 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Sequential to Spatial: Reordering Autoregression for Efficient Visual Generation
Dec 31, 2025Inspired by the remarkable success of autoregressive models in language modeling, this paradigm has been widely adopted in visual generation. However, the sequential token-by-token decoding mechanism inherent in traditional autoregressive models leads to low inference efficiency.In this paper, we propose RadAR, an efficient and parallelizable framework designed to accelerate autoregressive visual generation while preserving its representational capacity. Our approach is motivated by the observation that visual tokens exhibit strong local dependencies and spatial correlations with their neighbors--a property not fully exploited in standard raster-scan decoding orders. Specifically, we organize the generation process around a radial topology: an initial token is selected as the starting point, and all other tokens are systematically grouped into multiple concentric rings according to their spatial distances from this center. Generation then proceeds in a ring-wise manner, from inner to outer regions, enabling the parallel prediction of all tokens within the same ring. This design not only preserves the structural locality and spatial coherence of visual scenes but also substantially increases parallelization. Furthermore, to address the risk of inconsistent predictions arising from simultaneous token generation with limited context, we introduce a nested attention mechanism. This mechanism dynamically refines implausible outputs during the forward pass, thereby mitigating error accumulation and preventing model collapse. By integrating radial parallel prediction with dynamic output correction, RadAR significantly improves generation efficiency.
Towards Context-Aware Human-like Pointing Gestures with RL Motion Imitation
Sep 16, 2025Pointing is a key mode of interaction with robots, yet most prior work has focused on recognition rather than generation. We present a motion capture dataset of human pointing gestures covering diverse styles, handedness, and spatial targets. Using reinforcement learning with motion imitation, we train policies that reproduce human-like pointing while maximizing precision. Results show our approach enables context-aware pointing behaviors in simulation, balancing task performance with natural dynamics.
Learning to Generate Pointing Gestures in Situated Embodied Conversational Agents
Sep 15, 2025

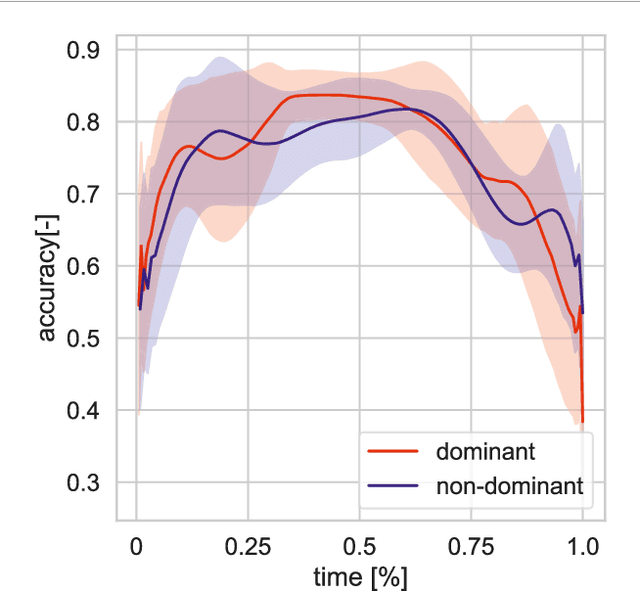

One of the main goals of robotics and intelligent agent research is to enable natural communication with humans in physically situated settings. While recent work has focused on verbal modes such as language and speech, non-verbal communication is crucial for flexible interaction. We present a framework for generating pointing gestures in embodied agents by combining imitation and reinforcement learning. Using a small motion capture dataset, our method learns a motor control policy that produces physically valid, naturalistic gestures with high referential accuracy. We evaluate the approach against supervised learning and retrieval baselines in both objective metrics and a virtual reality referential game with human users. Results show that our system achieves higher naturalness and accuracy than state-of-the-art supervised models, highlighting the promise of imitation-RL for communicative gesture generation and its potential application to robots.
* DOI: 10.3389/frobt.2023.1110534. This is the author's LaTeX version
Varformer: Adapting VAR's Generative Prior for Image Restoration
Dec 30, 2024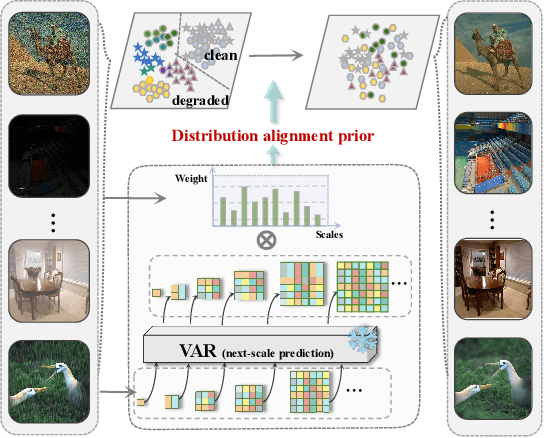
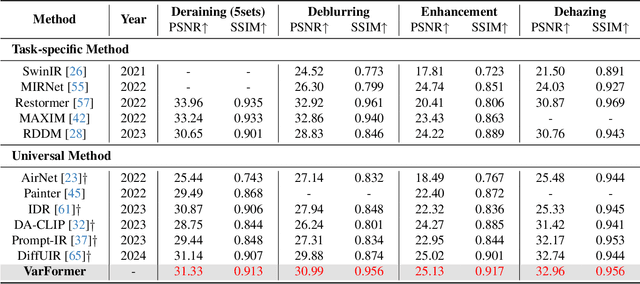
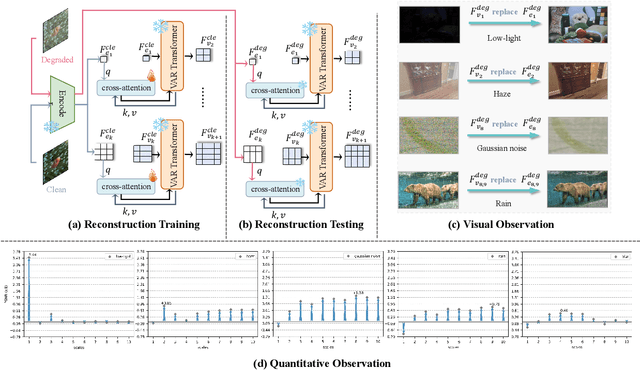
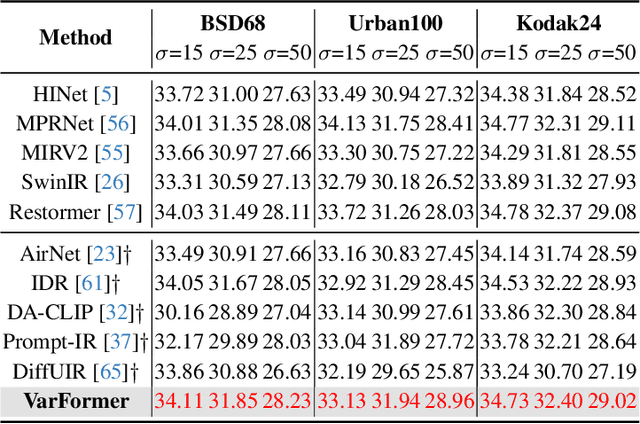
Generative models trained on extensive high-quality datasets effectively capture the structural and statistical properties of clean images, rendering them powerful priors for transforming degraded features into clean ones in image restoration. VAR, a novel image generative paradigm, surpasses diffusion models in generation quality by applying a next-scale prediction approach. It progressively captures both global structures and fine-grained details through the autoregressive process, consistent with the multi-scale restoration principle widely acknowledged in the restoration community. Furthermore, we observe that during the image reconstruction process utilizing VAR, scale predictions automatically modulate the input, facilitating the alignment of representations at subsequent scales with the distribution of clean images. To harness VAR's adaptive distribution alignment capability in image restoration tasks, we formulate the multi-scale latent representations within VAR as the restoration prior, thus advancing our delicately designed VarFormer framework. The strategic application of these priors enables our VarFormer to achieve remarkable generalization on unseen tasks while also reducing training computational costs. Extensive experiments underscores that our VarFormer outperforms existing multi-task image restoration methods across various restoration tasks.
Enhancing Layout Hotspot Detection Efficiency with YOLOv8 and PCA-Guided Augmentation
Jul 19, 2024



In this paper, we present a YOLO-based framework for layout hotspot detection, aiming to enhance the efficiency and performance of the design rule checking (DRC) process. Our approach leverages the YOLOv8 vision model to detect multiple hotspots within each layout image, even when dealing with large layout image sizes. Additionally, to enhance pattern-matching effectiveness, we introduce a novel approach to augment the layout image using information extracted through Principal Component Analysis (PCA). The core of our proposed method is an algorithm that utilizes PCA to extract valuable auxiliary information from the layout image. This extracted information is then incorporated into the layout image as an additional color channel. This augmentation significantly improves the accuracy of multi-hotspot detection while reducing the false alarm rate of the object detection algorithm. We evaluate the effectiveness of our framework using four datasets generated from layouts found in the ICCAD-2019 benchmark dataset. The results demonstrate that our framework achieves a precision (recall) of approximately 83% (86%) while maintaining a false alarm rate of less than 7.4\%. Also, the studies show that the proposed augmentation approach could improve the detection ability of never-seen-before (NSB) hotspots by about 10%.
Evaluating Text-to-Speech Synthesis from a Large Discrete Token-based Speech Language Model
May 16, 2024


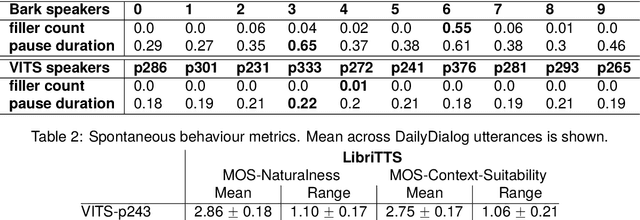
Recent advances in generative language modeling applied to discrete speech tokens presented a new avenue for text-to-speech (TTS) synthesis. These speech language models (SLMs), similarly to their textual counterparts, are scalable, probabilistic, and context-aware. While they can produce diverse and natural outputs, they sometimes face issues such as unintelligibility and the inclusion of non-speech noises or hallucination. As the adoption of this innovative paradigm in speech synthesis increases, there is a clear need for an in-depth evaluation of its capabilities and limitations. In this paper, we evaluate TTS from a discrete token-based SLM, through both automatic metrics and listening tests. We examine five key dimensions: speaking style, intelligibility, speaker consistency, prosodic variation, spontaneous behaviour. Our results highlight the model's strength in generating varied prosody and spontaneous outputs. It is also rated higher in naturalness and context appropriateness in listening tests compared to a conventional TTS. However, the model's performance in intelligibility and speaker consistency lags behind traditional TTS. Additionally, we show that increasing the scale of SLMs offers a modest boost in robustness. Our findings aim to serve as a benchmark for future advancements in generative SLMs for speech synthesis.
On the Use of Self-Supervised Speech Representations in Spontaneous Speech Synthesis
Jul 11, 2023Self-supervised learning (SSL) speech representations learned from large amounts of diverse, mixed-quality speech data without transcriptions are gaining ground in many speech technology applications. Prior work has shown that SSL is an effective intermediate representation in two-stage text-to-speech (TTS) for both read and spontaneous speech. However, it is still not clear which SSL and which layer from each SSL model is most suited for spontaneous TTS. We address this shortcoming by extending the scope of comparison for SSL in spontaneous TTS to 6 different SSLs and 3 layers within each SSL. Furthermore, SSL has also shown potential in predicting the mean opinion scores (MOS) of synthesized speech, but this has only been done in read-speech MOS prediction. We extend an SSL-based MOS prediction framework previously developed for scoring read speech synthesis and evaluate its performance on synthesized spontaneous speech. All experiments are conducted twice on two different spontaneous corpora in order to find generalizable trends. Overall, we present comprehensive experimental results on the use of SSL in spontaneous TTS and MOS prediction to further quantify and understand how SSL can be used in spontaneous TTS. Audios samples: https://www.speech.kth.se/tts-demos/sp_ssl_tts
Diff-TTSG: Denoising probabilistic integrated speech and gesture synthesis
Jun 15, 2023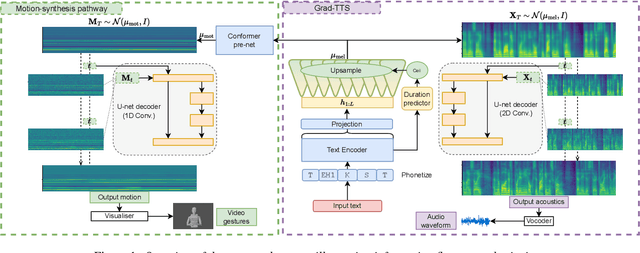

With read-aloud speech synthesis achieving high naturalness scores, there is a growing research interest in synthesising spontaneous speech. However, human spontaneous face-to-face conversation has both spoken and non-verbal aspects (here, co-speech gestures). Only recently has research begun to explore the benefits of jointly synthesising these two modalities in a single system. The previous state of the art used non-probabilistic methods, which fail to capture the variability of human speech and motion, and risk producing oversmoothing artefacts and sub-optimal synthesis quality. We present the first diffusion-based probabilistic model, called Diff-TTSG, that jointly learns to synthesise speech and gestures together. Our method can be trained on small datasets from scratch. Furthermore, we describe a set of careful uni- and multi-modal subjective tests for evaluating integrated speech and gesture synthesis systems, and use them to validate our proposed approach. For synthesised examples please see https://shivammehta25.github.io/Diff-TTSG
Automatic Evaluation of Turn-taking Cues in Conversational Speech Synthesis
May 29, 2023



Turn-taking is a fundamental aspect of human communication where speakers convey their intention to either hold, or yield, their turn through prosodic cues. Using the recently proposed Voice Activity Projection model, we propose an automatic evaluation approach to measure these aspects for conversational speech synthesis. We investigate the ability of three commercial, and two open-source, Text-To-Speech (TTS) systems ability to generate turn-taking cues over simulated turns. By varying the stimuli, or controlling the prosody, we analyze the models performances. We show that while commercial TTS largely provide appropriate cues, they often produce ambiguous signals, and that further improvements are possible. TTS, trained on read or spontaneous speech, produce strong turn-hold but weak turn-yield cues. We argue that this approach, that focus on functional aspects of interaction, provides a useful addition to other important speech metrics, such as intelligibility and naturalness.
A Comparative Study of Self-Supervised Speech Representations in Read and Spontaneous TTS
Mar 05, 2023Recent work has explored using self-supervised learning (SSL) speech representations such as wav2vec2.0 as the representation medium in standard two-stage TTS, in place of conventionally used mel-spectrograms. It is however unclear which speech SSL is the better fit for TTS, and whether or not the performance differs between read and spontaneous TTS, the later of which is arguably more challenging. This study aims at addressing these questions by testing several speech SSLs, including different layers of the same SSL, in two-stage TTS on both read and spontaneous corpora, while maintaining constant TTS model architecture and training settings. Results from listening tests show that the 9th layer of 12-layer wav2vec2.0 (ASR finetuned) outperforms other tested SSLs and mel-spectrogram, in both read and spontaneous TTS. Our work sheds light on both how speech SSL can readily improve current TTS systems, and how SSLs compare in the challenging generative task of TTS. Audio examples can be found at https://www.speech.kth.se/tts-demos/ssr_tts