 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Turn-taking Prediction Using Voice Activity Projection
Mar 14, 2024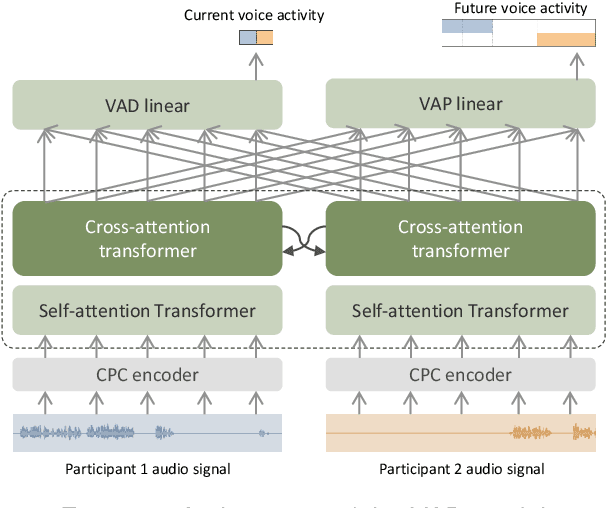
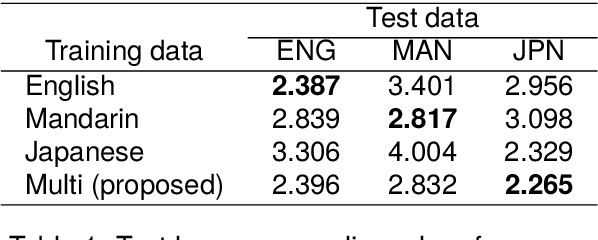
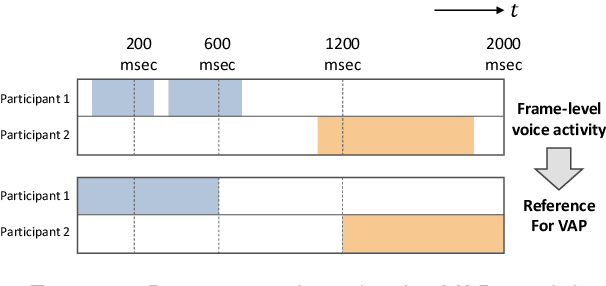
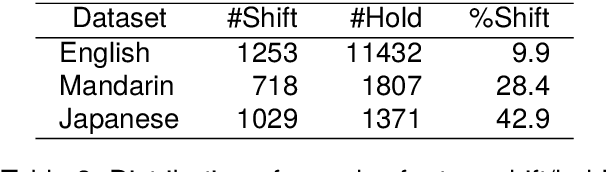
This paper investigates the application of voice activity projection (VAP), a predictive turn-taking model for spoken dialogue, on multilingual data, encompassing English, Mandarin, and Japanese. The VAP model continuously predicts the upcoming voice activities of participants in dyadic dialogue, leveraging a cross-attention Transformer to capture the dynamic interplay between participants. The results show that a monolingual VAP model trained on one language does not make good predictions when applied to other languages. However, a multilingual model, trained on all three languages, demonstrates predictive performance on par with monolingual models across all languages. Further analyses show that the multilingual model has learned to discern the language of the input signal. We also analyze the sensitivity to pitch, a prosodic cue that is thought to be important for turn-taking. Finally, we compare two different audio encoders, contrastive predictive coding (CPC) pre-trained on English, with a recent model based on multilingual wav2vec 2.0 (MMS).
Real-time and Continuous Turn-taking Prediction Using Voice Activity Projection
Jan 10, 2024A demonstration of a real-time and continuous turn-taking prediction system is presented. The system is based on a voice activity projection (VAP) model, which directly maps dialogue stereo audio to future voice activities. The VAP model includes contrastive predictive coding (CPC) and self-attention transformers, followed by a cross-attention transformer. We examine the effect of the input context audio length and demonstrate that the proposed system can operate in real-time with CPU settings, with minimal performance degradation.
Automatic Evaluation of Turn-taking Cues in Conversational Speech Synthesis
May 29, 2023



Turn-taking is a fundamental aspect of human communication where speakers convey their intention to either hold, or yield, their turn through prosodic cues. Using the recently proposed Voice Activity Projection model, we propose an automatic evaluation approach to measure these aspects for conversational speech synthesis. We investigate the ability of three commercial, and two open-source, Text-To-Speech (TTS) systems ability to generate turn-taking cues over simulated turns. By varying the stimuli, or controlling the prosody, we analyze the models performances. We show that while commercial TTS largely provide appropriate cues, they often produce ambiguous signals, and that further improvements are possible. TTS, trained on read or spontaneous speech, produce strong turn-hold but weak turn-yield cues. We argue that this approach, that focus on functional aspects of interaction, provides a useful addition to other important speech metrics, such as intelligibility and naturalness.
Response-conditioned Turn-taking Prediction
May 03, 2023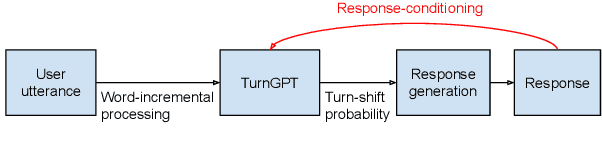
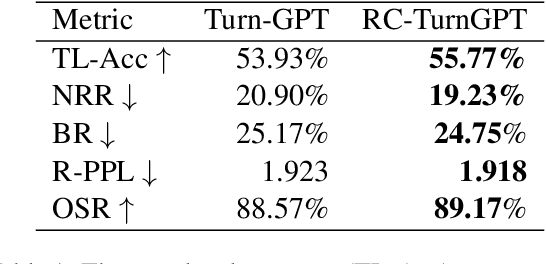
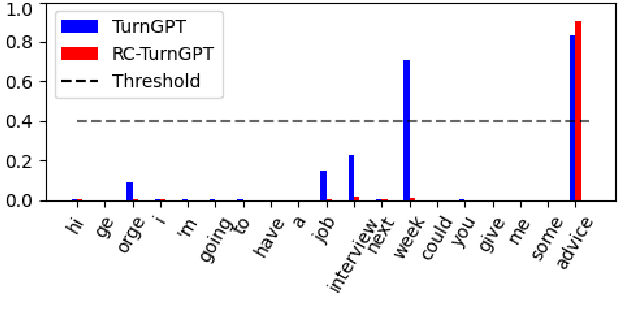

Previous approaches to turn-taking and response generation in conversational systems have treated it as a two-stage process: First, the end of a turn is detected (based on conversation history), then the system generates an appropriate response. Humans, however, do not take the turn just because it is likely, but also consider whether what they want to say fits the position. In this paper, we present a model (an extension of TurnGPT) that conditions the end-of-turn prediction on both conversation history and what the next speaker wants to say. We found that our model consistently outperforms the baseline model in a variety of metrics. The improvement is most prominent in two scenarios where turn predictions can be ambiguous solely from the conversation history: 1) when the current utterance contains a statement followed by a question; 2) when the end of the current utterance semantically matches the response. Treating the turn-prediction and response-ranking as a one-stage process, our findings suggest that our model can be used as an incremental response ranker, which can be applied in various settings.
What makes a good pause? Investigating the turn-holding effects of fillers
May 03, 2023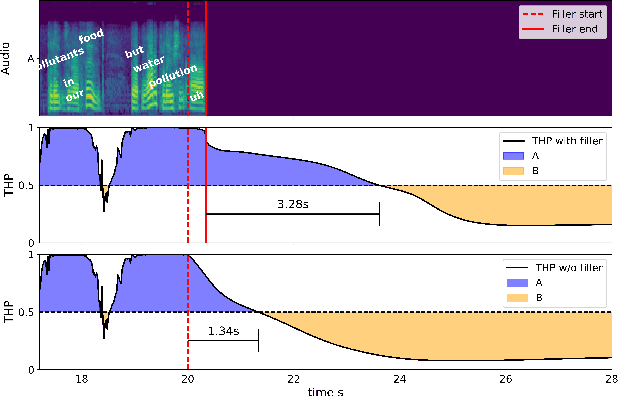
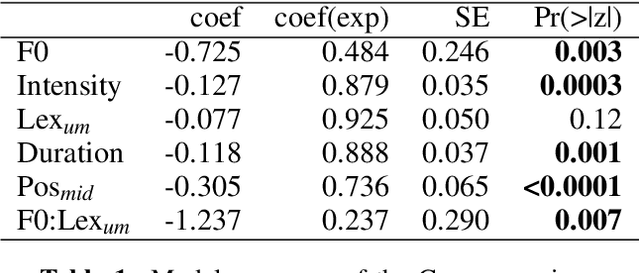
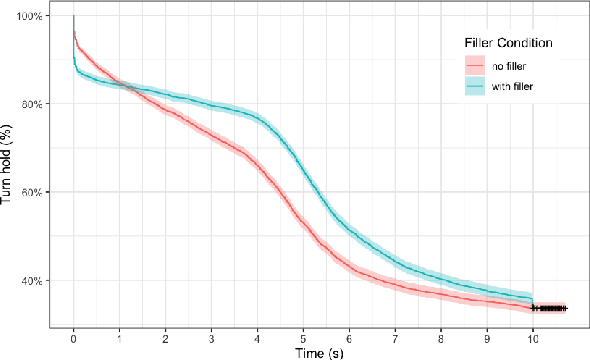
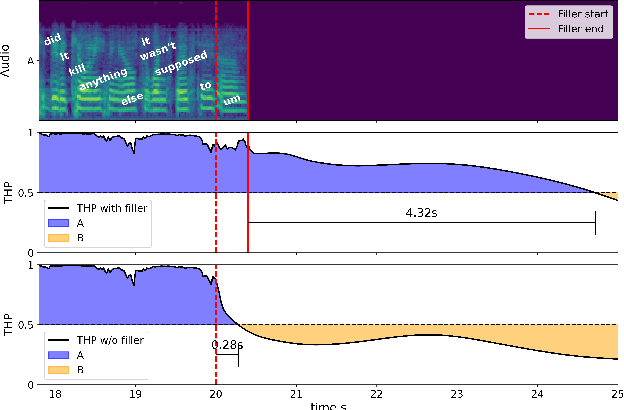
Filled pauses (or fillers), such as "uh" and "um", are frequent in spontaneous speech and can serve as a turn-holding cue for the listener, indicating that the current speaker is not done yet. In this paper, we use the recently proposed Voice Activity Projection (VAP) model, which is a deep learning model trained to predict the dynamics of conversation, to analyse the effects of filled pauses on the expected turn-hold probability. The results show that, while filled pauses do indeed have a turn-holding effect, it is perhaps not as strong as could be expected, probably due to the redundancy of other cues. We also find that the prosodic properties and position of the filler has a significant effect on the turn-hold probability. However, contrary to what has been suggested in previous work, there is no difference between "uh" and "um" in this regard.
How Much Does Prosody Help Turn-taking? Investigations using Voice Activity Projection Models
Sep 12, 2022

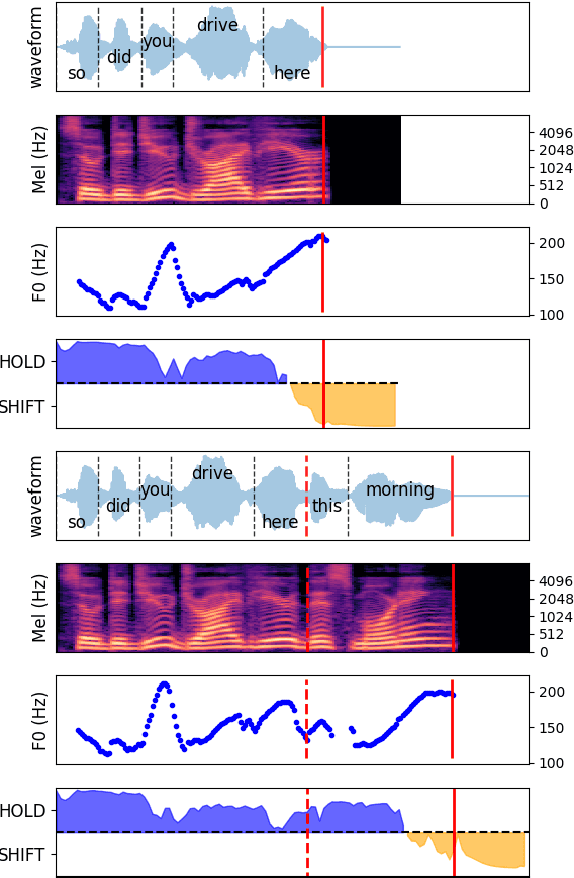

Turn-taking is a fundamental aspect of human communication and can be described as the ability to take turns, project upcoming turn shifts, and supply backchannels at appropriate locations throughout a conversation. In this work, we investigate the role of prosody in turn-taking using the recently proposed Voice Activity Projection model, which incrementally models the upcoming speech activity of the interlocutors in a self-supervised manner, without relying on explicit annotation of turn-taking events, or the explicit modeling of prosodic features. Through manipulation of the speech signal, we investigate how these models implicitly utilize prosodic information. We show that these systems learn to utilize various prosodic aspects of speech both on aggregate quantitative metrics of long-form conversations and on single utterances specifically designed to depend on prosody.
Voice Activity Projection: Self-supervised Learning of Turn-taking Events
May 19, 2022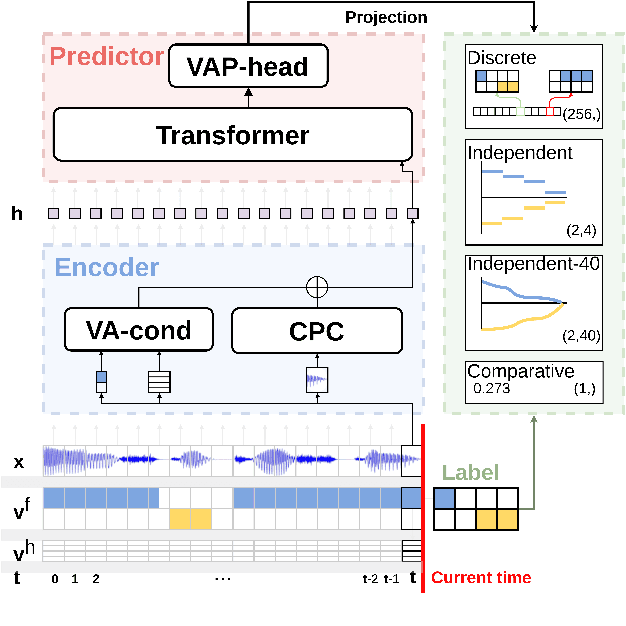

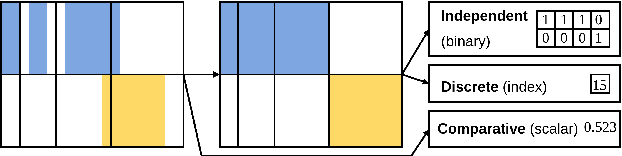

The modeling of turn-taking in dialog can be viewed as the modeling of the dynamics of voice activity of the interlocutors. We extend prior work and define the predictive task of Voice Activity Projection, a general, self-supervised objective, as a way to train turn-taking models without the need of labeled data. We highlight a theoretical weakness with prior approaches, arguing for the need of modeling the dependency of voice activity events in the projection window. We propose four zero-shot tasks, related to the prediction of upcoming turn-shifts and backchannels, and show that the proposed model outperforms prior work.
TurnGPT: a Transformer-based Language Model for Predicting Turn-taking in Spoken Dialog
Oct 21, 2020

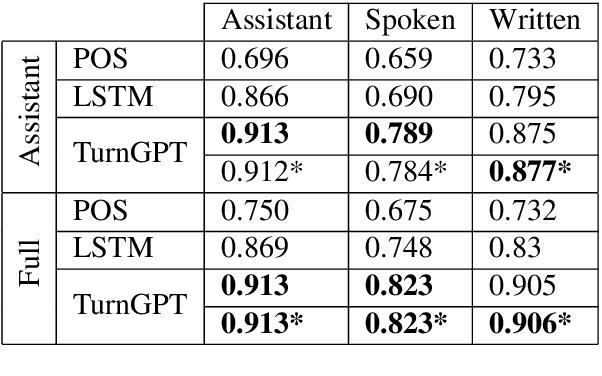
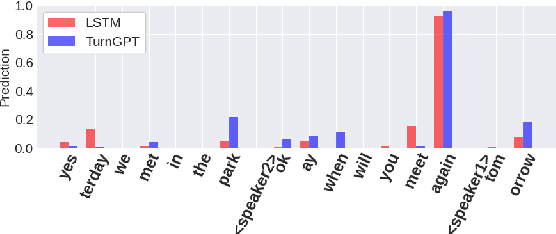
Syntactic and pragmatic completeness is known to be important for turn-taking prediction, but so far machine learning models of turn-taking have used such linguistic information in a limited way. In this paper, we introduce TurnGPT, a transformer-based language model for predicting turn-shifts in spoken dialog. The model has been trained and evaluated on a variety of written and spoken dialog datasets. We show that the model outperforms two baselines used in prior work. We also report on an ablation study, as well as attention and gradient analyses, which show that the model is able to utilize the dialog context and pragmatic completeness for turn-taking prediction. Finally, we explore the model's potential in not only detecting, but also projecting, turn-completions.