 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRubiCap: Rubric-Guided Reinforcement Learning for Dense Image Captioning
Mar 10, 2026Dense image captioning is critical for cross-modal alignment in vision-language pretraining and text-to-image generation, but scaling expert-quality annotations is prohibitively expensive. While synthetic captioning via strong vision-language models (VLMs) is a practical alternative, supervised distillation often yields limited output diversity and weak generalization. Reinforcement learning (RL) could overcome these limitations, but its successes have so far been concentrated in verifiable domains that rely on deterministic checkers -- a luxury not available in open-ended captioning. We address this bottleneck with RubiCap, a novel RL framework that derives fine-grained, sample-specific reward signals from LLM-written rubrics. RubiCap first assembles a diverse committee of candidate captions, then employs an LLM rubric writer to extract consensus strengths and diagnose deficiencies in the current policy. These insights are converted into explicit evaluation criteria, enabling an LLM judge to decompose holistic quality assessment and replace coarse scalar rewards with structured, multi-faceted evaluations. Across extensive benchmarks, RubiCap achieves the highest win rates on CapArena, outperforming supervised distillation, prior RL methods, human-expert annotations, and GPT-4V-augmented outputs. On CaptionQA, it demonstrates superior word efficiency: our 7B model matches Qwen2.5-VL-32B-Instruct, and our 3B model surpasses its 7B counterpart. Remarkably, using the compact RubiCap-3B as a captioner produces stronger pretrained VLMs than those trained on captions from proprietary models.
Evaluating Sample Utility for Data Selection by Mimicking Model Weights
Jan 12, 2025



Foundation models rely on large-scale web-crawled datasets, which frequently contain noisy data, biases, and irrelevant content. Existing data selection techniques typically use human heuristics, downstream evaluation datasets, or specialized scoring models, and can overlook samples' utility in the training process. Instead, we propose a new approach, Mimic Score, a data quality metric that uses a pretrained reference model as a guide to assess the usefulness of data samples for training a new model. It relies on the alignment between the gradient of the new model parameters and the vector pointing toward the reference model in weight space. Samples that misalign with this direction are considered low-value and can be filtered out. Motivated by the Mimic score, we develop Grad-Mimic, a data selection framework that identifies and prioritizes useful samples, automating the selection process to create effective filters. Empirically, using Mimic scores to guide model training results in consistent performance gains across six image datasets and enhances the performance of CLIP models. Moreover, Mimic scores and their associated filters improve upon existing filtering methods and offer accurate estimation of dataset quality.
Probabilistic Attention for Interactive Segmentation
Jul 02, 2021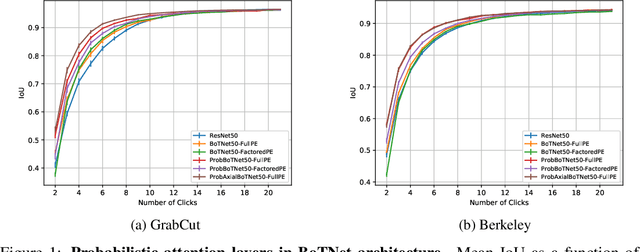
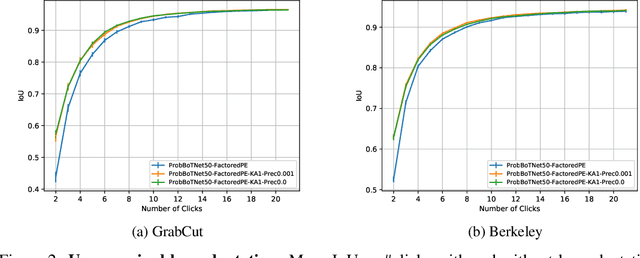
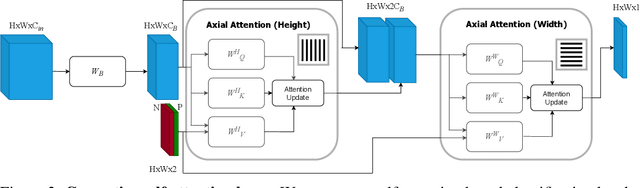
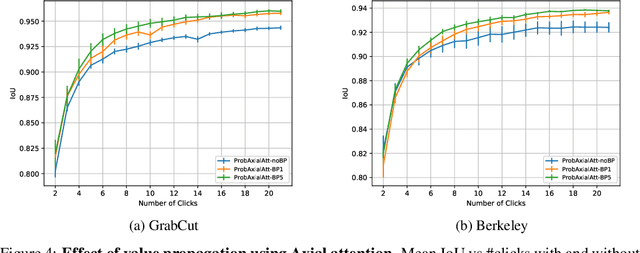
We provide a probabilistic interpretation of attention and show that the standard dot-product attention in transformers is a special case of Maximum A Posteriori (MAP) inference. The proposed approach suggests the use of Expectation Maximization algorithms for online adaptation of key and value model parameters. This approach is useful for cases in which external agents, e.g., annotators, provide inference-time information about the correct values of some tokens, e.g, the semantic category of some pixels, and we need for this new information to propagate to other tokens in a principled manner. We illustrate the approach on an interactive semantic segmentation task in which annotators and models collaborate online to improve annotation efficiency. Using standard benchmarks, we observe that key adaptation boosts model performance ($\sim10\%$ mIoU) in the low feedback regime and value propagation improves model responsiveness in the high feedback regime. A PyTorch layer implementation of our probabilistic attention model will be made publicly available here: https://github.com/apple/ml-probabilistic-attention.
Attention is all you need for Videos: Self-attention based Video Summarization using Universal Transformers
Jun 06, 2019
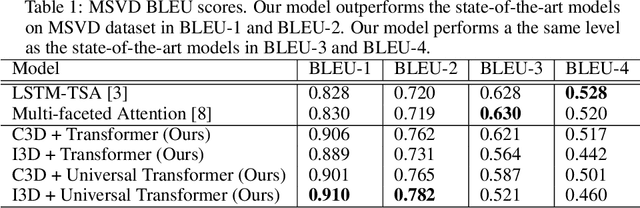

Video Captioning and Summarization have become very popular in the recent years due to advancements in Sequence Modelling, with the resurgence of Long-Short Term Memory networks (LSTMs) and introduction of Gated Recurrent Units (GRUs). Existing architectures extract spatio-temporal features using CNNs and utilize either GRUs or LSTMs to model dependencies with soft attention layers. These attention layers do help in attending to the most prominent features and improve upon the recurrent units, however, these models suffer from the inherent drawbacks of the recurrent units themselves. The introduction of the Transformer model has driven the Sequence Modelling field into a new direction. In this project, we implement a Transformer-based model for Video captioning, utilizing 3D CNN architectures like C3D and Two-stream I3D for video extraction. We also apply certain dimensionality reduction techniques so as to keep the overall size of the model within limits. We finally present our results on the MSVD and ActivityNet datasets for Single and Dense video captioning tasks respectively.
Human Activity Recognition for Edge Devices
Mar 18, 2019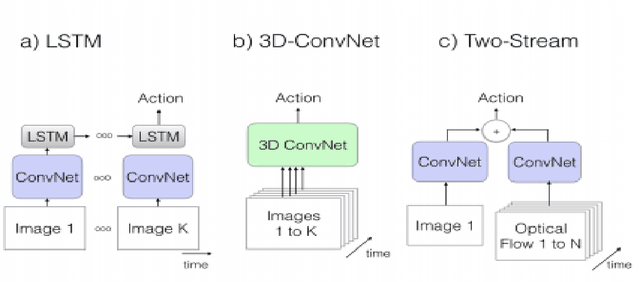

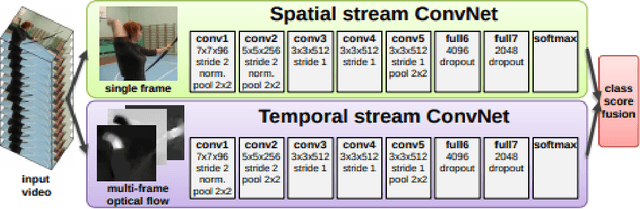

Video activity Recognition has recently gained a lot of momentum with the release of massive Kinetics (400 and 600) data. Architectures such as I3D and C3D networks have shown state-of-the-art performances for activity recognition. The one major pitfall with these state-of-the-art networks is that they require a lot of compute. In this paper we explore how we can achieve comparable results to these state-of-the-art networks for devices-on-edge. We primarily explore two architectures - I3D and Temporal Segment Network. We show that comparable results can be achieved using one tenth the memory usage by changing the testing procedure. We also report our results on Resnet architecture as our backbone apart from the original Inception architecture. Specifically, we achieve 84.54\% top-1 accuracy on UCF-101 dataset using only RGB frames.