 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion Blur Robust Wheat Pest Damage Detection with Dynamic Fuzzy Feature Fusion
Jan 06, 2026Motion blur caused by camera shake produces ghosting artifacts that substantially degrade edge side object detection. Existing approaches either suppress blur as noise and lose discriminative structure, or apply full image restoration that increases latency and limits deployment on resource constrained devices. We propose DFRCP, a Dynamic Fuzzy Robust Convolutional Pyramid, as a plug in upgrade to YOLOv11 for blur robust detection. DFRCP enhances the YOLOv11 feature pyramid by combining large scale and medium scale features while preserving native representations, and by introducing Dynamic Robust Switch units that adaptively inject fuzzy features to strengthen global perception under jitter. Fuzzy features are synthesized by rotating and nonlinearly interpolating multiscale features, then merged through a transparency convolution that learns a content adaptive trade off between original and fuzzy cues. We further develop a CUDA parallel rotation and interpolation kernel that avoids boundary overflow and delivers more than 400 times speedup, making the design practical for edge deployment. We train with paired supervision on a private wheat pest damage dataset of about 3,500 images, augmented threefold using two blur regimes, uniform image wide motion blur and bounding box confined rotational blur. On blurred test sets, YOLOv11 with DFRCP achieves about 10.4 percent higher accuracy than the YOLOv11 baseline with only a modest training time overhead, reducing the need for manual filtering after data collection.
A Roadmap for Climate-Relevant Robotics Research
Jul 15, 2025



Climate change is one of the defining challenges of the 21st century, and many in the robotics community are looking for ways to contribute. This paper presents a roadmap for climate-relevant robotics research, identifying high-impact opportunities for collaboration between roboticists and experts across climate domains such as energy, the built environment, transportation, industry, land use, and Earth sciences. These applications include problems such as energy systems optimization, construction, precision agriculture, building envelope retrofits, autonomous trucking, and large-scale environmental monitoring. Critically, we include opportunities to apply not only physical robots but also the broader robotics toolkit - including planning, perception, control, and estimation algorithms - to climate-relevant problems. A central goal of this roadmap is to inspire new research directions and collaboration by highlighting specific, actionable problems at the intersection of robotics and climate. This work represents a collaboration between robotics researchers and domain experts in various climate disciplines, and it serves as an invitation to the robotics community to bring their expertise to bear on urgent climate priorities.
Steering Robots with Inference-Time Interactions
Jun 17, 2025

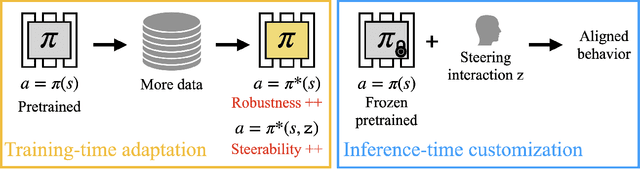
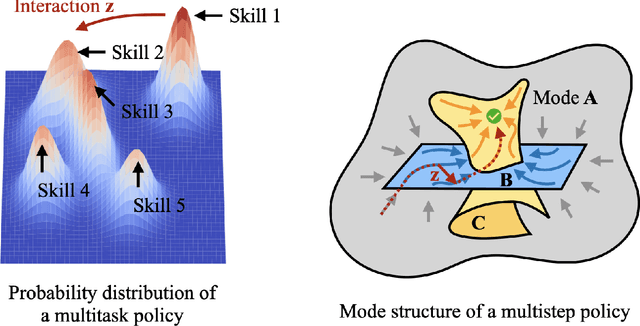
Imitation learning has driven the development of generalist policies capable of autonomously solving multiple tasks. However, when a pretrained policy makes errors during deployment, there are limited mechanisms for users to correct its behavior. While collecting additional data for finetuning can address such issues, doing so for each downstream use case is inefficient at deployment. My research proposes an alternative: keeping pretrained policies frozen as a fixed skill repertoire while allowing user interactions to guide behavior generation toward user preferences at inference time. By making pretrained policies steerable, users can help correct policy errors when the model struggles to generalize-without needing to finetune the policy. Specifically, I propose (1) inference-time steering, which leverages user interactions to switch between discrete skills, and (2) task and motion imitation, which enables user interactions to edit continuous motions while satisfying task constraints defined by discrete symbolic plans. These frameworks correct misaligned policy predictions without requiring additional training, maximizing the utility of pretrained models while achieving inference-time user objectives.
Partner Modelling Emerges in Recurrent Agents (But Only When It Matters)
May 22, 2025Humans are remarkably adept at collaboration, able to infer the strengths and weaknesses of new partners in order to work successfully towards shared goals. To build AI systems with this capability, we must first understand its building blocks: does such flexibility require explicit, dedicated mechanisms for modelling others -- or can it emerge spontaneously from the pressures of open-ended cooperative interaction? To investigate this question, we train simple model-free RNN agents to collaborate with a population of diverse partners. Using the `Overcooked-AI' environment, we collect data from thousands of collaborative teams, and analyse agents' internal hidden states. Despite a lack of additional architectural features, inductive biases, or auxiliary objectives, the agents nevertheless develop structured internal representations of their partners' task abilities, enabling rapid adaptation and generalisation to novel collaborators. We investigated these internal models through probing techniques, and large-scale behavioural analysis. Notably, we find that structured partner modelling emerges when agents can influence partner behaviour by controlling task allocation. Our results show that partner modelling can arise spontaneously in model-free agents -- but only under environmental conditions that impose the right kind of social pressure.
Sub-Image Recapture for Multi-View 3D Reconstruction
Mar 10, 2025



3D reconstruction of high-resolution target remains a challenge task due to the large memory required from the large input image size. Recently developed learning based algorithms provide promising reconstruction performance than traditional ones, however, they generally require more memory than the traditional algorithms and facing scalability issue. In this paper, we developed a generic approach, sub-image recapture (SIR), to split large image into smaller sub-images and process them individually. As a result of this framework, the existing 3D reconstruction algorithms can be implemented based on sub-image recapture with significantly reduced memory and substantially improved scalability
Inference-Time Policy Steering through Human Interactions
Nov 25, 2024



Generative policies trained with human demonstrations can autonomously accomplish multimodal, long-horizon tasks. However, during inference, humans are often removed from the policy execution loop, limiting the ability to guide a pre-trained policy towards a specific sub-goal or trajectory shape among multiple predictions. Naive human intervention may inadvertently exacerbate distribution shift, leading to constraint violations or execution failures. To better align policy output with human intent without inducing out-of-distribution errors, we propose an Inference-Time Policy Steering (ITPS) framework that leverages human interactions to bias the generative sampling process, rather than fine-tuning the policy on interaction data. We evaluate ITPS across three simulated and real-world benchmarks, testing three forms of human interaction and associated alignment distance metrics. Among six sampling strategies, our proposed stochastic sampling with diffusion policy achieves the best trade-off between alignment and distribution shift. Videos are available at https://yanweiw.github.io/itps/.
First Place Solution to the ECCV 2024 ROAD++ Challenge @ ROAD++ Atomic Activity Recognition 2024
Oct 30, 2024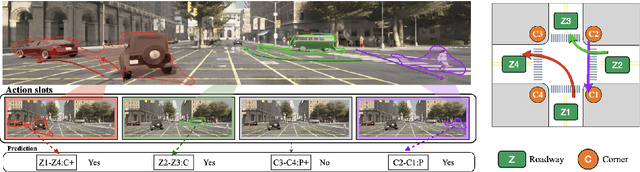



This report presents our team's technical solution for participating in Track 3 of the 2024 ECCV ROAD++ Challenge. The task of Track 3 is atomic activity recognition, which aims to identify 64 types of atomic activities in road scenes based on video content. Our approach primarily addresses the challenges of small objects, discriminating between single object and a group of objects, as well as model overfitting in this task. Firstly, we construct a multi-branch activity recognition framework that not only separates different object categories but also the tasks of single object and object group recognition, thereby enhancing recognition accuracy. Subsequently, we develop various model ensembling strategies, including integrations of multiple frame sampling sequences, different frame sampling sequence lengths, multiple training epochs, and different backbone networks. Furthermore, we propose an atomic activity recognition data augmentation method, which greatly expands the sample space by flipping video frames and road topology, effectively mitigating model overfitting. Our methods rank first in the test set of Track 3 for the ROAD++ Challenge 2024, and achieve 69% mAP.
Versatile Demonstration Interface: Toward More Flexible Robot Demonstration Collection
Oct 24, 2024



Previous methods for Learning from Demonstration leverage several approaches for a human to teach motions to a robot, including teleoperation, kinesthetic teaching, and natural demonstrations. However, little previous work has explored more general interfaces that allow for multiple demonstration types. Given the varied preferences of human demonstrators and task characteristics, a flexible tool that enables multiple demonstration types could be crucial for broader robot skill training. In this work, we propose Versatile Demonstration Interface (VDI), an attachment for collaborative robots that simplifies the collection of three common types of demonstrations. Designed for flexible deployment in industrial settings, our tool requires no additional instrumentation of the environment. Our prototype interface captures human demonstrations through a combination of vision, force sensing, and state tracking (e.g., through the robot proprioception or AprilTag tracking). Through a user study where we deployed our prototype VDI at a local manufacturing innovation center with manufacturing experts, we demonstrated the efficacy of our prototype in representative industrial tasks. Interactions from our study exposed a range of industrial use cases for VDI, clear relationships between demonstration preferences and task criteria, and insights for future tool design.
Grounding Language Plans in Demonstrations Through Counterfactual Perturbations
Mar 25, 2024



Grounding the common-sense reasoning of Large Language Models in physical domains remains a pivotal yet unsolved problem for embodied AI. Whereas prior works have focused on leveraging LLMs directly for planning in symbolic spaces, this work uses LLMs to guide the search of task structures and constraints implicit in multi-step demonstrations. Specifically, we borrow from manipulation planning literature the concept of mode families, which group robot configurations by specific motion constraints, to serve as an abstraction layer between the high-level language representations of an LLM and the low-level physical trajectories of a robot. By replaying a few human demonstrations with synthetic perturbations, we generate coverage over the demonstrations' state space with additional successful executions as well as counterfactuals that fail the task. Our explanation-based learning framework trains an end-to-end differentiable neural network to predict successful trajectories from failures and as a by-product learns classifiers that ground low-level states and images in mode families without dense labeling. The learned grounding classifiers can further be used to translate language plans into reactive policies in the physical domain in an interpretable manner. We show our approach improves the interpretability and reactivity of imitation learning through 2D navigation and simulated and real robot manipulation tasks. Website: https://sites.google.com/view/grounding-plans
Human-Machine Cooperative Multimodal Learning Method for Cross-subject Olfactory Preference Recognition
Nov 24, 2023Odor sensory evaluation has a broad application in food, clothing, cosmetics, and other fields. Traditional artificial sensory evaluation has poor repeatability, and the machine olfaction represented by the electronic nose (E-nose) is difficult to reflect human feelings. Olfactory electroencephalogram (EEG) contains odor and individual features associated with human olfactory preference, which has unique advantages in odor sensory evaluation. However, the difficulty of cross-subject olfactory EEG recognition greatly limits its application. It is worth noting that E-nose and olfactory EEG are more advantageous in representing odor information and individual emotions, respectively. In this paper, an E-nose and olfactory EEG multimodal learning method is proposed for cross-subject olfactory preference recognition. Firstly, the olfactory EEG and E-nose multimodal data acquisition and preprocessing paradigms are established. Secondly, a complementary multimodal data mining strategy is proposed to effectively mine the common features of multimodal data representing odor information and the individual features in olfactory EEG representing individual emotional information. Finally, the cross-subject olfactory preference recognition is achieved in 24 subjects by fusing the extracted common and individual features, and the recognition effect is superior to the state-of-the-art recognition methods. Furthermore, the advantages of the proposed method in cross-subject olfactory preference recognition indicate its potential for practical odor evaluation applications.