 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Counts as Real? Speech Restoration and Voice Quality Conversion Pose New Challenges to Deepfake Detection
Mar 14, 2026Audio anti-spoofing systems are typically formulated as binary classifiers distinguishing bona fide from spoofed speech. This assumption fails under layered generative processing, where benign transformations introduce distributional shifts that are misclassified as spoofing. We show that phonation-modifying voice conversion and speech restoration are treated as out-of-distribution despite preserving speaker authenticity. Using a multi-class setup separating bona fide, converted, spoofed, and converted-spoofed speech, we analyse model behaviour through self-supervised learning (SSL) embeddings and acoustic correlates. The benign transformations induce a drift in the SSL space, compressing bona fide and spoofed speech and reducing classifier separability. Reformulating anti-spoofing as a multi-class problem improves robustness to benign shifts while preserving spoof detection, suggesting binary systems model the distribution of raw speech rather than authenticity itself.
On the Use of Self-Supervised Speech Representations in Spontaneous Speech Synthesis
Jul 11, 2023Self-supervised learning (SSL) speech representations learned from large amounts of diverse, mixed-quality speech data without transcriptions are gaining ground in many speech technology applications. Prior work has shown that SSL is an effective intermediate representation in two-stage text-to-speech (TTS) for both read and spontaneous speech. However, it is still not clear which SSL and which layer from each SSL model is most suited for spontaneous TTS. We address this shortcoming by extending the scope of comparison for SSL in spontaneous TTS to 6 different SSLs and 3 layers within each SSL. Furthermore, SSL has also shown potential in predicting the mean opinion scores (MOS) of synthesized speech, but this has only been done in read-speech MOS prediction. We extend an SSL-based MOS prediction framework previously developed for scoring read speech synthesis and evaluate its performance on synthesized spontaneous speech. All experiments are conducted twice on two different spontaneous corpora in order to find generalizable trends. Overall, we present comprehensive experimental results on the use of SSL in spontaneous TTS and MOS prediction to further quantify and understand how SSL can be used in spontaneous TTS. Audios samples: https://www.speech.kth.se/tts-demos/sp_ssl_tts
Automatic Evaluation of Turn-taking Cues in Conversational Speech Synthesis
May 29, 2023



Turn-taking is a fundamental aspect of human communication where speakers convey their intention to either hold, or yield, their turn through prosodic cues. Using the recently proposed Voice Activity Projection model, we propose an automatic evaluation approach to measure these aspects for conversational speech synthesis. We investigate the ability of three commercial, and two open-source, Text-To-Speech (TTS) systems ability to generate turn-taking cues over simulated turns. By varying the stimuli, or controlling the prosody, we analyze the models performances. We show that while commercial TTS largely provide appropriate cues, they often produce ambiguous signals, and that further improvements are possible. TTS, trained on read or spontaneous speech, produce strong turn-hold but weak turn-yield cues. We argue that this approach, that focus on functional aspects of interaction, provides a useful addition to other important speech metrics, such as intelligibility and naturalness.
A Comparative Study of Self-Supervised Speech Representations in Read and Spontaneous TTS
Mar 05, 2023Recent work has explored using self-supervised learning (SSL) speech representations such as wav2vec2.0 as the representation medium in standard two-stage TTS, in place of conventionally used mel-spectrograms. It is however unclear which speech SSL is the better fit for TTS, and whether or not the performance differs between read and spontaneous TTS, the later of which is arguably more challenging. This study aims at addressing these questions by testing several speech SSLs, including different layers of the same SSL, in two-stage TTS on both read and spontaneous corpora, while maintaining constant TTS model architecture and training settings. Results from listening tests show that the 9th layer of 12-layer wav2vec2.0 (ASR finetuned) outperforms other tested SSLs and mel-spectrogram, in both read and spontaneous TTS. Our work sheds light on both how speech SSL can readily improve current TTS systems, and how SSLs compare in the challenging generative task of TTS. Audio examples can be found at https://www.speech.kth.se/tts-demos/ssr_tts
Prosody-controllable spontaneous TTS with neural HMMs
Nov 24, 2022Spontaneous speech has many affective and pragmatic functions that are interesting and challenging to model in TTS (text-to-speech). However, the presence of reduced articulation, fillers, repetitions, and other disfluencies mean that text and acoustics are less well aligned than in read speech. This is problematic for attention-based TTS. We propose a TTS architecture that is particularly suited for rapidly learning to speak from irregular and small datasets while also reproducing the diversity of expressive phenomena present in spontaneous speech. Specifically, we modify an existing neural HMM-based TTS system, which is capable of stable, monotonic alignments for spontaneous speech, and add utterance-level prosody control, so that the system can represent the wide range of natural variability in a spontaneous speech corpus. We objectively evaluate control accuracy and perform a subjective listening test to compare to a system without prosody control. To exemplify the power of combining mid-level prosody control and ecologically valid data for reproducing intricate spontaneous speech phenomena, we evaluate the system's capability of synthesizing two types of creaky phonation. Audio samples are available at https://hfkml.github.io/pc_nhmm_tts/
Integrated Speech and Gesture Synthesis
Aug 25, 2021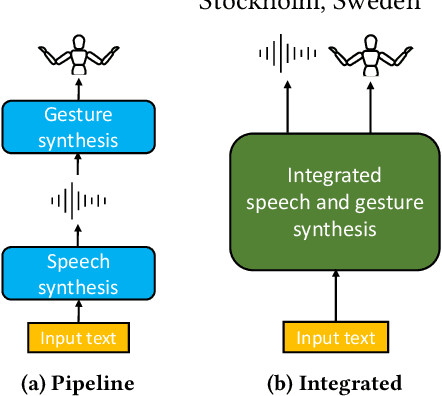

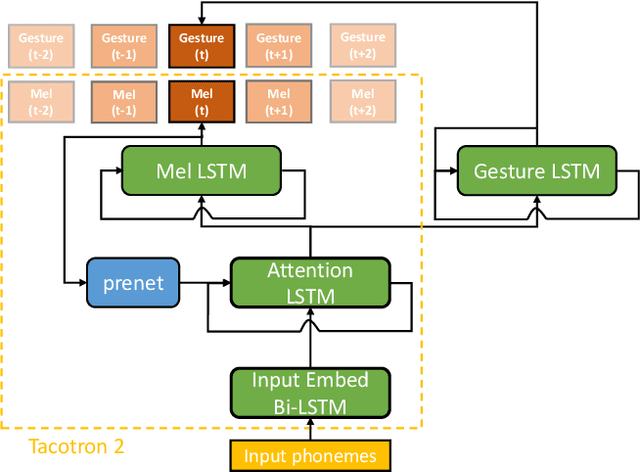
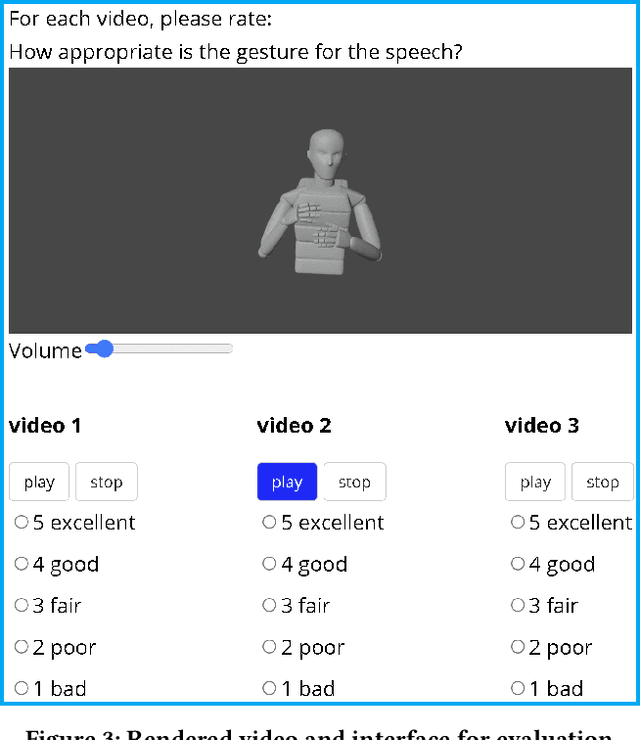
Text-to-speech and co-speech gesture synthesis have until now been treated as separate areas by two different research communities, and applications merely stack the two technologies using a simple system-level pipeline. This can lead to modeling inefficiencies and may introduce inconsistencies that limit the achievable naturalness. We propose to instead synthesize the two modalities in a single model, a new problem we call integrated speech and gesture synthesis (ISG). We also propose a set of models modified from state-of-the-art neural speech-synthesis engines to achieve this goal. We evaluate the models in three carefully-designed user studies, two of which evaluate the synthesized speech and gesture in isolation, plus a combined study that evaluates the models like they will be used in real-world applications -- speech and gesture presented together. The results show that participants rate one of the proposed integrated synthesis models as being as good as the state-of-the-art pipeline system we compare against, in all three tests. The model is able to achieve this with faster synthesis time and greatly reduced parameter count compared to the pipeline system, illustrating some of the potential benefits of treating speech and gesture synthesis together as a single, unified problem. Videos and code are available on our project page at https://swatsw.github.io/isg_icmi21/
A Comparison of Visualisation Methods for Disambiguating Verbal Requests in Human-Robot Interaction
Jan 26, 2018

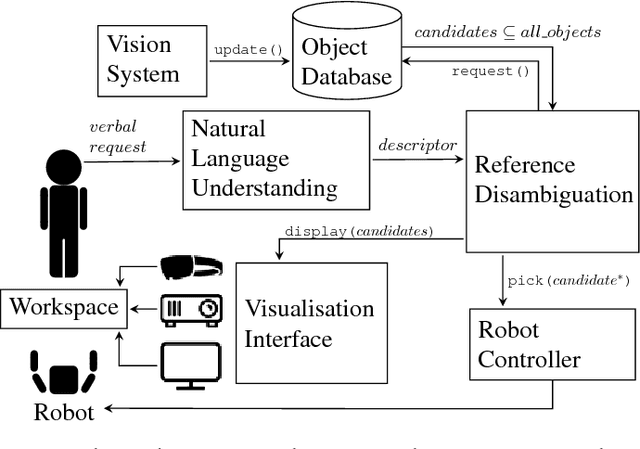

Picking up objects requested by a human user is a common task in human-robot interaction. When multiple objects match the user's verbal description, the robot needs to clarify which object the user is referring to before executing the action. Previous research has focused on perceiving user's multimodal behaviour to complement verbal commands or minimising the number of follow up questions to reduce task time. In this paper, we propose a system for reference disambiguation based on visualisation and compare three methods to disambiguate natural language instructions. In a controlled experiment with a YuMi robot, we investigated real-time augmentations of the workspace in three conditions -- mixed reality, augmented reality, and a monitor as the baseline -- using objective measures such as time and accuracy, and subjective measures like engagement, immersion, and display interference. Significant differences were found in accuracy and engagement between the conditions, but no differences were found in task time. Despite the higher error rates in the mixed reality condition, participants found that modality more engaging than the other two, but overall showed preference for the augmented reality condition over the monitor and mixed reality conditions.
Machine Learning and Social Robotics for Detecting Early Signs of Dementia
Sep 05, 2017
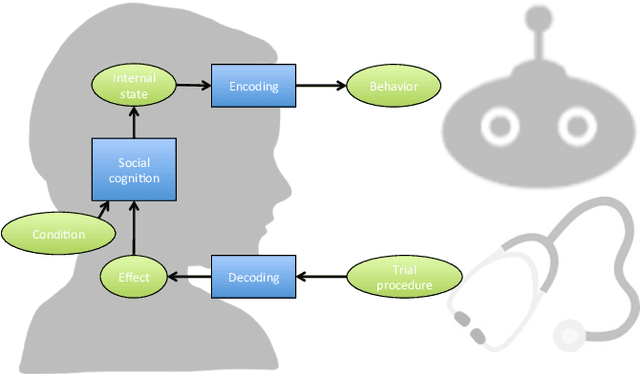
This paper presents the EACare project, an ambitious multi-disciplinary collaboration with the aim to develop an embodied system, capable of carrying out neuropsychological tests to detect early signs of dementia, e.g., due to Alzheimer's disease. The system will use methods from Machine Learning and Social Robotics, and be trained with examples of recorded clinician-patient interactions. The interaction will be developed using a participatory design approach. We describe the scope and method of the project, and report on a first Wizard of Oz prototype.