 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVersatile Demonstration Interface: Toward More Flexible Robot Demonstration Collection
Oct 24, 2024



Previous methods for Learning from Demonstration leverage several approaches for a human to teach motions to a robot, including teleoperation, kinesthetic teaching, and natural demonstrations. However, little previous work has explored more general interfaces that allow for multiple demonstration types. Given the varied preferences of human demonstrators and task characteristics, a flexible tool that enables multiple demonstration types could be crucial for broader robot skill training. In this work, we propose Versatile Demonstration Interface (VDI), an attachment for collaborative robots that simplifies the collection of three common types of demonstrations. Designed for flexible deployment in industrial settings, our tool requires no additional instrumentation of the environment. Our prototype interface captures human demonstrations through a combination of vision, force sensing, and state tracking (e.g., through the robot proprioception or AprilTag tracking). Through a user study where we deployed our prototype VDI at a local manufacturing innovation center with manufacturing experts, we demonstrated the efficacy of our prototype in representative industrial tasks. Interactions from our study exposed a range of industrial use cases for VDI, clear relationships between demonstration preferences and task criteria, and insights for future tool design.
Utilising Explanations to Mitigate Robot Conversational Failures
Jul 10, 2023This paper presents an overview of robot failure detection work from HRI and adjacent fields using failures as an opportunity to examine robot explanation behaviours. As humanoid robots remain experimental tools in the early 2020s, interactions with robots are situated overwhelmingly in controlled environments, typically studying various interactional phenomena. Such interactions suffer from real-world and large-scale experimentation and tend to ignore the 'imperfectness' of the everyday user. Robot explanations can be used to approach and mitigate failures, by expressing robot legibility and incapability, and within the perspective of common-ground. In this paper, I discuss how failures present opportunities for explanations in interactive conversational robots and what the potentials are for the intersection of HRI and explainability research.
A Comparison of Visualisation Methods for Disambiguating Verbal Requests in Human-Robot Interaction
Jan 26, 2018

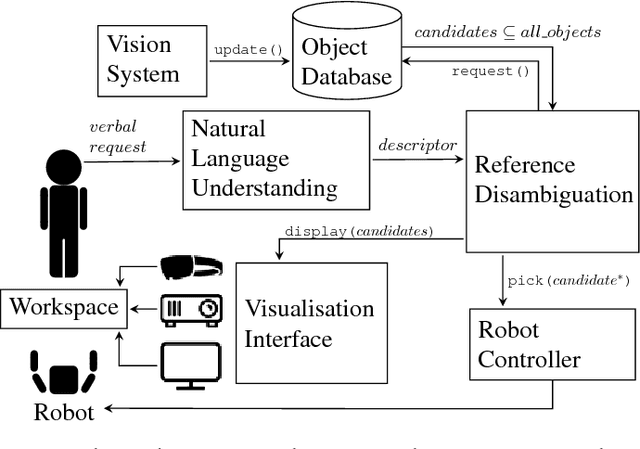

Picking up objects requested by a human user is a common task in human-robot interaction. When multiple objects match the user's verbal description, the robot needs to clarify which object the user is referring to before executing the action. Previous research has focused on perceiving user's multimodal behaviour to complement verbal commands or minimising the number of follow up questions to reduce task time. In this paper, we propose a system for reference disambiguation based on visualisation and compare three methods to disambiguate natural language instructions. In a controlled experiment with a YuMi robot, we investigated real-time augmentations of the workspace in three conditions -- mixed reality, augmented reality, and a monitor as the baseline -- using objective measures such as time and accuracy, and subjective measures like engagement, immersion, and display interference. Significant differences were found in accuracy and engagement between the conditions, but no differences were found in task time. Despite the higher error rates in the mixed reality condition, participants found that modality more engaging than the other two, but overall showed preference for the augmented reality condition over the monitor and mixed reality conditions.