 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRubiCap: Rubric-Guided Reinforcement Learning for Dense Image Captioning
Mar 10, 2026Dense image captioning is critical for cross-modal alignment in vision-language pretraining and text-to-image generation, but scaling expert-quality annotations is prohibitively expensive. While synthetic captioning via strong vision-language models (VLMs) is a practical alternative, supervised distillation often yields limited output diversity and weak generalization. Reinforcement learning (RL) could overcome these limitations, but its successes have so far been concentrated in verifiable domains that rely on deterministic checkers -- a luxury not available in open-ended captioning. We address this bottleneck with RubiCap, a novel RL framework that derives fine-grained, sample-specific reward signals from LLM-written rubrics. RubiCap first assembles a diverse committee of candidate captions, then employs an LLM rubric writer to extract consensus strengths and diagnose deficiencies in the current policy. These insights are converted into explicit evaluation criteria, enabling an LLM judge to decompose holistic quality assessment and replace coarse scalar rewards with structured, multi-faceted evaluations. Across extensive benchmarks, RubiCap achieves the highest win rates on CapArena, outperforming supervised distillation, prior RL methods, human-expert annotations, and GPT-4V-augmented outputs. On CaptionQA, it demonstrates superior word efficiency: our 7B model matches Qwen2.5-VL-32B-Instruct, and our 3B model surpasses its 7B counterpart. Remarkably, using the compact RubiCap-3B as a captioner produces stronger pretrained VLMs than those trained on captions from proprietary models.
Evaluating Sample Utility for Data Selection by Mimicking Model Weights
Jan 12, 2025



Foundation models rely on large-scale web-crawled datasets, which frequently contain noisy data, biases, and irrelevant content. Existing data selection techniques typically use human heuristics, downstream evaluation datasets, or specialized scoring models, and can overlook samples' utility in the training process. Instead, we propose a new approach, Mimic Score, a data quality metric that uses a pretrained reference model as a guide to assess the usefulness of data samples for training a new model. It relies on the alignment between the gradient of the new model parameters and the vector pointing toward the reference model in weight space. Samples that misalign with this direction are considered low-value and can be filtered out. Motivated by the Mimic score, we develop Grad-Mimic, a data selection framework that identifies and prioritizes useful samples, automating the selection process to create effective filters. Empirically, using Mimic scores to guide model training results in consistent performance gains across six image datasets and enhances the performance of CLIP models. Moreover, Mimic scores and their associated filters improve upon existing filtering methods and offer accurate estimation of dataset quality.
Probabilistic Attention for Interactive Segmentation
Jul 02, 2021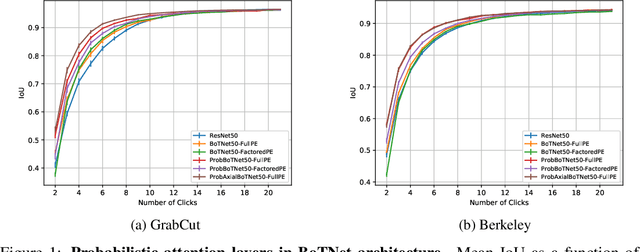
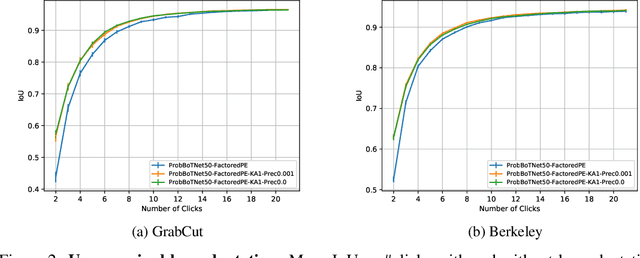
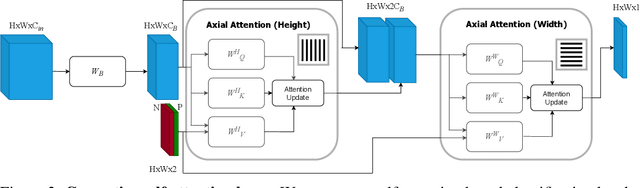
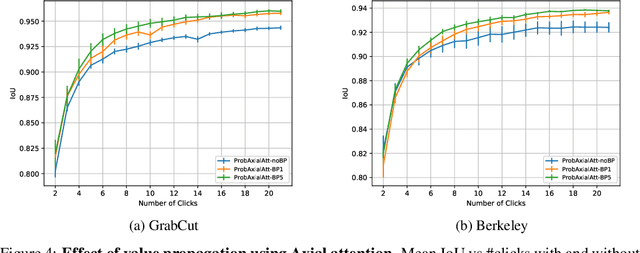
We provide a probabilistic interpretation of attention and show that the standard dot-product attention in transformers is a special case of Maximum A Posteriori (MAP) inference. The proposed approach suggests the use of Expectation Maximization algorithms for online adaptation of key and value model parameters. This approach is useful for cases in which external agents, e.g., annotators, provide inference-time information about the correct values of some tokens, e.g, the semantic category of some pixels, and we need for this new information to propagate to other tokens in a principled manner. We illustrate the approach on an interactive semantic segmentation task in which annotators and models collaborate online to improve annotation efficiency. Using standard benchmarks, we observe that key adaptation boosts model performance ($\sim10\%$ mIoU) in the low feedback regime and value propagation improves model responsiveness in the high feedback regime. A PyTorch layer implementation of our probabilistic attention model will be made publicly available here: https://github.com/apple/ml-probabilistic-attention.
Discriminately Decreasing Discriminability with Learned Image Filters
Oct 04, 2011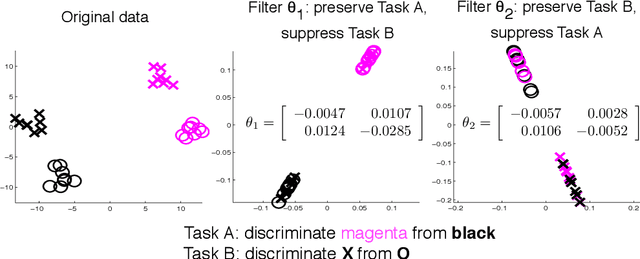
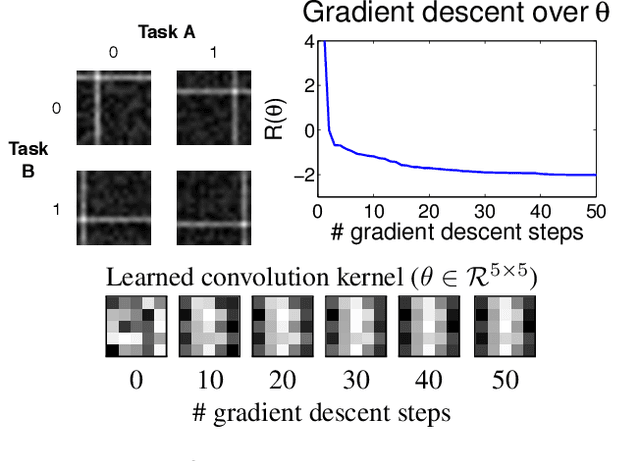


In machine learning and computer vision, input images are often filtered to increase data discriminability. In some situations, however, one may wish to purposely decrease discriminability of one classification task (a "distractor" task), while simultaneously preserving information relevant to another (the task-of-interest): For example, it may be important to mask the identity of persons contained in face images before submitting them to a crowdsourcing site (e.g., Mechanical Turk) when labeling them for certain facial attributes. Another example is inter-dataset generalization: when training on a dataset with a particular covariance structure among multiple attributes, it may be useful to suppress one attribute while preserving another so that a trained classifier does not learn spurious correlations between attributes. In this paper we present an algorithm that finds optimal filters to give high discriminability to one task while simultaneously giving low discriminability to a distractor task. We present results showing the effectiveness of the proposed technique on both simulated data and natural face images.