 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention is all you need for Videos: Self-attention based Video Summarization using Universal Transformers
Paper and Code

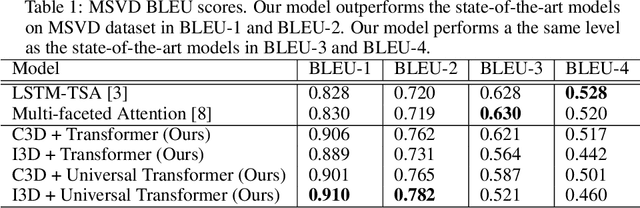
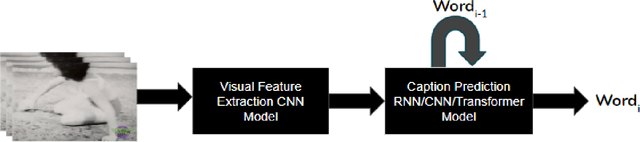

Video Captioning and Summarization have become very popular in the recent years due to advancements in Sequence Modelling, with the resurgence of Long-Short Term Memory networks (LSTMs) and introduction of Gated Recurrent Units (GRUs). Existing architectures extract spatio-temporal features using CNNs and utilize either GRUs or LSTMs to model dependencies with soft attention layers. These attention layers do help in attending to the most prominent features and improve upon the recurrent units, however, these models suffer from the inherent drawbacks of the recurrent units themselves. The introduction of the Transformer model has driven the Sequence Modelling field into a new direction. In this project, we implement a Transformer-based model for Video captioning, utilizing 3D CNN architectures like C3D and Two-stream I3D for video extraction. We also apply certain dimensionality reduction techniques so as to keep the overall size of the model within limits. We finally present our results on the MSVD and ActivityNet datasets for Single and Dense video captioning tasks respectively.