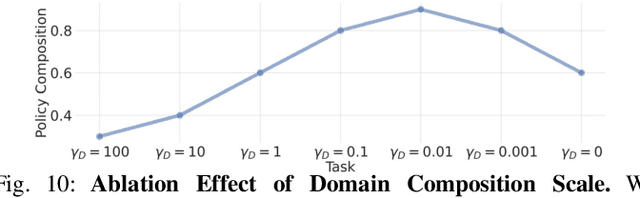
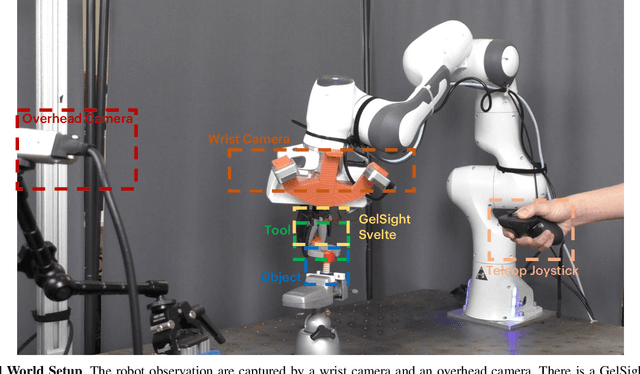
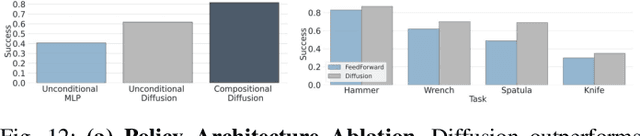
Training general robotic policies from heterogeneous data for different tasks is a significant challenge. Existing robotic datasets vary in different modalities such as color, depth, tactile, and proprioceptive information, and collected in different domains such as simulation, real robots, and human videos. Current methods usually collect and pool all data from one domain to train a single policy to handle such heterogeneity in tasks and domains, which is prohibitively expensive and difficult. In this work, we present a flexible approach, dubbed Policy Composition, to combine information across such diverse modalities and domains for learning scene-level and task-level generalized manipulation skills, by composing different data distributions represented with diffusion models. Our method can use task-level composition for multi-task manipulation and be composed with analytic cost functions to adapt policy behaviors at inference time. We train our method on simulation, human, and real robot data and evaluate in tool-use tasks. The composed policy achieves robust and dexterous performance under varying scenes and tasks and outperforms baselines from a single data source in both simulation and real-world experiments. See https://liruiw.github.io/policycomp for more details .
Fleet Policy Learning via Weight Merging and An Application to Robotic Tool-Use
Oct 02, 2023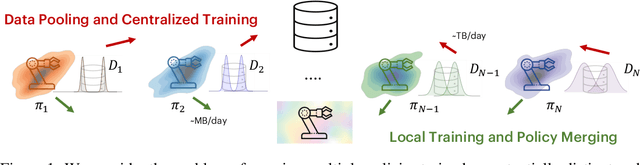

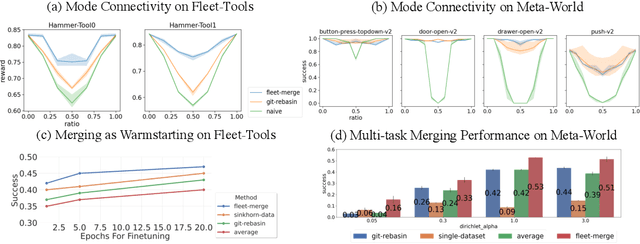
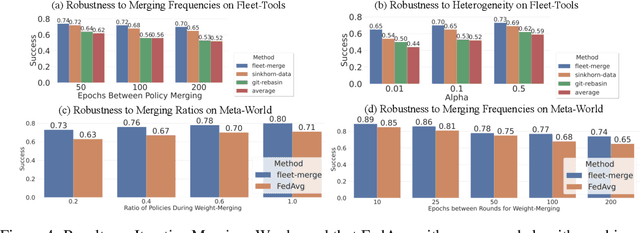
Fleets of robots ingest massive amounts of streaming data generated by interacting with their environments, far more than those that can be stored or transmitted with ease. At the same time, we hope that teams of robots can co-acquire diverse skills through their experiences in varied settings. How can we enable such fleet-level learning without having to transmit or centralize fleet-scale data? In this paper, we investigate distributed learning of policies as a potential solution. To efficiently merge policies in the distributed setting, we propose fleet-merge, an instantiation of distributed learning that accounts for the symmetries that can arise in learning policies that are parameterized by recurrent neural networks. We show that fleet-merge consolidates the behavior of policies trained on 50 tasks in the Meta-World environment, with the merged policy achieving good performance on nearly all training tasks at test time. Moreover, we introduce a novel robotic tool-use benchmark, fleet-tools, for fleet policy learning in compositional and contact-rich robot manipulation tasks, which might be of broader interest, and validate the efficacy of fleet-merge on the benchmark.
GenSim: Generating Robotic Simulation Tasks via Large Language Models
Oct 02, 2023

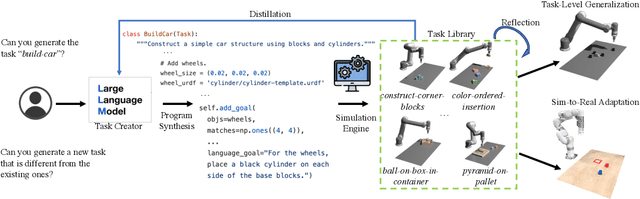
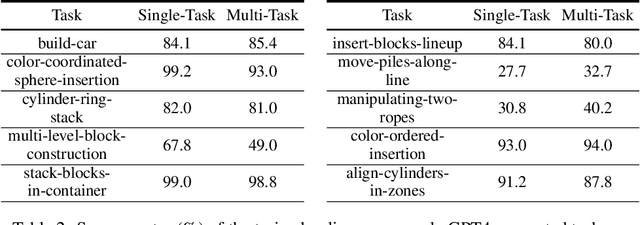
Collecting large amounts of real-world interaction data to train general robotic policies is often prohibitively expensive, thus motivating the use of simulation data. However, existing methods for data generation have generally focused on scene-level diversity (e.g., object instances and poses) rather than task-level diversity, due to the human effort required to come up with and verify novel tasks. This has made it challenging for policies trained on simulation data to demonstrate significant task-level generalization. In this paper, we propose to automatically generate rich simulation environments and expert demonstrations by exploiting a large language models' (LLM) grounding and coding ability. Our approach, dubbed GenSim, has two modes: goal-directed generation, wherein a target task is given to the LLM and the LLM proposes a task curriculum to solve the target task, and exploratory generation, wherein the LLM bootstraps from previous tasks and iteratively proposes novel tasks that would be helpful in solving more complex tasks. We use GPT4 to expand the existing benchmark by ten times to over 100 tasks, on which we conduct supervised finetuning and evaluate several LLMs including finetuned GPTs and Code Llama on code generation for robotic simulation tasks. Furthermore, we observe that LLMs-generated simulation programs can enhance task-level generalization significantly when used for multitask policy training. We further find that with minimal sim-to-real adaptation, the multitask policies pretrained on GPT4-generated simulation tasks exhibit stronger transfer to unseen long-horizon tasks in the real world and outperform baselines by 25%. See the project website (https://liruiw.github.io/gensim) for code, demos, and videos.
3D Neural Embedding Likelihood for Robust Sim-to-Real Transfer in Inverse Graphics
Feb 07, 2023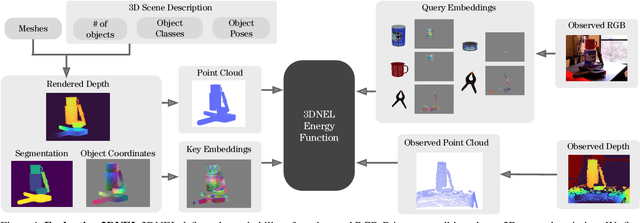

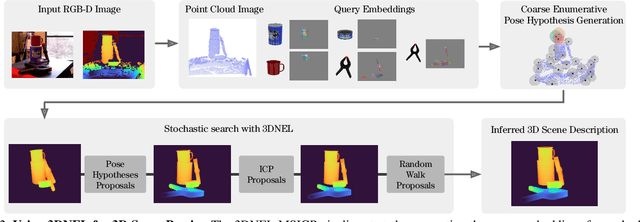
A central challenge in 3D scene perception via inverse graphics is robustly modeling the gap between 3D graphics and real-world data. We propose a novel 3D Neural Embedding Likelihood (3DNEL) over RGB-D images to address this gap. 3DNEL uses neural embeddings to predict 2D-3D correspondences from RGB and combines this with depth in a principled manner. 3DNEL is trained entirely from synthetic images and generalizes to real-world data. To showcase this capability, we develop a multi-stage inverse graphics pipeline that uses 3DNEL for 6D object pose estimation from real RGB-D images. Our method outperforms the previous state-of-the-art in sim-to-real pose estimation on the YCB-Video dataset, and improves robustness, with significantly fewer large-error predictions. Unlike existing bottom-up, discriminative approaches that are specialized for pose estimation, 3DNEL adopts a probabilistic generative formulation that jointly models multi-object scenes. This generative formulation enables easy extension of 3DNEL to additional tasks like object and camera tracking from video, using principled inference in the same probabilistic model without task specific retraining.
NeRF in the Palm of Your Hand: Corrective Augmentation for Robotics via Novel-View Synthesis
Jan 18, 2023Expert demonstrations are a rich source of supervision for training visual robotic manipulation policies, but imitation learning methods often require either a large number of demonstrations or expensive online expert supervision to learn reactive closed-loop behaviors. In this work, we introduce SPARTN (Synthetic Perturbations for Augmenting Robot Trajectories via NeRF): a fully-offline data augmentation scheme for improving robot policies that use eye-in-hand cameras. Our approach leverages neural radiance fields (NeRFs) to synthetically inject corrective noise into visual demonstrations, using NeRFs to generate perturbed viewpoints while simultaneously calculating the corrective actions. This requires no additional expert supervision or environment interaction, and distills the geometric information in NeRFs into a real-time reactive RGB-only policy. In a simulated 6-DoF visual grasping benchmark, SPARTN improves success rates by 2.8$\times$ over imitation learning without the corrective augmentations and even outperforms some methods that use online supervision. It additionally closes the gap between RGB-only and RGB-D success rates, eliminating the previous need for depth sensors. In real-world 6-DoF robotic grasping experiments from limited human demonstrations, our method improves absolute success rates by $22.5\%$ on average, including objects that are traditionally challenging for depth-based methods. See video results at \url{https://bland.website/spartn}.